本期内容 :
- JobScheduler内幕实现
- JobScheduler深度思考
JobScheduler 是整个Spark Streaming调度的核心,需要设置多线程,一条用于接收数据不断的循环,另外一条是处理线程,同时需要把调度与执行分离开。
一、 作业流程源码 :
首先只要定义了BatchDuration后就规定了按照什么样的频率生成具体的Job ,也就是Job生成的频率:

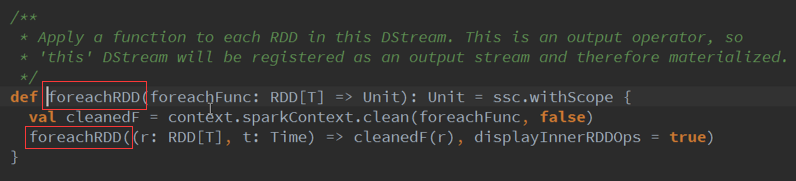
按照一定的频率操作ForeachRDD :
我们设置每隔5秒钟都会生成一个Spark 的Job ,Job其实其内部是存在依赖关系的,当遇到时间维度的时候就变成物理级别的。
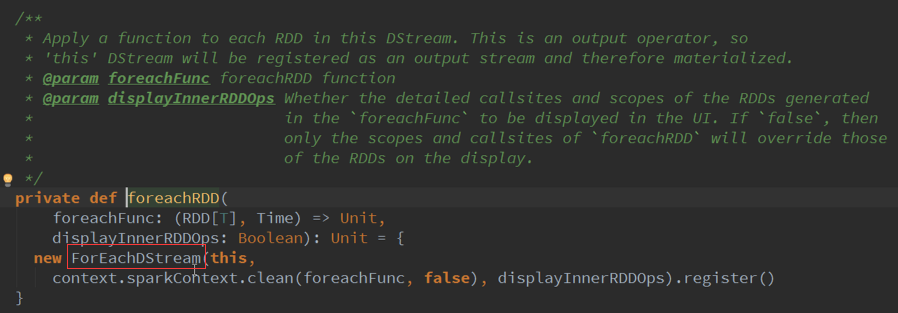
指定的两条线程,说明具体在集群中需要的线程数据,一条用于接收数据不断的循环,另外一条是处理线程。

启动的新线程,是调度层面的,而应用程序是自己配置,需要把调度与执行分离开,每个线程都有自己的属性:

Spark Streaming源码中默认的是一个线程数 :

进行实例化过程

Job调度本身与需要实现的业务逻辑


二、 调度流程源码 :
JobGenerator有三大核心 :
1. JobGenerator本身
2. JobGenerator任意生成Job
3. ReceiverTracker整个数据的控制与生成者
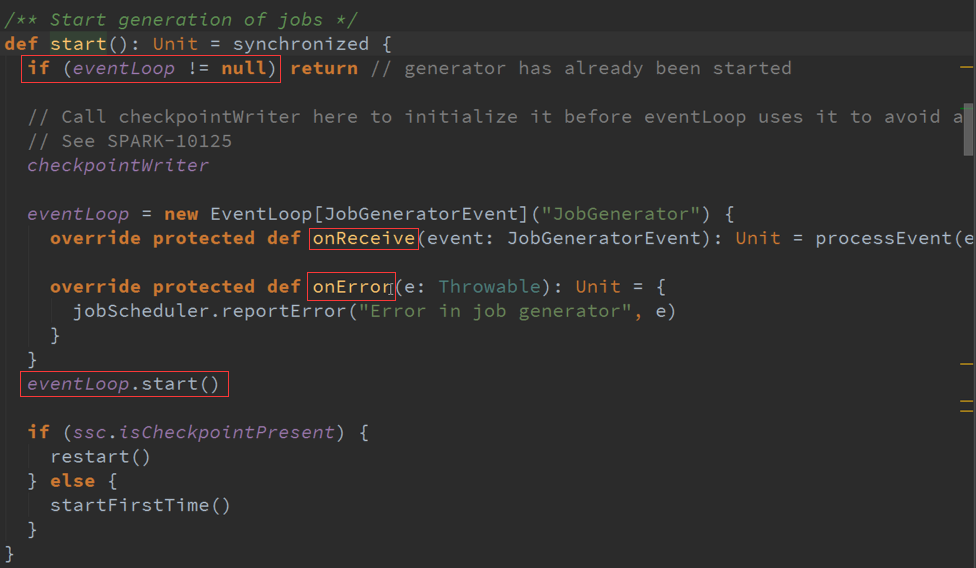
时间维度加Action级别,就是根据generateJob来生成作业
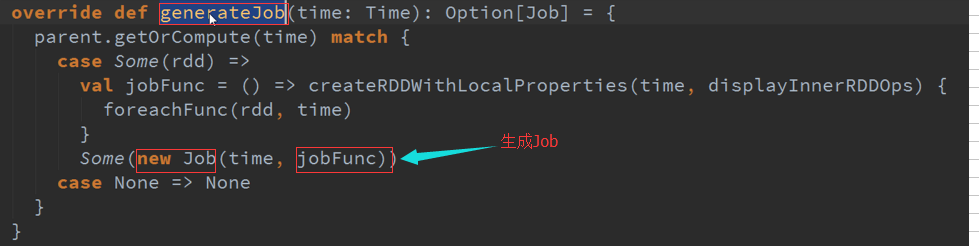
业务代码逻辑级别与空间级别、静态,真正运行起来变成物理级别就需要JobGeneratorEvent


从时间维度去调用空间维度的内容,就生成了现实的内容(物理级别的)

将每个Job放入线程池中,为了配合线程池使用了JobHandler


开始处理业务逻辑部分
