Hadoop HDFS
概述:
Hadoop有存储海量数据的分布式文件系统HDFS,有统一资源调度管理框架YARN,而且还有离线计算框架MapReduce。如果类比于各种操作系统,Hadoop可以认为是一个数据操作系统。Hadoop使用背景非常广泛。Hadoop实际使用几种实例;一、facebook使用HiveQL进行数据分析,二、使用的Hive,实现淘宝搜索中的自定义筛选功能,三、使用的Pig运行Hadoop作业,实现Twitter和LinkedIn 上发现您可能认识的人功能,四、实现Amazon.com和淘宝上的商品协同过滤的推荐效果,五、Yahoo使用Hadoop,实现垃圾邮件的识别和过滤,还有用户特征建模功能。本文主要内容是解析Hadoop系统抽象的文件系统概念和分布式文件系统HDFS。
一、HDFS(Hadoop Distributed File System)
1、NFS(Network File System)和HDFS(Hadoop Distributed File System)对比分析:
1、NFS是集中型文件系统,HDFS是分散型文件系统。
2、NFS文件系统的文件是存储在单一的NFS Server中,NFS Client通过网络连接可以从单一的NFS Server中获取文件同步到本地,对文件进行修改之类的操作之后同步到单一的NFS Server。当很多NFS Client同时访问这个单一的NFS Server时,很容易造成单一的NFS Server处理压力,造成性能瓶颈。
HDFS文件系统的文件是分散存储在HDFS Server集群中的各个节点机器上,即HDFS文件是HDFS Server集群所有节点机器的文件的集合。HDFS文件系统提供副本进行容错及可 靠性保证。HDFS Client通过网络连接获取HDFS Server集群中的文件,HDFSClient对文件的直接操作是分布在HDFS Server集群中的对应的机器上的,没有单点压力。
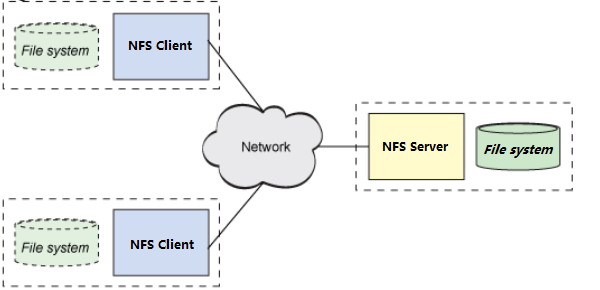
3、NFS集中型文件系统示意图
图-1 NFS(集中型文件系统)示意图
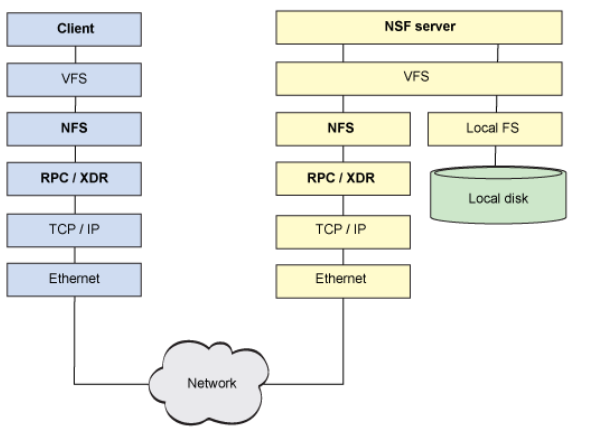
4、NFS集中型文件系统协议栈示意图
图-2 NFS(集中型文件系统)协议栈示意图
2、HDFS解析:架构 >> 核心概念及各部分的主要组成部分
0、Hadoop的文件系统概念是抽象的,HDFS只是其中的一种实现
1、HDFS文件系统的应用场景:一、文件体积庞大,HDFS文件系统满足TB甚至PB数量级数据需求、二、基于数据流的数据访问形式、三、HDFS文件系统可以直接运行于普通的商用机器上,服务器群总计可达数千个节点
2、HDFS文件系统的文件存储在集群中各个机器,优化的HDFS文件系统需要实现集群中的节点失效时,用户没有感觉到明显的中断。(Hadoop的HA方案)
3、HDFS架构
图-3 HDFS架构
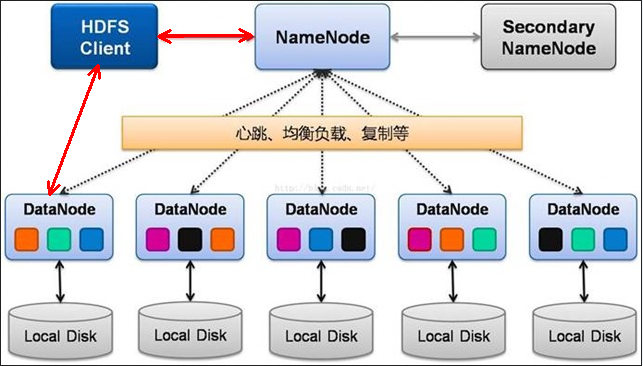
4、HDFS架构各部分:
4.1、Namenode:Master Server(只有一个):构建和管理 HDFS 的名称空间,管理文件和block(数据块)映射信息,管理 block与datanode之间关系;配置副本策略;处理HDFS Client读写请求
4.2、Secondary NameNode:NameNode 的热备;定期或在edits文件超过设定值时,合并fsimage文件和edits文件创建checkpoint,推送给 NameNode;当 NameNode 出现故障时,拷贝NFS中的备份元数据到Secondary NameNode,Secondary NameNode快速切换为新的 NameNode。合并操作并不是实时而且需要耗费大量的CPU和内存,导致checkpoint数据落后于Namenode。
4.3、Datanode:Slave Server(有多个):存储实际的数据块(文件被分成block存储在磁盘上Local Disk,为保证数据安全,文件会有多个副本Replication);执行数据块读 / 写
4.4、HDFS Client:与 NameNode 交互,获取文件位置信息;与 DataNode 交互,读取或者写入数据
5、HDFS核心概念
5.1、Blocks:磁盘的物理Block是磁盘操作最小的单元,读写操作均以Block为最小单元,一般为512 Byte。文件系统在物理Block之上抽象了另一层概念,文件系统Block物理磁盘Block的整数倍。Linux系统的文件系统抽象的概念是页,文件系统页标准大小是4KB。HDFS的Block块比一般单机文件系统大得多,默认为128M。比Block小的文件不会全部占用整个Block,只会占据实际大小。合理设置block的大小,可以控制定位block与文件传输的时间的比例,又可以使MapReduce任务的个数能与集群中Datanode数量相匹配,使得在集群中运行的作业效率最优化!
5.2、Namenode:
1、维护文件系统的文件目录树、内存中保存所有文件和目录的元数据(metedata)、每个文件对应的数据块列表,接收用户的操作请求
2、fsimage文件(元数据镜像文件):存储某一时段NameNode内存元数据信息;edits文件:操作日志文件(edit log);fstime文件:保存最近一次checkpoint的时间
3、元数据持久化为2种形式:一、namespcae image;二、edit log。
4、写请求”到来时,NameNode首先会写editlog到磁盘,即向edits文件中写日志,成功返回后,才会修改内存
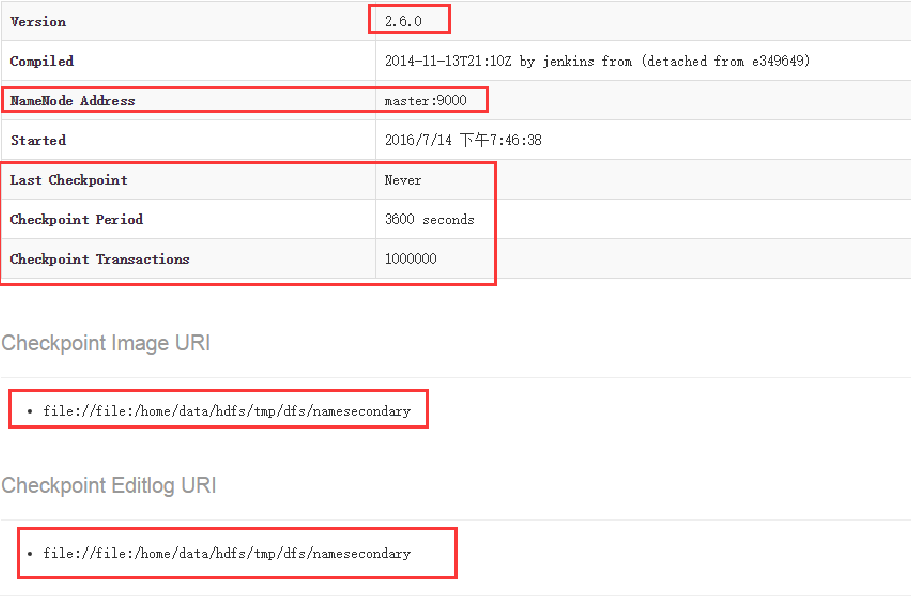
5、Namenode中的fsimage不会随时与NameNode内存中的metedata保持一致。Secondary NameNode每隔一段时间(默认3600秒)或者edits文件超过fs.checkpoint.size 值,就会合并fsimage文件和edits文件来创建新的fsimage,并把该fsimage通过HTTP POST推送给Namenode。Namenode才根据fsimage更新fsimage。
图-4 Secondary Namenode的管理界面
5.3、DataNode:
1、数据节点负责存储和提取Block,读写请求可能来自namenode,也可能直接来自客户端。
2、数据节点周期性或系统重启向Namenode汇报自己节点上所存储的Block相关信息
3、数据存储的相关参数:dfs.block.size:默认128M、dfs.Replication(多复本个数):默认是3
3、HDFS通过Java API读、写过程解析
预备知识:
1、HDFS提供了各种交互方式,例如通过Java API、HTTP、shell命令行等进行交互。
1.1、shell命令行的交互主要通过hadoop fs来操作:
hadoop fs -copyFromLocal // 从本地复制文件到HDFS hadoop fs mkdir // 创建目录 hadoop fs -ls // 列出文件列表 hadoop fs ls // 查看文件或者目录的详细信息
1.2、Java API进行交互:操作基于FileSystem进行封装:
org.apache.hadoop.fs.FileSystem public static FileSystem get(Configuration conf) throws IOException public static FileSystem get(URI uri , Configuration conf) throws IOException public static FileSystem get(URI uri , Configuration conf,String user) throws IOException
1.3、HTTP进行交互:WebHDFS和SWebHDFS协议将文件系统暴露HTTP操作,这种交互方式比原生的Java客户端慢,不适合操作大文件。
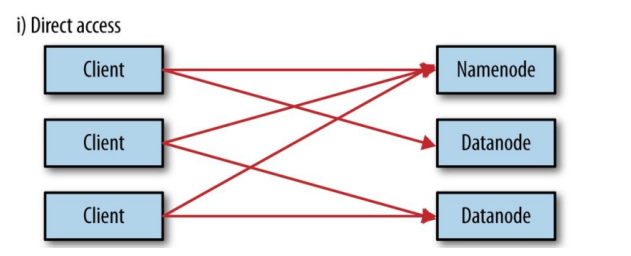
一、直接交互:Namenode和Datanode默认打开了嵌入式web server,即dfs.webhdfs.enabled默认为true。
webhdfs通过这些服务器来交互。元数据的操作通过namenode完成,文件的读写首先发到namenode,然后重定向到datanode读取(写入)实际的数据流
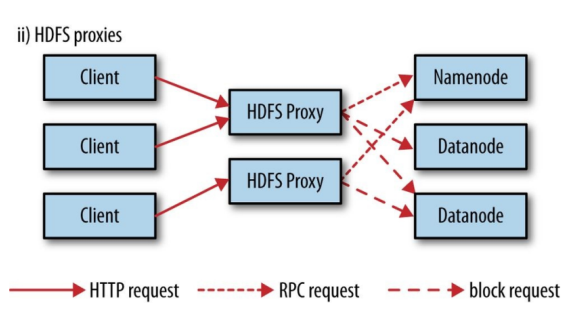
二、HDFS代理:使用代理的好处是可以通过代理实现负载均衡或者对带宽进行限制,或者防火墙设置。
代理通过HTTP或者HTTPS暴露为WebHDFS,对应为webhdfs和swebhdfs URL Schema
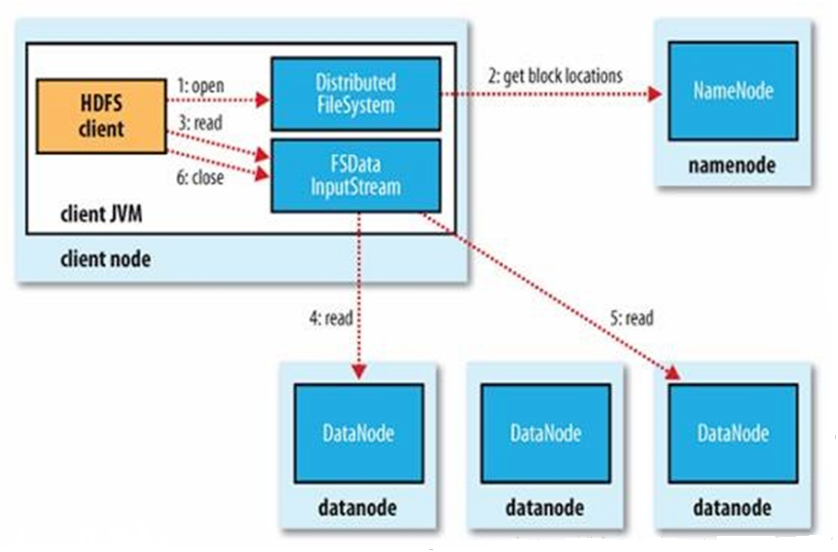
1、HDFS的读过程(Java API):
1、使用URL来读取数据:java.net.URL类提供了资源定位的统一抽象,任何人都可以自己定义一种URL Schema,并提供相应的处理类来进行实际的操作。
InputStream in = null;
try {
in = new URL("hdfs://master/user/hadoop").openStream();
}finally{
IOUtils.closeStream(in);
}
2、使用FileSystem API读取数据:
第一步:首先获取FileSystem实例,一般使用静态get工厂方法或者getLocal(本地文件)
静态get工厂方法:
public static FileSystem get(Configuration conf) throws IOException public static FileSystem get(URI uri , Configuration conf) throws IOException public static FileSystem get(URI uri , Configuration conf,String user) throws IOException
getLocal(本地文件):
public static LocalFileSystem getLocal(COnfiguration conf) thrown IOException
第二步:调用FileSystem的open方法获取一个输入流(集群向client输送数据):
public FSDataInputStream open(Path f) throws IOException public abstarct FSDataInputStream open(Path f , int bufferSize) throws IOException
注:open默认使用4KB的Buffer,可以根据需要自行设置
FileSystem用RPC调用元数据节点,得到文件的数据块信息,对于每一个数据块,元数据节点返回保存数据块的数据节点的地址
第三步:FileSystem返回FSDataInputStream给客户端,客户端调用FSDataInputStream的read()函数读取数据:
public class FSDataInputStream extends DataInputStream
implements Seekable, PositionedReadable,
ByteBufferReadable, HasFileDescriptor, CanSetDropBehind, CanSetReadahead,
HasEnhancedByteBufferAccess
注:FSDataInputStream是java.io.DataInputStream的特殊实现,在其原有功能基础上增加了随机读取(Seekable)、部分读取(PositionedReadable)
FSDInputStream连接保存此文件第一个数据块的最近的数据节点,data从数据节点读到客户端(client),当此数据块读取完毕时,FSDInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。当客户端读取完毕数据的时候,调用FSDataInputStream的close函数
异常:在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。失败的数据节点将被记录,以后不再连接
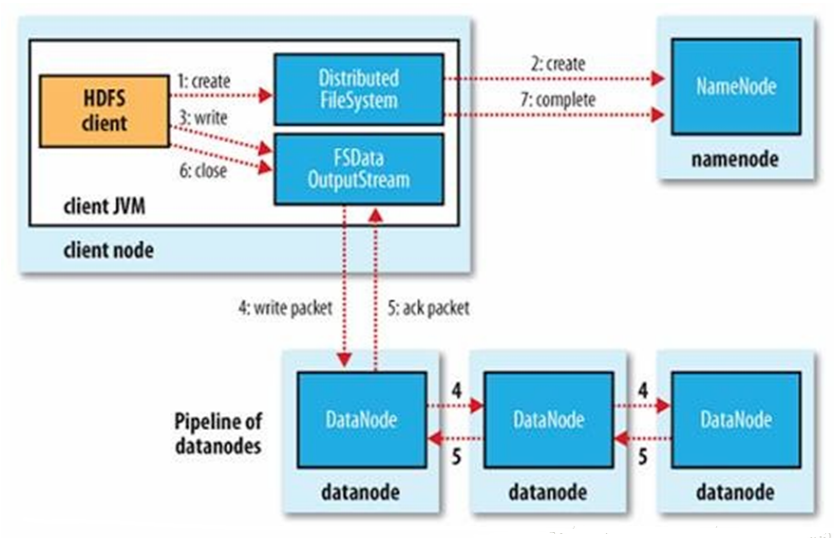
2、HDFS的写过程(Java API):
1、首先获取FileSystem实例
2、调用FileSystem类的create方法,create方法返回一个输出流(client向集群的输送数据)
注:FileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件,元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件
3、FileSystem返回DFSOutputStream,客户端使用FSDataOutputStream进行数据操作:可以调用返回输出流的getPos方法查看当前文件的位移,但是不能进行seek操作,HDFS仅支持追加操作(append(Path f)),可以传递一个回调接口Peofressable,获取进度信息
注:FSDOutputStream将数据分成块,写入data queue。data queue由Data Streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个pipeline里。Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点(一个数据块一般只会被一个节点缓存但是默认会被复写为三个数据块保存在三个数据节点的磁盘中)
FSDOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功
当客户端结束写入数据,则调用stream的close函数。此操作将所有的数据块写入pipeline中的数据节点,并等待ack queue返回成功。最后通知元数据节点写入完毕
异常:如果数据节点在写入的过程中失败,关闭pipeline,将ack queue中的数据块放入data queue的开始,当前的数据块在已经写入的数据节点中被元数据节点赋予新的标示,则错误节点重启后能够察觉其数据块是过时的,会被删除。失败的数据节点从pipeline中移除,另外的数据块则写入pipeline中的另外两个数据节点。元数据节点则被通知此数据块是复制块数不足,将来会再创建第三份备份
String localSrc = args[0];
String dst = args[1];
InputStream in = new BufferedInputStream(new FileInputStream(localSrc));
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(dst),conf);
OutputStream out = fs.create(new Path(dst), new Progressable(){
public vid progress(){
System.out.print(.);
}
});
IOUtils.copyBytes(in , out, 4096,true);
4、HDFS性能优化
1、Block Caching
1.1、频繁使用的Block可以在内存中缓存。默认情况下,一个Block只有一个数据节点会缓存。但是可以针对每个文件可以个性化配置。
1.2、作业调度器利用Block Caching,将任务运行在有Block缓存的节点上
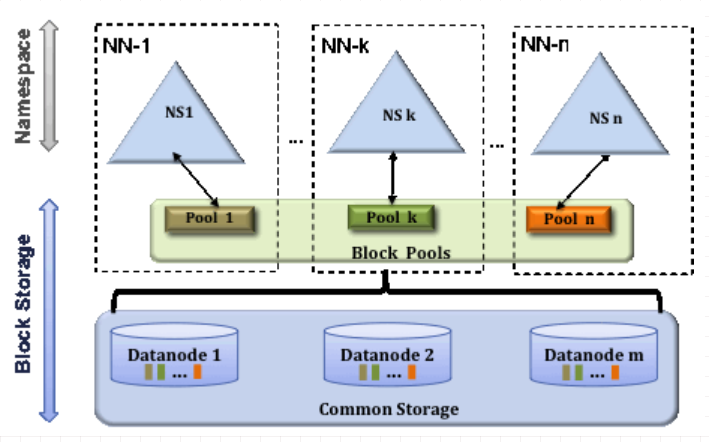
2、HDFS Federation
2.1、NameNode的内存会制约文件数量,多个并行的NameNodes进行优化
2.2、Federation采用多个独立的NameNodes/namespaces。NameNodes是独立的,彼此之间不需要联系和协调,但是DataNodes被用来作为所有NameNodes的公共存 储。每一个DataNode会注册到集群中的所有NameNode。每一个独立namespace创建的 block 带有 blockID,DataNode存储集群中所有block pool的块也就是Block Pools。
图-5 Multiple Namenodes/Namespaces
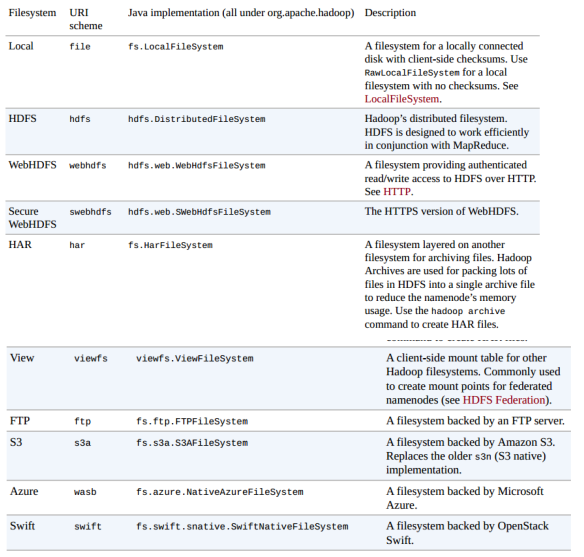
5、Hadoop的文件系统概念是抽象的,HDFS只是其中的一种实现,Hadoop提供的实现如下图:
图-6 Hadoop提供的文件系统的实现