本期内容 :
- Executor的WAL
- 消息重放
数据安全的角度来考虑整个Spark Streaming :
1、 Spark Streaming会不断次序的接收数据并不断的产生Job ,不断的提交Job到集群运行,至关重要的问题接收数据安全性
2、 由于Spark Streaming是基于Spark Core基础之上的,即是说运行过程中出现错误或者故障,Spark Streaming也可以借助
Spark Core中RDD的容错的能力自动的进行恢复,恢复的前提是数据的安全可靠。
所以Executor接收数据时的安全容错至关重要,在这个数据的安全容错的基础之上进行调度级别的容错基本靠Spark Core,
对于Executor的安全容错主要是数据的安全容错,计算的时候Spark Streaming是借助于Spark Core上的RDD的容错。
数据的安全容错:
1、 最天然的安全容错是副本,处理数据的时候先复制一个副本
2、接收数据时不使用副本,数据源支持重放,可以反复读取数据,如读取过去10S中的数据,出现错误可以再次读取过去10S中的数据
一、 Executor的WAL
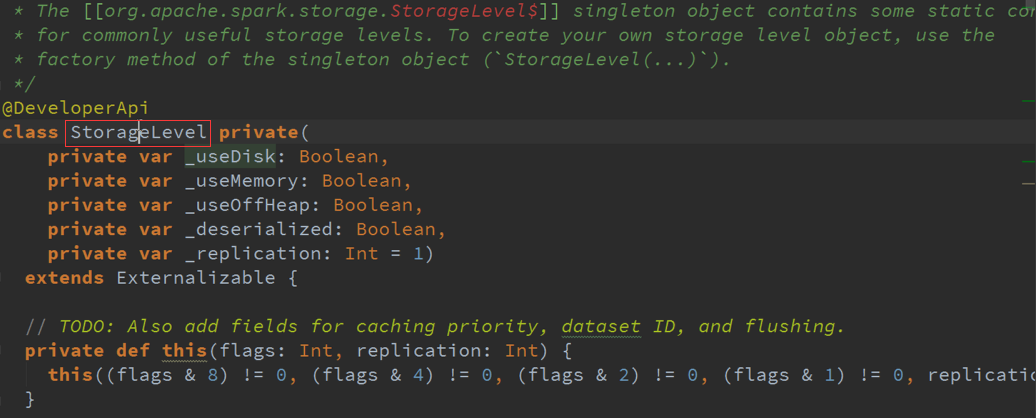
Spark Core的BlockManager负责具体Executor上的数据读写操作,并且也是个MsteaStorageLevel的结构
借助Spark底层的存储系统BlockManager做备份的StorageLevel 。
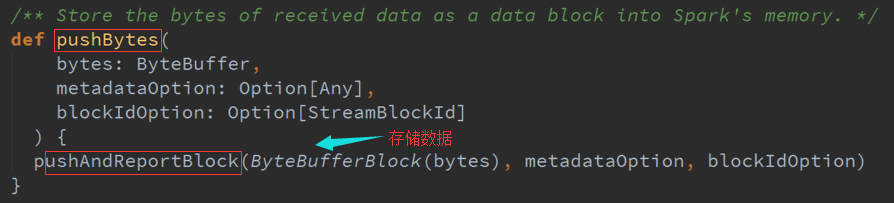

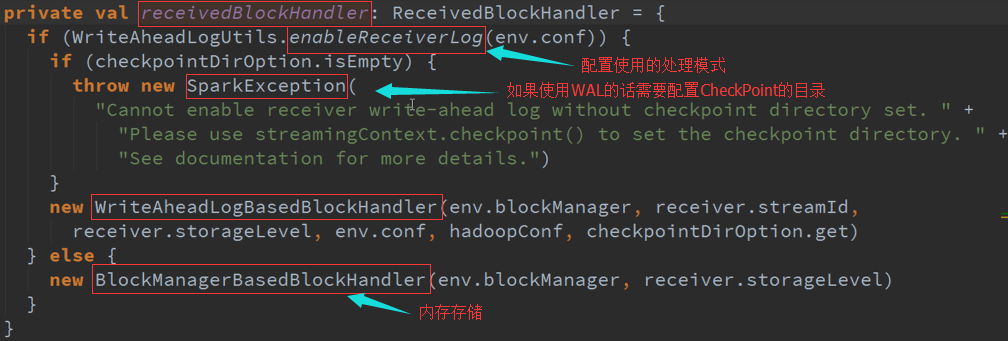

1、BlockManagerBasedBlockHandler 副本机制



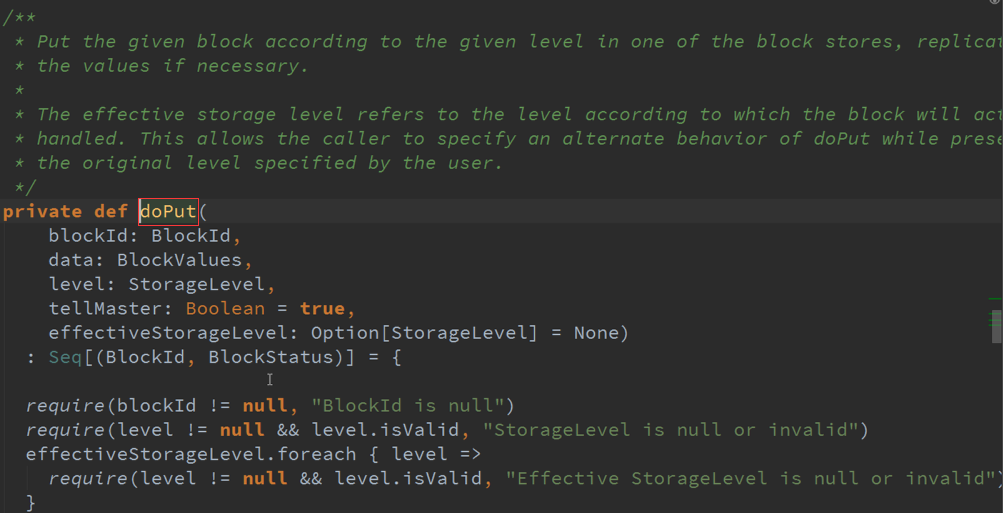
2、 WriteAheadLogBasedBlockHandler WAL日志方式
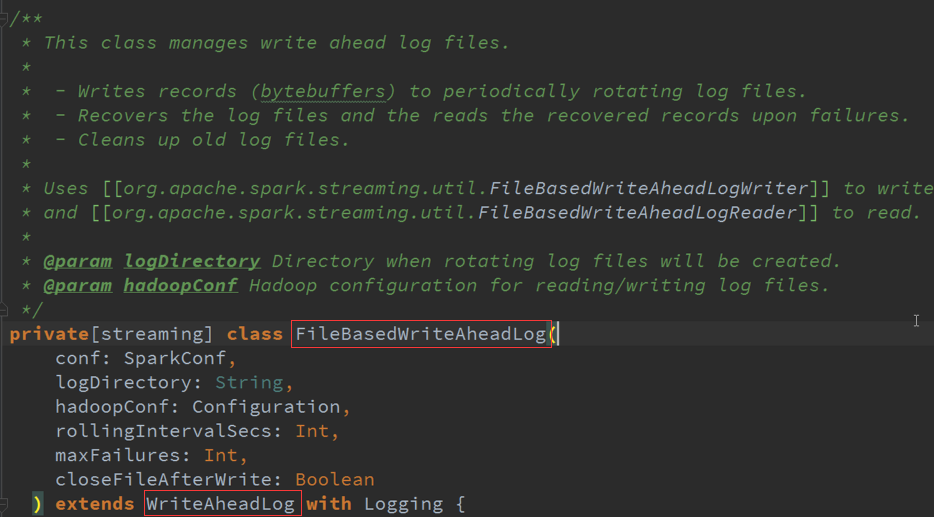
在其具体目录下会做一份日志,后续处理过程中出现问题可以基于日志恢复,日志需要写在目录下:
需要先设置写在CheckPoint的目录,目录可以有很多目录: StreamingContext.CheckPoint 在上下文中指定具体目录,
一般情况下会放在HDFS中,优势是安全,多份副本,缺点是影响性能,浪费存储空间 。



同时在WAL及BlockManager中放数据:

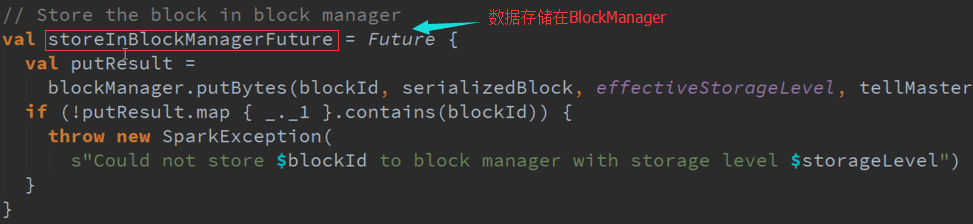


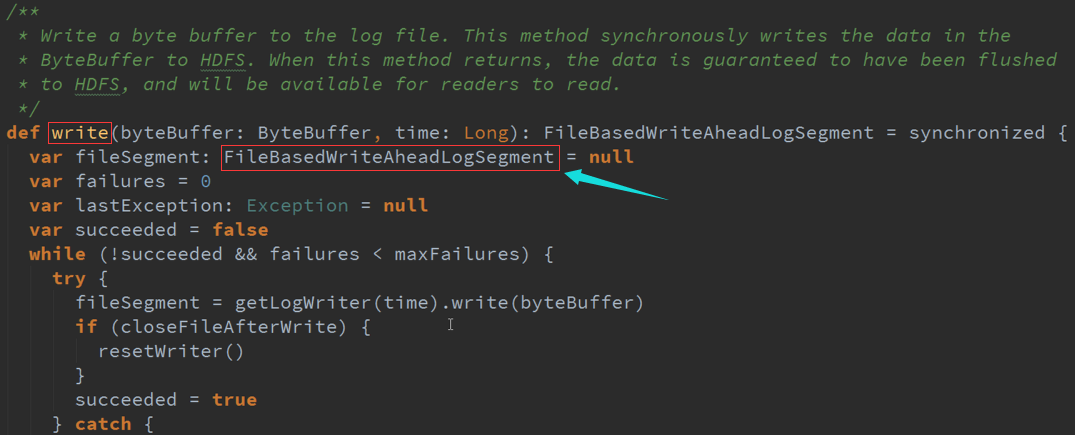
Executor写数据时是按照顺序的写,由于是做WAL使用不会修改数据,一般是根据索引读取,不需要全盘搜索所以读取速度非常快。
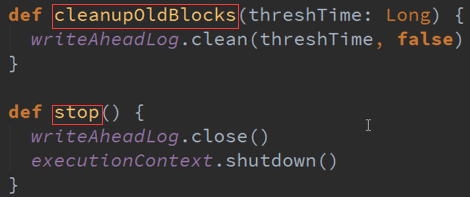
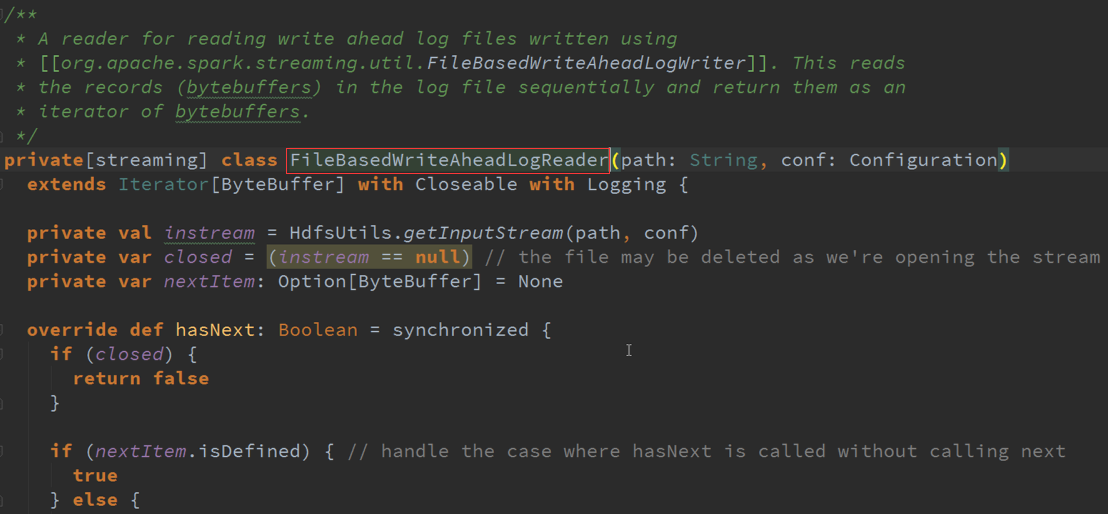
3. 具体的实现 :管理具体的WAL文件,周期性的写文件,输出时写文件,清理旧文件


备份存储总结 :
1、 基于BlockManager ,比如说两台机器中都有数据,其中一台出错了就切换到另外一台
2、 WAL方式,WAL方式比较耗时,假如你对性能要求非常苛刻的话WAL一般不是一个很好的选择,如果你能够容忍1分钟以上的延迟的话WAL往往比较安全
注意: 如果还没有来得及进行WAL的话数据可能也会丢失。
二、 支持消息重放 :
主要基于Kafka,天然就是有副本与容错的,已经作为一个存储系统了。
Kafka有Receiver的方式,Direct的方式 :
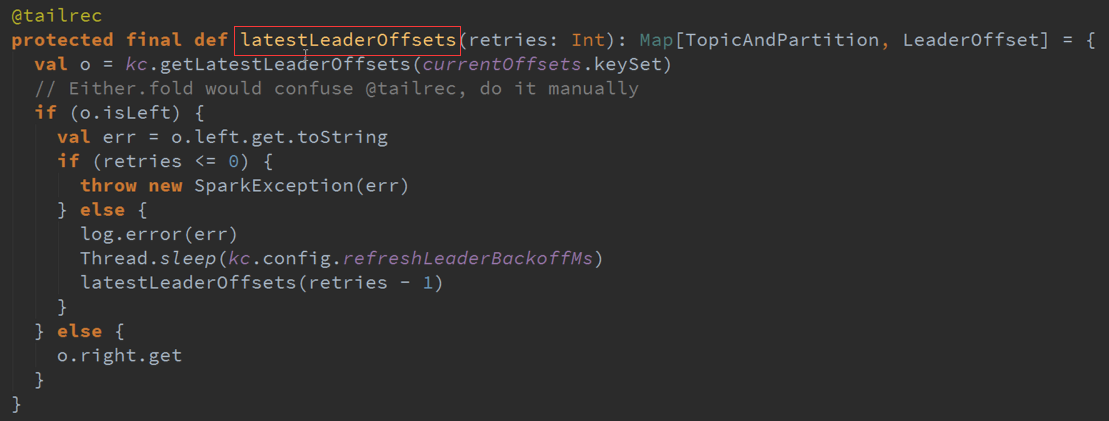
1、Receiver方式:是交给zookeeper管理的Mtdata的偏移量的如果失效后Kafka会基于Offset重新的读取,如果你读取失败此时不会给zookeeper发送ACK信号,
zookeeper就让我你并没有消费这个数据,这个是zookeeper保证的,还有个数据重复消费的问题,就是消费完了但是还没有来得及给zookeeper进行同步,可能会重复。
2、Direct方式:直接去操作Kafka ,而且是自己管理Offset ,Kafka本身就有Offset ,这种方式可以确保有且一次的操作处理,这个需要进行CheckPoint操作,较耗时间。
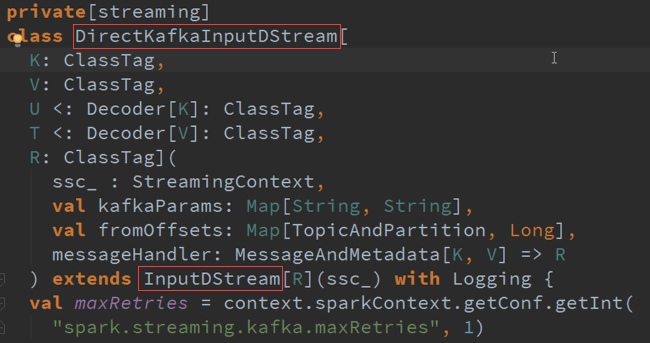
管理这个Offset ,Bach会调用这个方法,上次的Offset减去这次的值就可以确定此次Offset的范围数据。