前言
从毕业到现在,一直是Java 开发的码农,对大数据方面相关的技术也有点兴趣,一直以来是了解的状态并没有认真的把这一套技术学习实践下。
因为是Java码农,所以对于大数据Hadoop生态圈来说还是比较友好的,毕竟大多数都是Java语言开发的。经过我了解到的大数据相关的技术知识,整理下接下来要好好学习的内容,即学习计划,顺便记录下学习的历程。
Big Data 简介
百度百科的解释:大数据(big data)是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据的五大特性:
Volume(大量), Velocity(高速),Variety(多样),Value(低价值密度),Veracity(真实性)
学习基本路线
1. Java
-
Javase
Java基础主要包括JavaBean、Java集合、简单算法、Java I/O和JDBC等。
因为Hadoop生态圈大部分组件和框架都是由Java语言编写的,学习好基础方便我们阅读源码、操作相关组件和排查问题等。应该说这是最核心的知识点。 -
Java Web
JavaWeb应该是将大数据处理后的结果数据通过Web的形式展示出来,学习Java Web相关主流的框架如:- 后端
- 数据库操作框架MyBatis
- Spring Boot后端开发框架
- 前端
1.vue.js
- 后端
这是我感觉比较简单的一整套Java Web框架,从前端到后端使用起来比较方便。
MySql数据库
DDL和DML相关语法
Linux
学习Linux相关操作命令:
- shell基本语法
- 文件操作
- 网络配置
- 用户管理
- 定时任务
Hadoop 生态圈
Hadoop及Hadoop核心组件
- Hadoop Common 支撑Hadoop其他组件运行的核心组件
- Hadoop Distributied File System (HDFS) 分布式文件系统
- Hadoop Yarn Hadoop任务调度和资源管理框架
- Hadoop MapReduce 并行处理大量数据集的计算系统
Hive
Apache Hive™数据仓库软件有助于使用SQL读取,写入和管理驻留在分布式存储中的大型数据集。
Hive依赖于Hadoop,主要是将存储在HDFS上的数据映射成一张表,我们可以通过普通的SQL语句查询到我们想要的数据。
- Hive的存储依赖于HDFS
- Hive的计算依赖于MapReduce,Hive的查询语句最终都是由MapReduce实现的
HBase
可扩展的分布式数据库,支持大型表的结构化数据存储
Zookeeper
针对分布式应用程序的高性能协调服务
数据收集框架Flume
Flume是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日志数据。它具有基于流数据流的简单灵活的体系结构。它具有可调整的可靠性机制以及许多故障转移和恢复机制,具有强大的功能和容错能力。它使用一个简单的可扩展数据模型,允许在线分析应用程序。
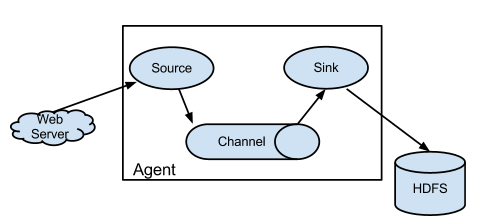
数据转换工具Sqoop
Apache Sqoop(TM)是一种旨在Apache Hadoop和结构化数据存储(例如关系数据库)之间高效传输批量数据的工具 。
任务调度框架Oozie
- Oozie是一个工作流调度程序系统,用于管理Apache Hadoop作业。
- Oozie Workflow作业是操作的有向无环图(DAG)。
- Oozie Coordinator作业是由时间(频率)和数据可用性触发的Oozie Workflow周期性作业。
- Oozie与其余Hadoop堆栈集成在一起,支持开箱即用的几种类型的Hadoop作业(例如Java map-reduce,Streaming map-reduce,Pig,Hive,Sqoop和Distcp)以及系统特定的作业(例如Java程序和Shell脚本)。
- Oozie是一个可扩展,可靠且可扩展的系统。
kafka
- Kafka是一个分布式的流处理平台
- Kafka是一个分布式的、分区的、容错的日志收集系统
flink
Apache Flink是一个框架和分布式处理引擎,用于对无限制和有限制的数据流进行有状态的计算。Flink被设计为可以在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
处理无界和有界数据
Apache Flink擅长处理无边界和有边界的数据集。对时间和状态的精确控制使Flink的运行时能够在无限制的流上运行任何类型的应用程序。有界流由专门为固定大小的数据集设计的算法和数据结构在内部进行处理,从而产生出色的性能。
-
无界流: 无界流有一个起点,但没有定义的终点。
它们不会终止并在生成数据时提供数据。无限制的流必须被连续处理,即,事件被摄取后必须立即处理。无法等待所有输入数据到达,因为输入是无界的,并且在任何时间都不会完成。处理无限制的数据通常要求以特定顺序(例如事件发生的顺序)提取事件,以便能够推断出结果的完整性。 -
有界流: 有界流具有定义的开始和结束。
可以通过在执行任何计算之前提取所有数据来处理有界流。由于有界数据集始终可以排序,因此不需要有序摄取即可处理有界流。绑定流的处理也称为批处理。
Scala
学习Scala主要是用于spark开发,因为Spark是用Scala语言编写的。
- 熟悉Scala基本语法
- 熟悉并使用Scala函数及高阶函数
Spark
一种用于Hadoop数据的快速通用计算引擎。
- Spark Core
RDD:分布式对象集合,本质上是只读的分区记录集合 - Spark Sql
交互处理 - Spark Streaming
流式计算
Spark主要用于离线数据处理
python
学习python主要用于数据爬虫。
- 熟悉python基本语法
- python的函数
- 了解python爬虫相关的库
学习路线图如下