本期内容 :
- Spark Streaming+Spark SQL案例展示
- 基于案例贯穿Spark Streaming的运行源码
一、 案例代码阐述 :
在线动态计算电商中不同类别中最热门的商品排名,例如:手机类别中最热门的三种手机、电视类别中最热门的三种电视等。
1、案例运行代码 :
import org.apache.spark.SparkConf import org.apache.spark.sql.Row import org.apache.spark.sql.hive.HiveContext import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType} import org.apache.spark.streaming.{Seconds, StreamingContext} object OnlineTheTop3ItemForEachCategory2DB { def main(args: Array[String]){ /**
* * 第1步:创建Spark的配置对象SparkConf,设置Spark程序的运行时的配置信息, */ val conf = new SparkConf() //创建SparkConf对象 conf.setAppName("OnlineTheTop3ItemForEachCategory2DB") //设置应用程序的名称,在程序运行的监控界面可以看到名称 //conf.setMaster("spark://Master:7077") //此时,程序在Spark集群 conf.setMaster("local[6]") //设置batchDuration时间间隔来控制Job生成的频率并且创建Spark Streaming执行的入口 val ssc = new StreamingContext(conf, Seconds(5)) ssc.checkpoint("/root/Documents/SparkApps/checkpoint") val userClickLogsDStream = ssc.socketTextStream("Master", 9999) val formattedUserClickLogsDStream = userClickLogsDStream.map(clickLog => (clickLog.split(" ")(2) + "_" + clickLog.split(" ")(1), 1)) //val categoryUserClickLogsDStream = formattedUserClickLogsDStream.reduceByKeyAndWindow((v1:Int, v2: Int) => v1 + v2, //(v1:Int, v2: Int) => v1 - v2, Seconds(60), Seconds(20)) val categoryUserClickLogsDStream = formattedUserClickLogsDStream.reduceByKeyAndWindow(_+_, _-_, Seconds(60), Seconds(20)) categoryUserClickLogsDStream.foreachRDD { rdd => { if (rdd.isEmpty()) { println("No data inputted!!!") } else { val categoryItemRow = rdd.map(reducedItem => { val category = reducedItem._1.split("_")(0) val item = reducedItem._1.split("_")(1) val click_count = reducedItem._2 Row(category, item, click_count) }) val structType = StructType(Array( StructField("category", StringType, true), StructField("item", StringType, true), StructField("click_count", IntegerType, true) )) val hiveContext = new HiveContext(rdd.context) val categoryItemDF = hiveContext.createDataFrame(categoryItemRow, structType) categoryItemDF.registerTempTable("categoryItemTable") val reseltDataFram = hiveContext.sql("SELECT category,item,click_count FROM (SELECT category,item,click_count,row_number()" + " OVER (PARTITION BY category ORDER BY click_count DESC) rank FROM categoryItemTable) subquery " + " WHERE rank <= 3") reseltDataFram.show() val resultRowRDD = reseltDataFram.rdd resultRowRDD.foreachPartition { partitionOfRecords => { if (partitionOfRecords.isEmpty){ println("This RDD is not null but partition is null") } else { // ConnectionPool is a static, lazily initialized pool of connections val connection = ConnectionPool.getConnection() partitionOfRecords.foreach(record => { val sql = "insert into categorytop3(category,item,client_count) values('" + record.getAs("category") + "','" + record.getAs("item") + "'," + record.getAs("click_count") + ")" val stmt = connection.createStatement(); stmt.executeUpdate(sql); }) ConnectionPool.returnConnection(connection) // return to the pool for future reuse } } } } } ssc.start() ssc.awaitTermination() } }
}
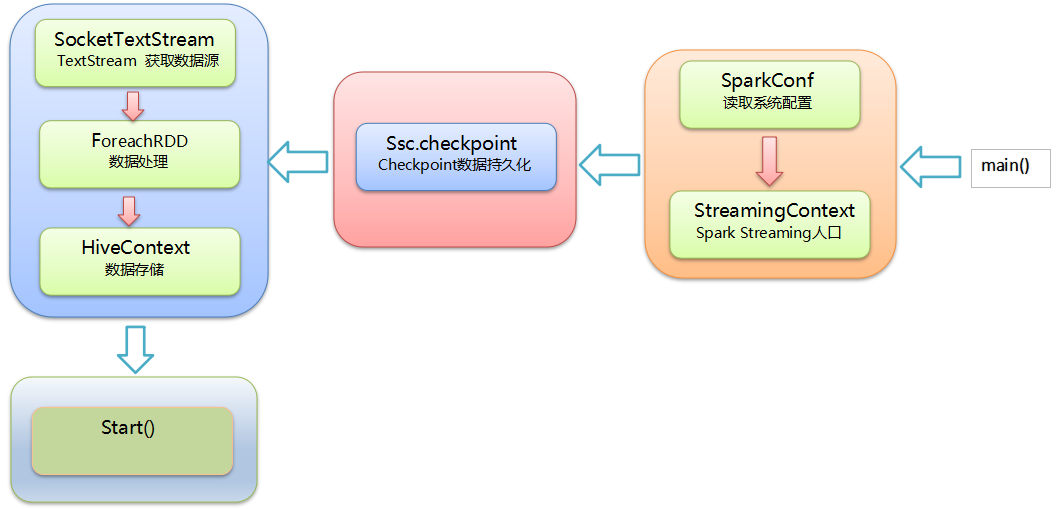
2、案例流程框架图 :
二、 基于案例的源码解析 :
1、 构建Spark的配置对象SparkConf,设置Spark程序的运行时的配置信息:

2、构建StreamingContext时传递SparkConf参数在内部创建SparkContext :


3、创建了 StreamingContext : 同时说明Spark Streaming 是Spark Core上的一个应用程序

4、 checkpoint 持久化
5、构建SocketTextStream 获取输入源

01、 创建Socket 获取输入流

02、 SocketInputDstream继承ReceiverInputDStream,通过构建Receiver来接收数据



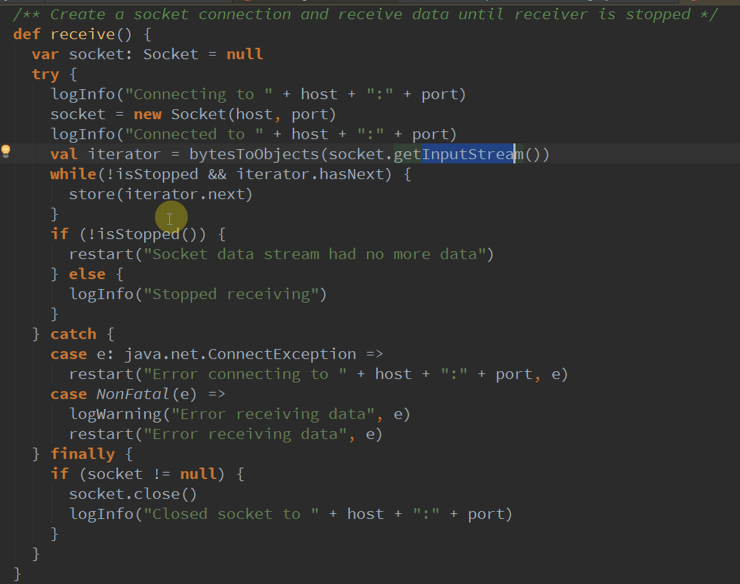
03、 创建SocketReceiver

04、 通过Receiver 在网络获取相关数据
05、数据输出

06、生成job作业

07、 根据时间间隔产生RDD ,存储数据


6、 Streaming Start :

7、 流程总结 :
01、 在StreamingContext调用start方法的内部其实是会启动JobScheduler的Start方法,进行消息循环。
02、 在JobScheduler的start内部会构造JobGenerator和ReceiverTacker,并且调用JobGenerator和ReceiverTacker的start方法:
-
-
- JobGenerator启动后会不断的根据batchDuration生成一个个的Job ;
- ReceiverTracker启动后首先在Spark Cluster中启动Receiver (其实是在Executor中先启动ReceiverSupervisor);
-
03、 在Receiver收到数据后会通过ReceiverSupervisor存储到Executor并且把数据的Metadata信息发送给Driver中的ReceiverTracker 。
04、 在ReceiverTracker内部会通过ReceivedBlockTracker来管理接受到的元数据信息 。
05、 每个BatchInterval会产生一个具体的Job,其实这里的Job不是Spark Core中所指的Job,它只是基于DStreamGraph而生成的RDD的DAG而已 。
06、 要想运行Job需要提交给JobScheduler,在JobScheduler中通过线程池的方式找到一个单独的线程来提交Job到集群运行(在线程中基于RDD的Action触发真正的作业的运行)。