字数统计
Time Limit: 1000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)
Total Submission(s): 3021 Accepted Submission(s): 812
Problem Description
一天,淘气的Tom不小心将水泼到了他哥哥Jerry刚完成的作文上。原本崭新的作文纸顿时变得皱巴巴的,更糟糕的是由于水的关系,许多字都看不清了。可怜的Tom知道他闯下大祸了,等Jerry回来一定少不了一顿修理。现在Tom只想知道Jerry的作文被“破坏”了多少。
Jerry用方格纸来写作文,每行有L个格子。(图1显示的是L = 10时的一篇作文,’X’表示该格有字,该文有三个段落)。
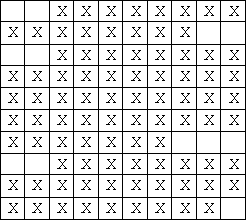
图1
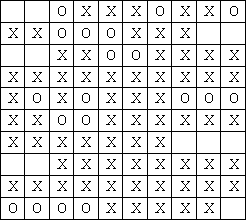
图2
图2显示的是浸水后的作文 ,‘O’表示这个位置上的文字已经被破坏。可是Tom并不知道原先哪些格子有文字,哪些没有,他唯一知道的是原文章分为M个段落,并且每个段落另起一行,空两格开头,段落内部没有空格(注意:任何一行只要开头的两个格子没有文字就可能是一个新段落的开始,例如图2中可能有4个段落)。
Tom想知道至少有多少个字被破坏了,你能告诉他吗?
Jerry用方格纸来写作文,每行有L个格子。(图1显示的是L = 10时的一篇作文,’X’表示该格有字,该文有三个段落)。
图1
图2
图2显示的是浸水后的作文 ,‘O’表示这个位置上的文字已经被破坏。可是Tom并不知道原先哪些格子有文字,哪些没有,他唯一知道的是原文章分为M个段落,并且每个段落另起一行,空两格开头,段落内部没有空格(注意:任何一行只要开头的两个格子没有文字就可能是一个新段落的开始,例如图2中可能有4个段落)。
Tom想知道至少有多少个字被破坏了,你能告诉他吗?
Input
测试数据有多组。每组测试数据的第一行有三个整数:N(作文的行数1 ≤ N ≤ 10000),L(作文纸每行的格子数10 ≤ L ≤ 100),M(原文的段落数1 ≤ M ≤ 20),用空格分开。
接下来是一个N × L的位矩阵(Aij)(相邻两个数由空格分开),表示被破坏后的作文。其中Aij取0时表示第i行第j列没有文字(或者是看不清了),取1时表示有文字。你可以假定:每行至少有一个1,并且所有数据都是合法的。
接下来是一个N × L的位矩阵(Aij)(相邻两个数由空格分开),表示被破坏后的作文。其中Aij取0时表示第i行第j列没有文字(或者是看不清了),取1时表示有文字。你可以假定:每行至少有一个1,并且所有数据都是合法的。
Output
对于每组测试输出一行,一个整数,表示至少有多少文字被破坏。
Sample Input
10 10 3
0 0 0 1 1 1 0 1 1 0
1 1 0 0 0 1 1 1 0 0
0 0 1 1 0 0 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 0 1 0 1 1 1 0 0 0
1 1 0 0 1 1 1 1 1 1
1 1 1 1 1 1 1 0 0 0
0 0 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
0 0 0 0 1 1 1 1 1 0
Sample Output
19
Source
Recommend
题目意思:
给出一段N*L的01矩阵,矩阵的一个值代表一个文章的一个字,
整个矩阵就是一段文字,0表示模糊(可能有值,也可能无),1表示有字。
已知开头两个00是段落的标记,若文章原段落数是M,求0表示的模糊字最少多少?
分析:先数一下0的总数是多少,然后减去最后一行的末尾的连续的0数目
然后减去每一段开头的两个0(段落数*2)
因为开始计算了最后一行,所以现在段落数目减一
然后遍历(第2行到n),遇到开头是两个0的看它上面那行末尾连续的0的数目是多少,存起来
然后降序排序一下,排序号之后,减去段落数个数就是至少被污染的数目
比如样例,总共是31个0,减去最后一行末尾的一共0,30个
减去段落数*2个0,30-2*3=24
段落数减1(最后一行算过了)
然后从第2行开始遍历到最后,得到数组:3,2,0
还有两个段落,所以减去数组里面的两个数字
24-3-2=19
code:
#include<stdio.h> #include<string.h> #include<iostream> #include<algorithm> #include<string> #include<cmath> #include<map> using namespace std; #define LL long long int #define MEM(a) memset(a,0,sizeof(a)) const int INF = 0x3f3f3f3f; int n, m, k; int mp[10005][105]; bool cmp(int x, int y) { return x > y; } int main() { while (scanf("%d%d%d", &n, &m, &k) != EOF) { int sum = 0; int sum_last = 0; int han[10005] = { 0 }; int idx = 0; for (int i = 1; i <= n; i++) { for (int j = 1; j <= m; j++) { scanf("%d", &mp[i][j]); //如果当前是0 if (mp[i][j] == 0) { sum++; } } //如果是最后一行 if (i == n) { //统计最后一行的0的个数 for (int j = m; j >= 1; j--) { if (mp[i][j] == 0) { sum_last++; } else { break; } } } } //printf("sum=%d ",sum); //减去最后一段末尾的空格数 //printf("sum_last=%d ",sum_last); sum -= sum_last; //printf("sum=%d ",sum); //减去每一段开头的两个空格 sum -= k * 2; // printf("sum=%d ",sum); //因为已经减了最后一段的空格数,so段落数要减一 k--; // printf("k=%d ",k); for (int i = 2; i <= n; i++) { //如果当前行前面有两个0 if (mp[i][1] == mp[i][2] && mp[i][1] == 0) { //找当前行的上一行的0的个数 for (int j = m; j >= 1; j--) { if (mp[i - 1][j] == 0) { han[idx]++; } else { //如果当前不是0,就break idx++; break; } } } } //末尾的0从大到小排序 sort(han, han + idx, cmp); for (int i = 0; i < idx; i++) { //每减去一行段落数要减一 sum -= han[i]; k--; if (k <= 0) { break; } } printf("%d ", sum); } return 0; }