本期内容 :
- UpdateStateByKey解密
- MapWithState解密
Spark Streaming是实现State状态管理因素:
01、 Spark Streaming是按照整个BachDuration划分Job的,每个BachDuration都会产生一个Job,为了符合业务操作的需求,
需要计算过去一个小时或者一周的数据,但是由于数据量大于BachDuration,此时不可避免的需要进行状态维护
02、 Spark 的状态管理其实有很多函数,比较典型的有类似的UpdateStateByKey、MapWithState方法来完成核心的步骤
一、 UPdateStateByKey :
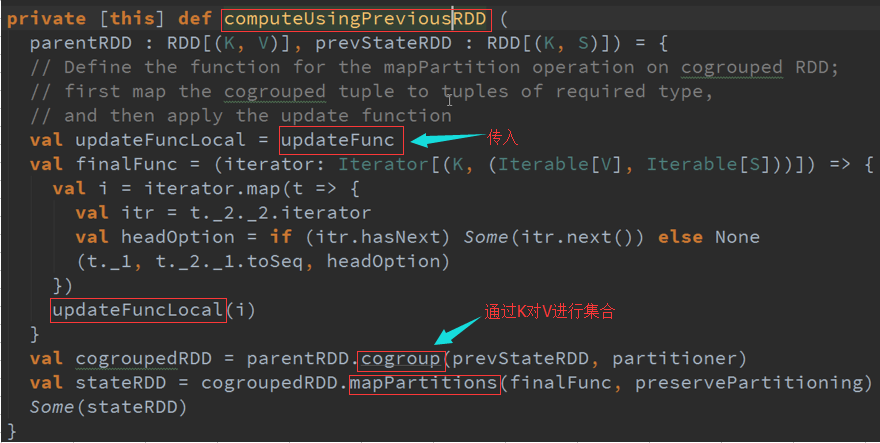
在已有历史数据中的状态进行更新,具体怎么更新就取决于UPdateFunc函数进行操作,返回一个DSteam类型
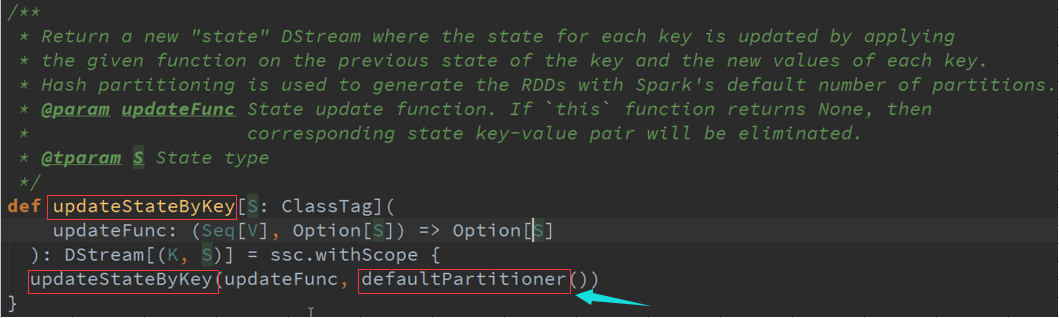
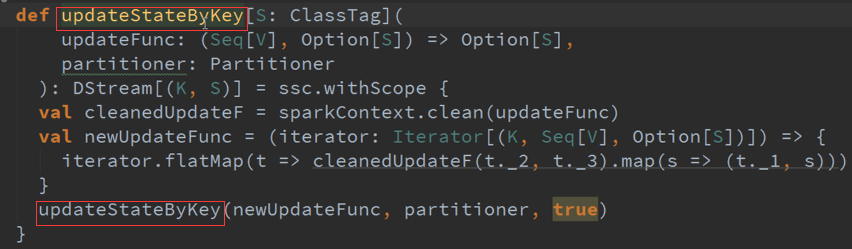

最终还是使用DSteam操作的,会不断的产生数据
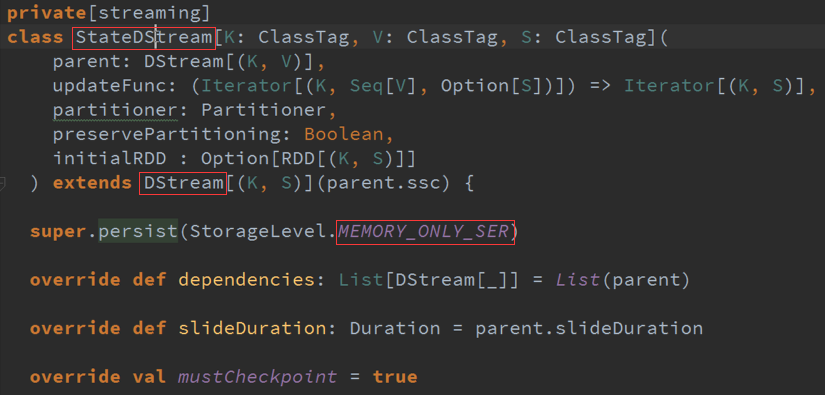
生成RDD的过程,计算方法
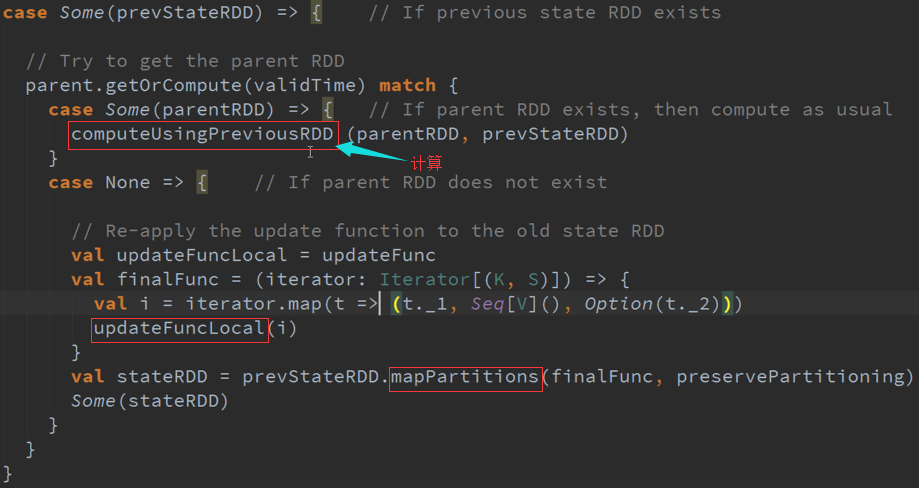
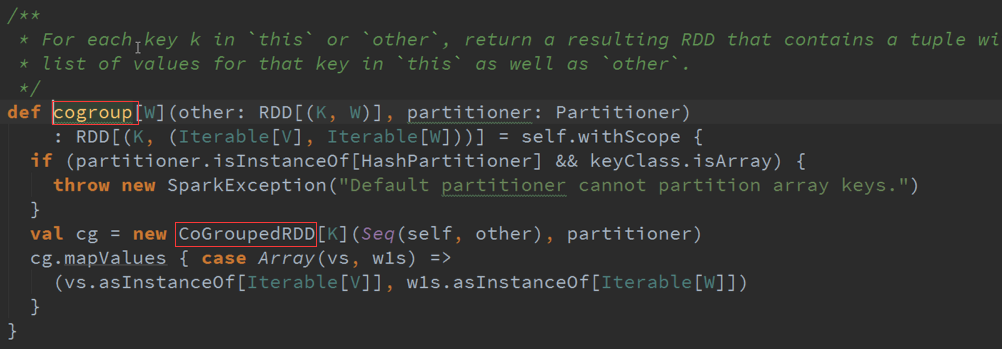
对传入的数据,通过K对所有数据进行集合:
优点: 每次都需要对RDD进行计算,确实需要对RDD进行计算,RDD怎么算,就对其进行Cogroup
缺点: 性能问题,因为需要每一次都要对所有数据进行扫描,最终变成CogroupedRDD,随着数据量的增加速度也越慢
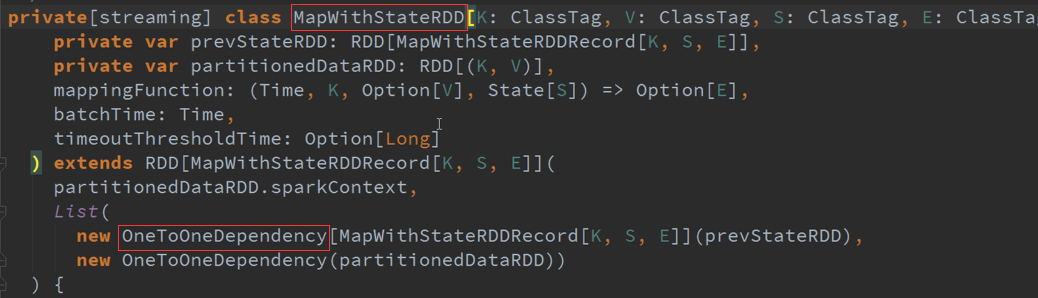
二、 MapWithState :

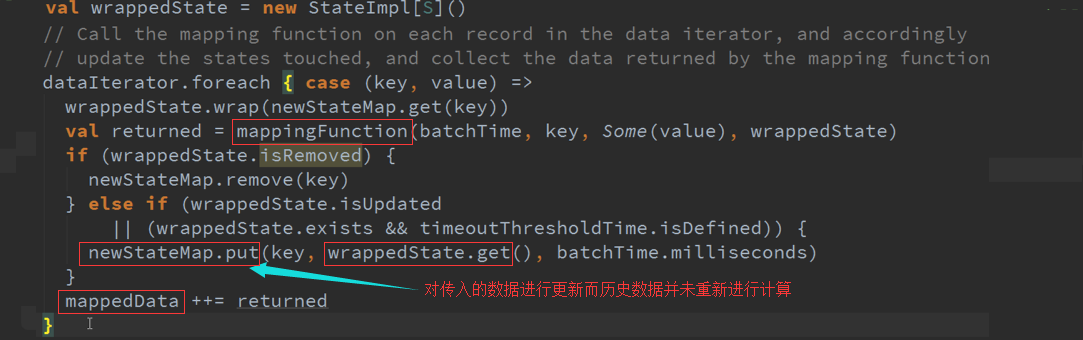
返回的是DStreams的时候,进行状态更新与维护历史状态是基于K进行的,具体更新的函数、超时时间、初始状态等都是由StateSpec(封装了更新函数)进行获取、
更新、删除,相当于记录在一张表中,对表中的哪个Key进行操作使用历史数据,State是表名称或者索引,获取、更新数据,维护状态。
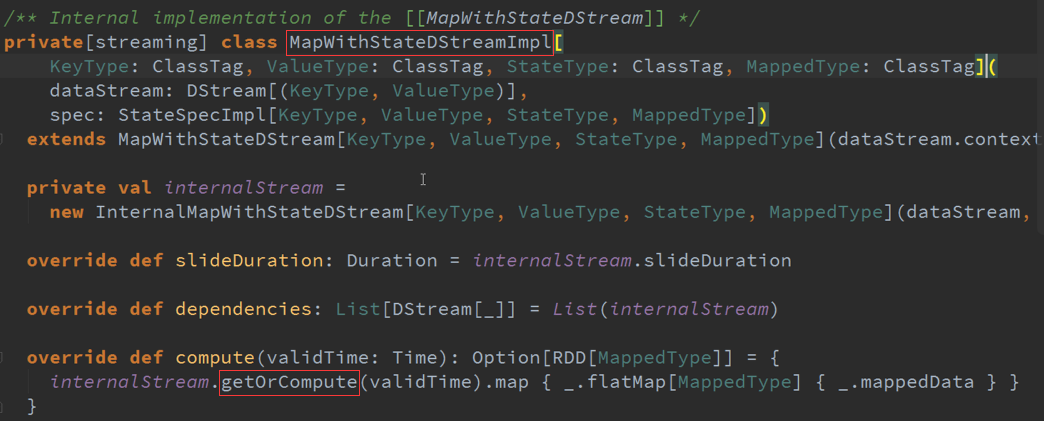
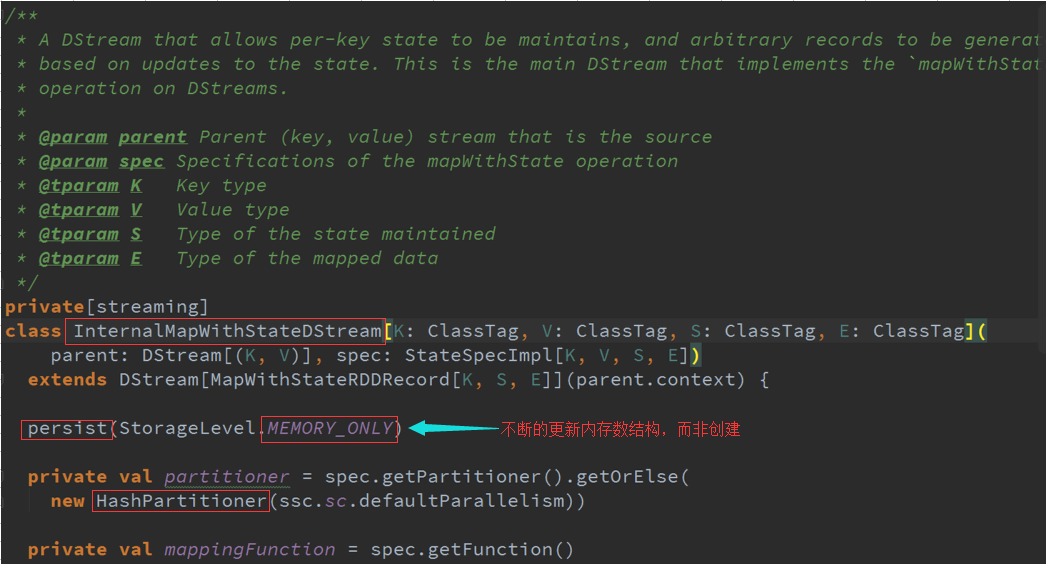

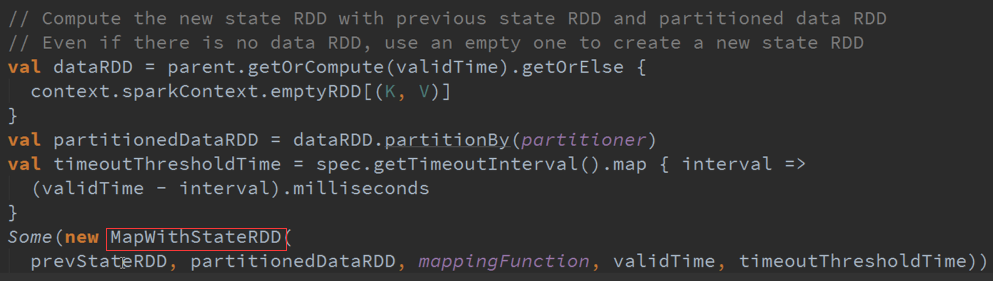
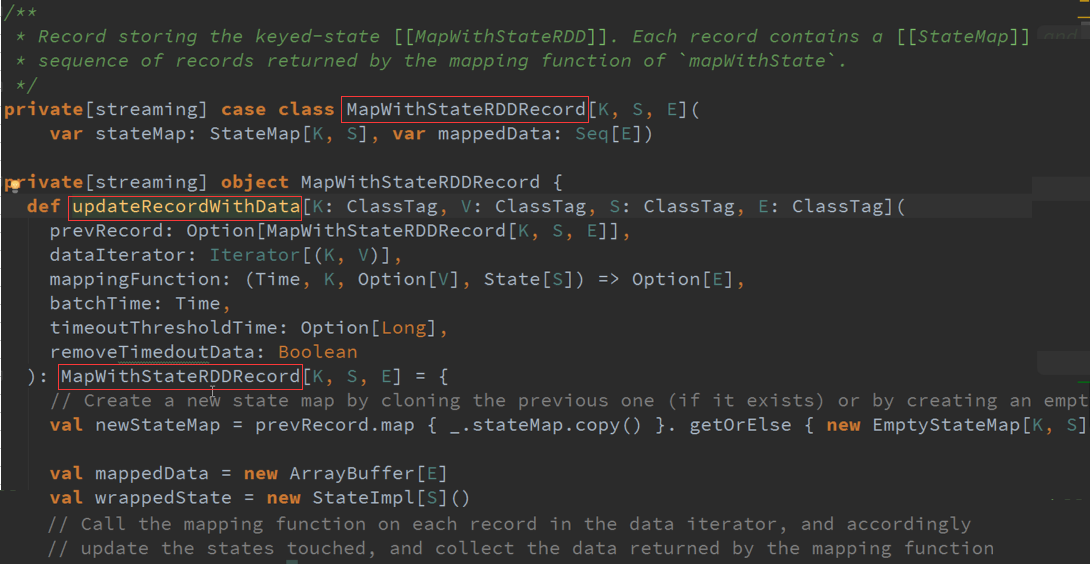
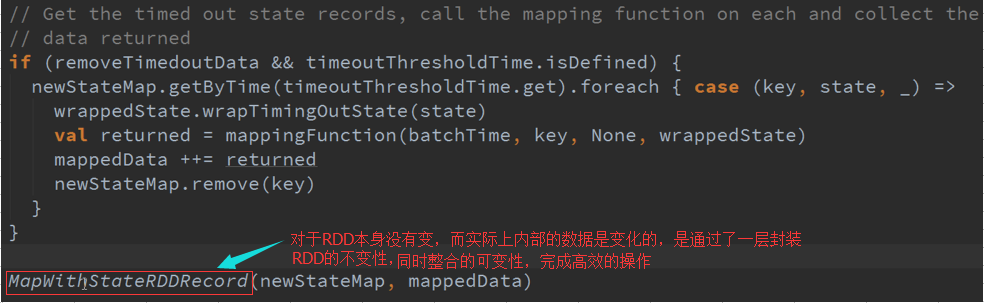
所有的Partition都是由MapWithStateRDDRecord所代表的,数据结构是StateMap ,维护的是基于K的状态