公共模块
1. 使用基于上下文的内存分配器进行内存分配
除了教材里常提到的buffer pool,数据库还会为其他任务分配大量内存,例如,Selinger-style查询优化需要动态的规划查询;hashjoin和排序需要分配大量私有空间。正确管理内存给编程和性能带来挑战,商业数据库系统一般使用context-based基于上下文的内存分配器。
context上下文是指一个包含了连续虚拟内存区域链表的内存数据结构;每个region区域包含一个头信息,头信息通过标签或指针指向上下文头信息。
Context基本API包括:
1. context create(nullable name, nullable type)。type用于指示内存分配方式,是每次分配很多还是每次分配很少。例如查询优化器的内存增长比较小,hashjoin需要少次多量的申请内存。
2. context内分配一块内存。malloc from 现有reign,如果现有reign没有足够空间,则向操作系统请求一块新区域。
3. context内删除一块内存。删除可能触发reign被context删除。这种方法很少见,因为一般都是删除整块context。
4. 删除整块context。先释放所有region,然后删除context头信息。
5. reset(context)。释放所有reign内存。
memory context内存上下文的功能是一个底层、程序可控的gc,它具有重要的软件工程优势。例如查询计划的传播:优化器在optimizer上下文里为查询分配内存,整理出最佳查询计划后,只需把内存里查询计划拷贝到executor上下文里,然后删除整个optimizer上下文;这个步骤不需要程序走一遍optimizer上下文里所有内存、然后删除查询计划无关的要素。这种管理方式特别适合parser->optimizer->execution这种阶段性的查询处理,同时如果编码不慎,产生的bug也难以定位。
比起普通GC,memory context可供开发人员控制释放的空间位置和时间位置。能空间控制是因为上下文机制本身就将内存划分为很多块;时间控制是因为提供了delete接口。对比起来,GC是由gc自己走读程序所有内存、自行决定是否删除,这种不透明对用java写服务器质量代码是一个挫折。
memory context另一个优势是高性能。这是因为很多平台上malloc和free的开销大,尤其是对像解析器和优化器这种少量多次申请内存然后释放的组建使用free()开销有七大。有了memory context,对小内存的malloc和free整合成了对reign的malloc和对context的free,系统调用次数减少。
了解memory allocator,可阅读开源PG代码(作者可真是个PG粉),因为复杂度中上(fairly sophisticated)。
各厂商对于空间敏感的查询运算符如hash join、sort,在空间分配上有巨大实现差异:
- DB2允许DBA控制以上查询操作符能获得的RAM大小,而如何保证每个查询在执行时都获得足够内存,则是通过访问控制策略来实现。In such systems, the operators allocate their memory off of the heap via the memory allocator. (这一句是说把堆内存一次分配完,还是说靠memory allocator分配内存?Allocate off到底有没有分配完的意思?)。DB2能保证性能稳定,但是要求DBA静态指定物理内存在缓冲池、查询运算符这些子系统之间的分配。
- SQL Server靠数据库自行决断内存分配,如何实现内存在缓冲区、各个查询、查询运算符、查询执行之间的分配呢?绕过memory allocator,从缓冲池里分配查询任务所需的内存。
4.3中讨论过查询准备的两种设计哲学,一种假设DBA有复杂的技能,数据库系统功能就是可调旋钮,这样数据库系统要做到性能可预估;后一种假设DBA是打酱油的,数据库系统自适应的进行内存分配。
2. 磁盘管理子系统
DB有专门的磁盘管理子系统处理存储,包括跨多种设备的表空间分配、存储单元。
表与文件一一对应是否可行?
1. 在早期不可行:(这篇论文87年发表,87年的早期..)
OS文件不能超过磁盘大小,而数据库表要求跨越多个磁盘;
OS能支持的同时打开的fd有数目限制、单个目录下文件数也有限制,分配太多文件不合适;
这种情况下共享表空间比较好。
2. 随着操作系统发展,上述限制都消失了,文件被DB当作抽象的存储单元。
复杂存储设备的发展给数据库存储管理带来哪些挑战?
像NAS、RAID这些设备通过提供历史磁盘接口如SCSI来“假装”成普通磁盘,因为这些设备提供了大容量、容易管理、比特级别可靠性、快速/立即故障转移,很多消费者选择将DB安装在这些设备上,但是其复杂的性能特性增加了DB实现的复杂度。举例说明:RAID系统发生故障后,它的性能与所有磁盘都无故障时的性能非常不同,这增加了数据库I/O成本模型的难度。再举例:NAS、RAID像文件系统那样倾向于用自身的缓冲策略控制写实效,这可能颠覆数据库的WAL协议,那虽然停电后存储一致性可以得到保证,但事务一致性可能被破坏。为了保证在各种设备上的事务一致性,DB需要了解主要存储设备的进出,并对其进行相应的管理。
单独讨论RAID是怎样因执行数据库任务表现不佳而挑战DB认知的。
RAID是面向字节流的存储,而数据库是面向元组的存储。因此RAID设备在跨物理设备(如链式集群方案)的数据库分区、主从复制的场景下表现性能不太好。很多数据库提供控制跨设备分区的命令,但是RAID设备只提供简单接口,不提供这些命令。更近一步的,为追求数据库负载量很多用户都是配置为raid5的,但是同时数据库写更加昂贵了,数据库厂商花费很长时间调试DB产品,以便在RAID设备上运行良好。
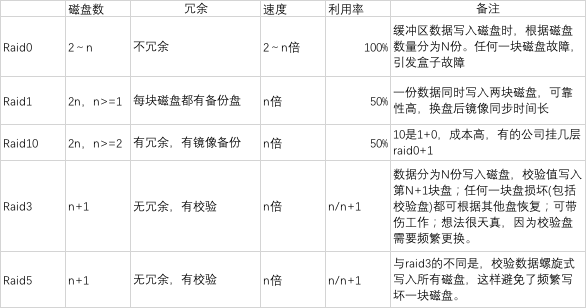
3. 复制服务
复制的好处:
1. 提升系统可靠性,因为从机是一台数据稍微延迟的standby。
2. 跨地域的分布式数据库,前提是系统不要求那么实时的数据。
复制的分类:
1. 物理复制(看论文像是说搬磁盘)。定期的物理复制数据库,数据传输带宽和远程重新安装的代价决定了这种方式无法适应大规模数据库。为了保证事务性一致快照,备份时需要停止应用系统,因此数据库厂商把物理复制当作一种低端的客户端技巧,也不提供任何软件支持物理复制。
2. 基于触发器的复制。对于dml操作将差异记录到特殊的表里,之后用特殊表对远程数据库进行回放。这种方式不要求停止应用系统来备份,但是带来一系列性能问题:
a) 适用面窄,因为很多厂商提供的触发工具非常有限
b) 触发器的性能跟不上事务系统的性能,通常对于update会增加100%的I/O
3. 基于日志的复制。这种方法最能支撑性能和扩展要求。
日志sniffer嗅探器截获日志写入,然后发送到远程节点,远程节点redo重做这些日志。这种方式性能损耗低、支持增量修改,因此可随着数据库大小和更新速率优雅扩展。因为重用了DB内部机制,因此既不需要太多新逻辑,又天然能提供事务一致性副本。很多厂商都提供面向日志的复制,但是跨厂商的复制有难度,因为日志格式没有规范、需要翻译。
4. batch utilities
批操作很少进行基准测试,但常常决定系统的可管理性。批操作工具的技术难点在于在线运行,因为现在的主流是24*7服务,没有重组时间。目前主流的在线工具有:
1. 优化数据收集。所有数据库都会大范围搜索表以便统计优化器所需数据,如柱状图。
2. 物理重组和索引构建。插入和删除会留下空洞,导致访问方法不再高效;用户请求如按其他列排序、重新分片到多个磁盘,这些都对物理重组、构建索引建立提出要求。在线物理重组和构建索引的挑战是保持物理一致性的情况下避免持有锁。
3. 备份/导出。Dump操作持续时间太长,因此不能简单的靠持有锁来实现dump。一般是靠模糊dump+日志(保证事务一致性)实现dump。
结语
作者首先让步说,从零开始开发一个商业力度、面向高端客户的数据库产品(高性能、功能完备)需要消耗巨大时间和精力,加上目前数据库工业已经形成几大霸主,这个竞技场已经不适合新手了。作者随后提出观点,数据敏感服务依然是计算的核心,因此数据库系统的设计技巧仍然使用于数据库和非数据库领域;数据库社区仍然会发展因为非数据库领域的新应用对数据库提出了新的问题。