Elasticsearch索引的精髓
一切设计都是为了提高搜索的性能
为了提高搜索的性能,难免会牺牲某些其他方面,比如插入/更新,否则其他数据库不用混了。往Elasticsearch里插入一条记录,其实就是直接PUT一个json的对象,这个对象有多个fields,比如name, sex, age, about, interests,那么在插入这些数据到Elasticsearch的同时,Elasticsearch还默默1的为这些字段建立索引--倒排索引,因为Elasticsearch最核心功能是搜索。
Elasticsearch是如何做到快速索引的
Elasticsearch使用的倒排索引比关系型数据库的B-Tree索引快,为什么呢?
二叉树查找效率是logN,同时插入新的节点不必移动全部节点,所以用树型结构存储索引,能同时兼顾插入和查询的性能。因此在这个基础上,再结合磁盘的读取特性(顺序读/随机读),传统关系型数据库采用了B-Tree/B+Tree这样的数据结构:
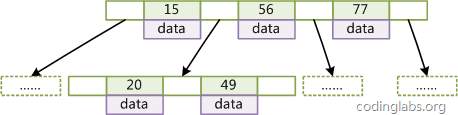
为了提高查询的效率,减少磁盘寻道次数,将多个值作为一个数组通过连续区间存放,一次寻道读取多个数据,同时也降低树的高度。