先举个例:
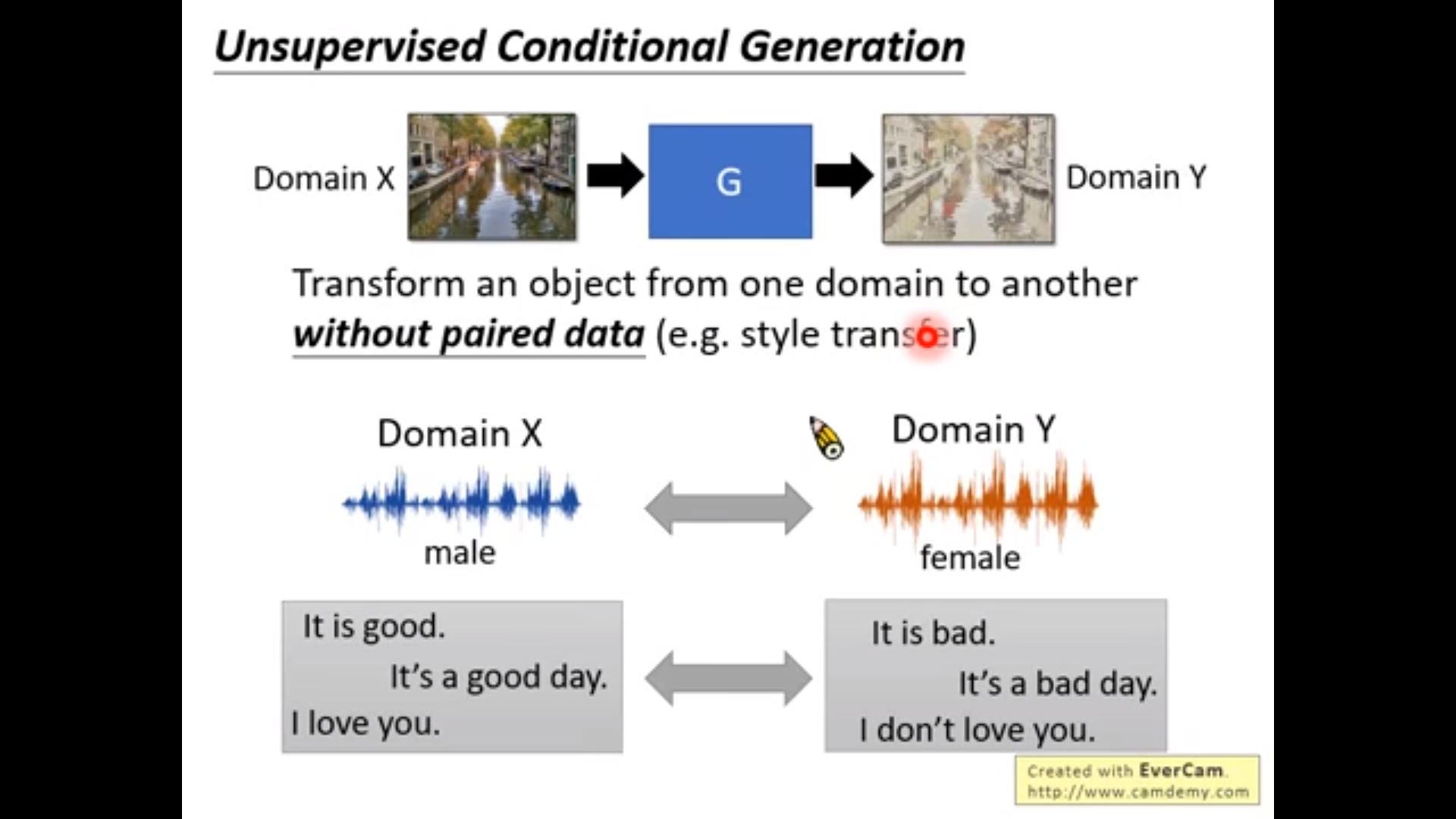
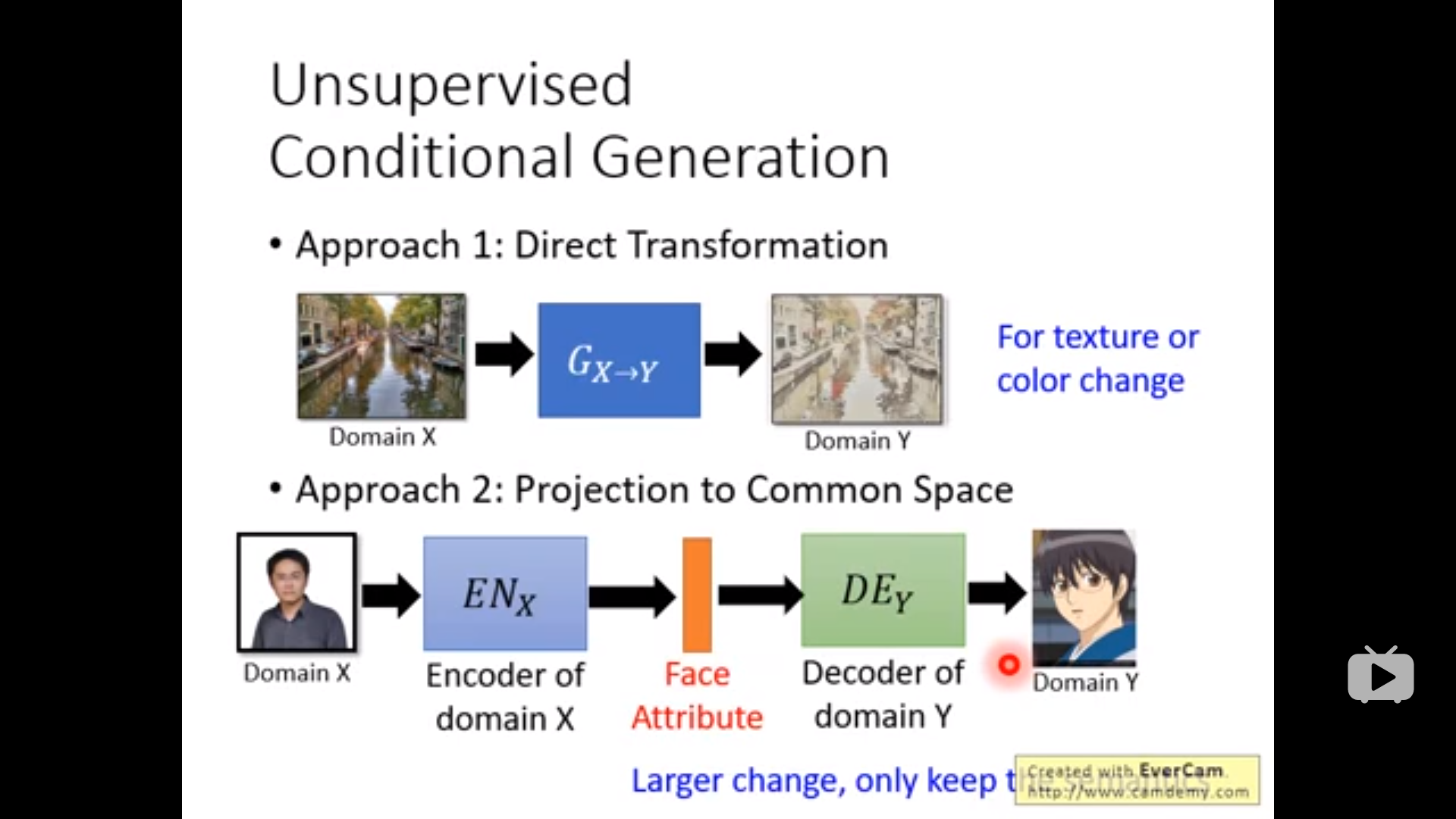
Approach 1:可以做到比较小的更改的转换
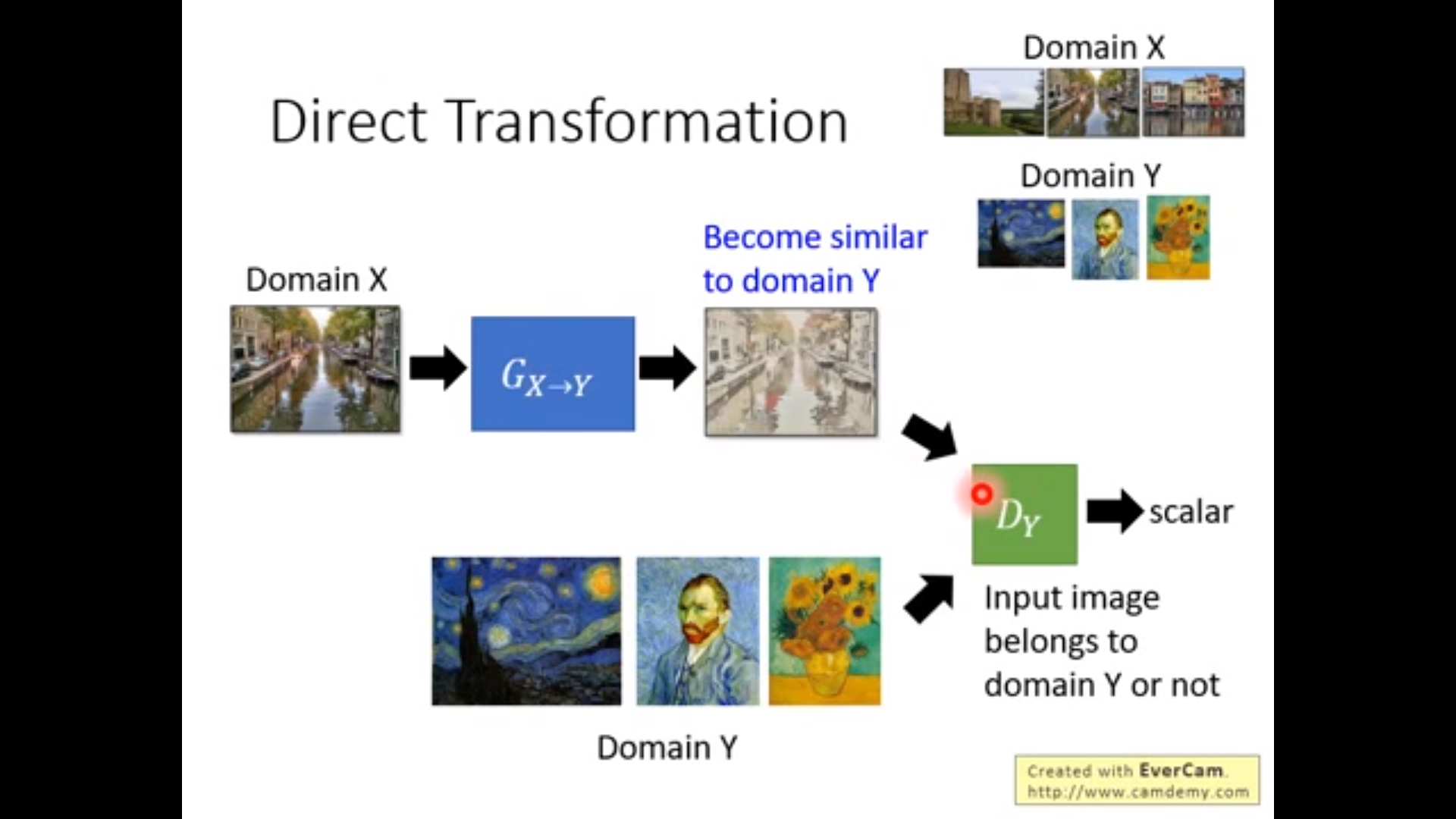
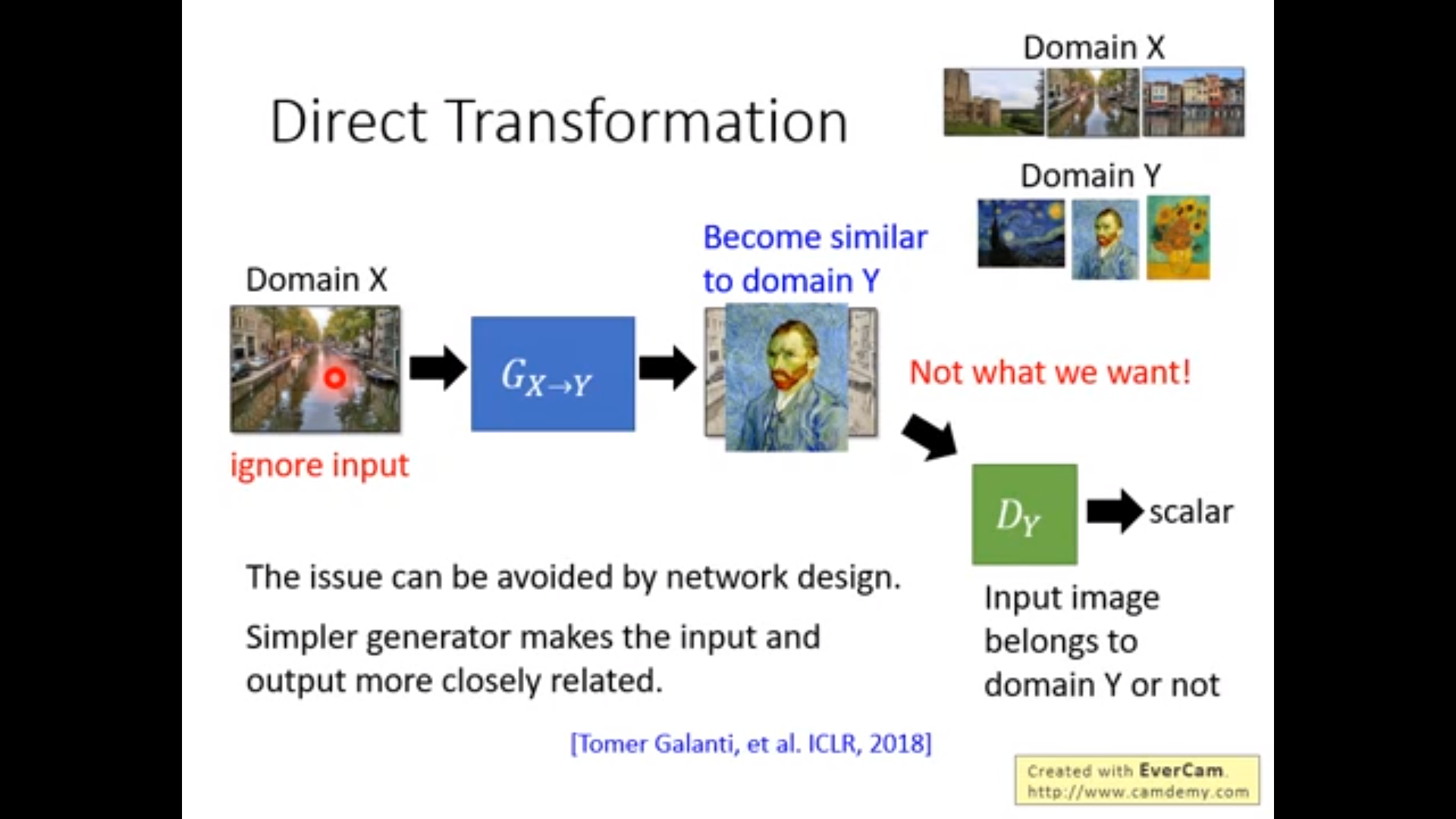
第一个做法:但是generator完全可以产生和domain Y 中某一张图片完全一样的图片,实践证明当generator比较浅的时候,input和output往往比较像。
第二个做法:比较深的网络,可能会是输入输出完全不一样,大家的做法是用预训练的网络(比如VGG)对输入输出进行特征提取,获得embedding(就是下图橙色小块,可能拼写错了),使这个embedding保持比较像,这样就能保证输入输出不会差太多。感觉这个好像是验算的意思。(我觉得可能是要保持两个pre-trained 的网络一样,然后它们提取出来的特征尽可能近的损失函数也要放到generator里面去,没有看原文,这是我猜的。)
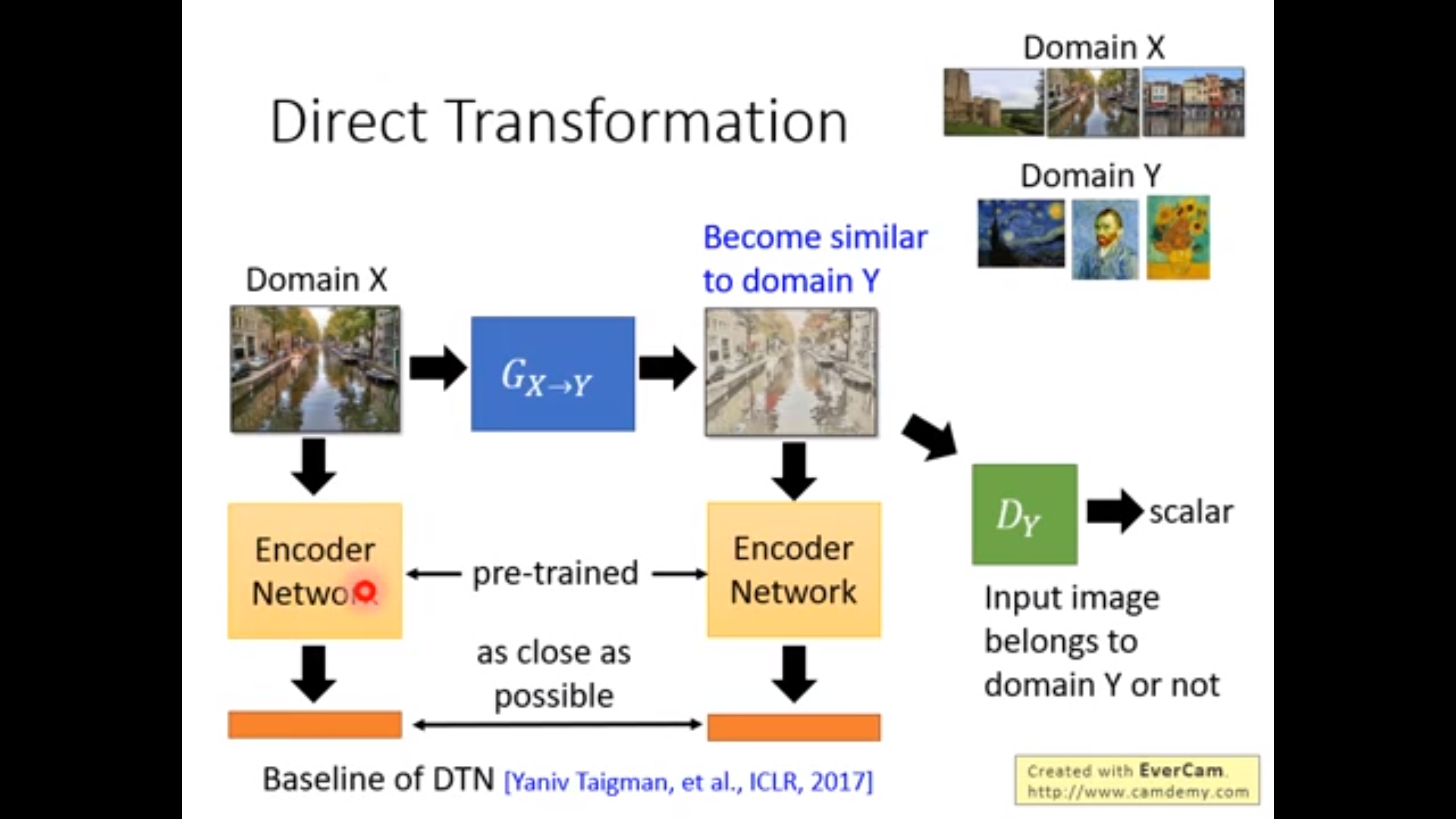
第三个做法:著名的cycleGAN,训练两个generator,两侧的图片越接近越好,这就保证了中间不会是完全无关的别的图像。除此之外,X可以转到Y,Y也可以转到X。
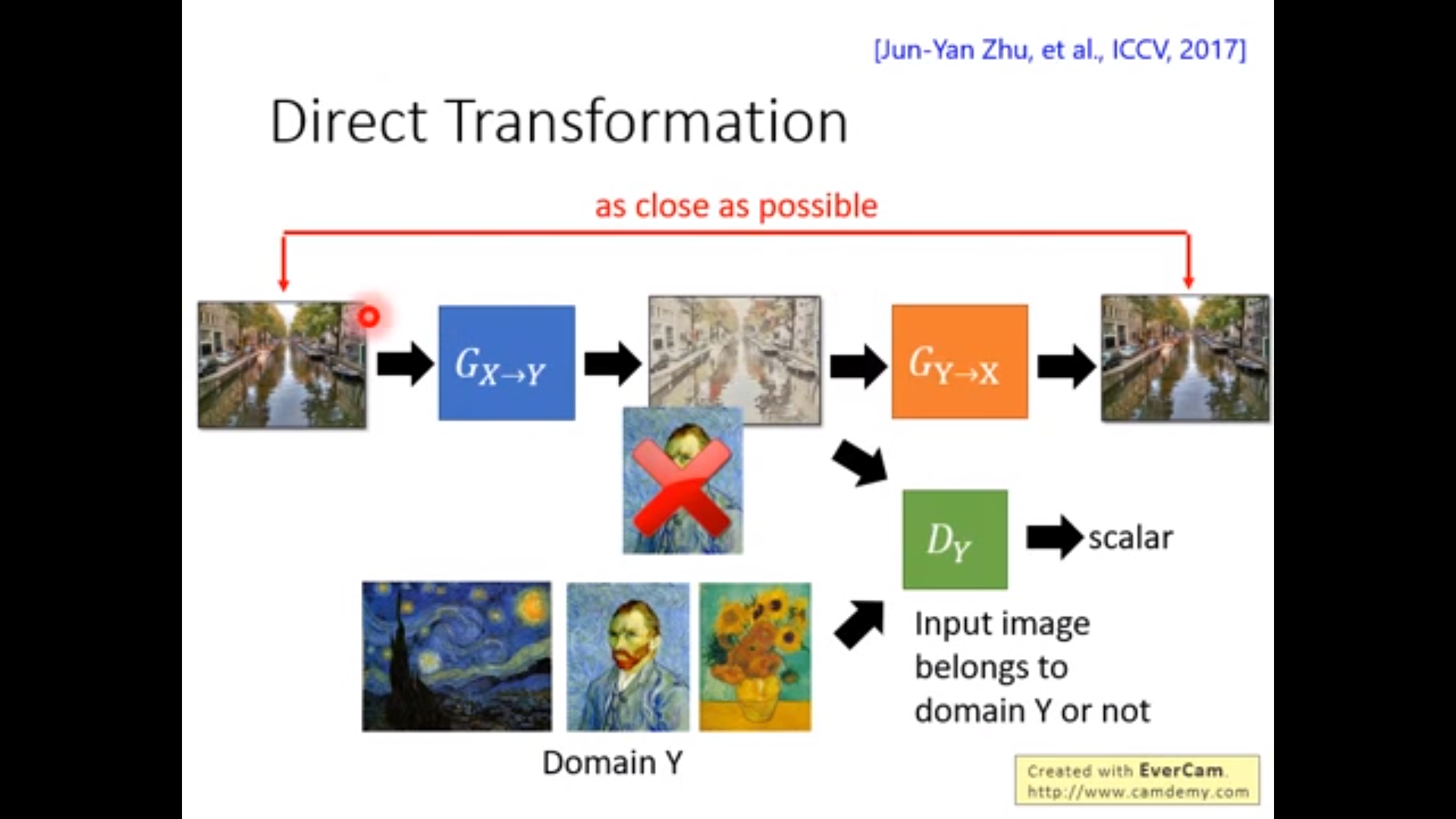
CycleGAN有问题:下图的例子,中间的generator产生的图片会把中间图片的黑点隐藏了,人眼并不能看到。

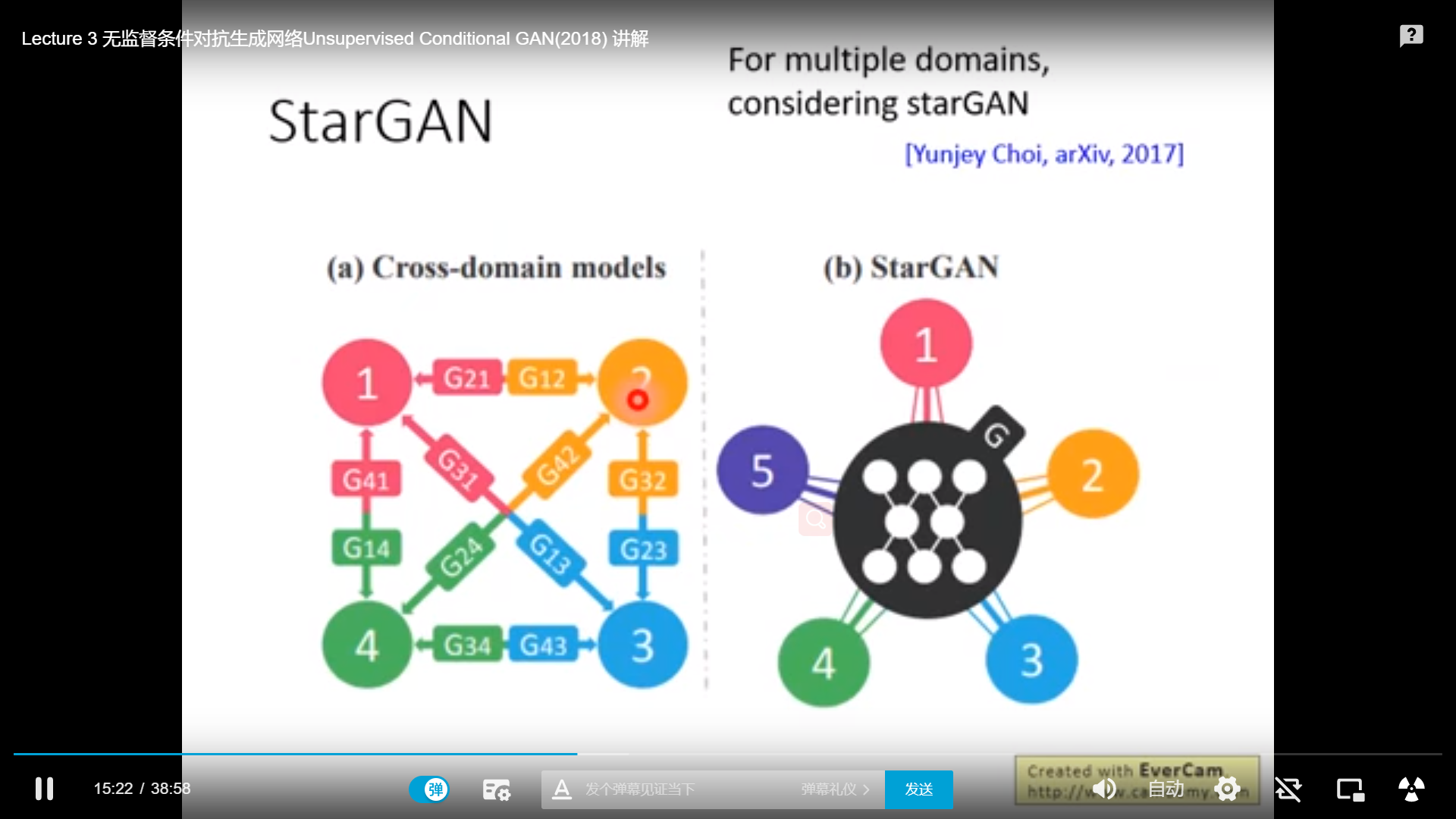
再来稍微介绍一下,starGAN,如果多个风格互转,比如4个风格的domain,需要6个generator,而starGAN可以用一个generator完成,细节不讨论。(想知道的话可以看视频)
Approach 2:可以做到比较大的更改的转换
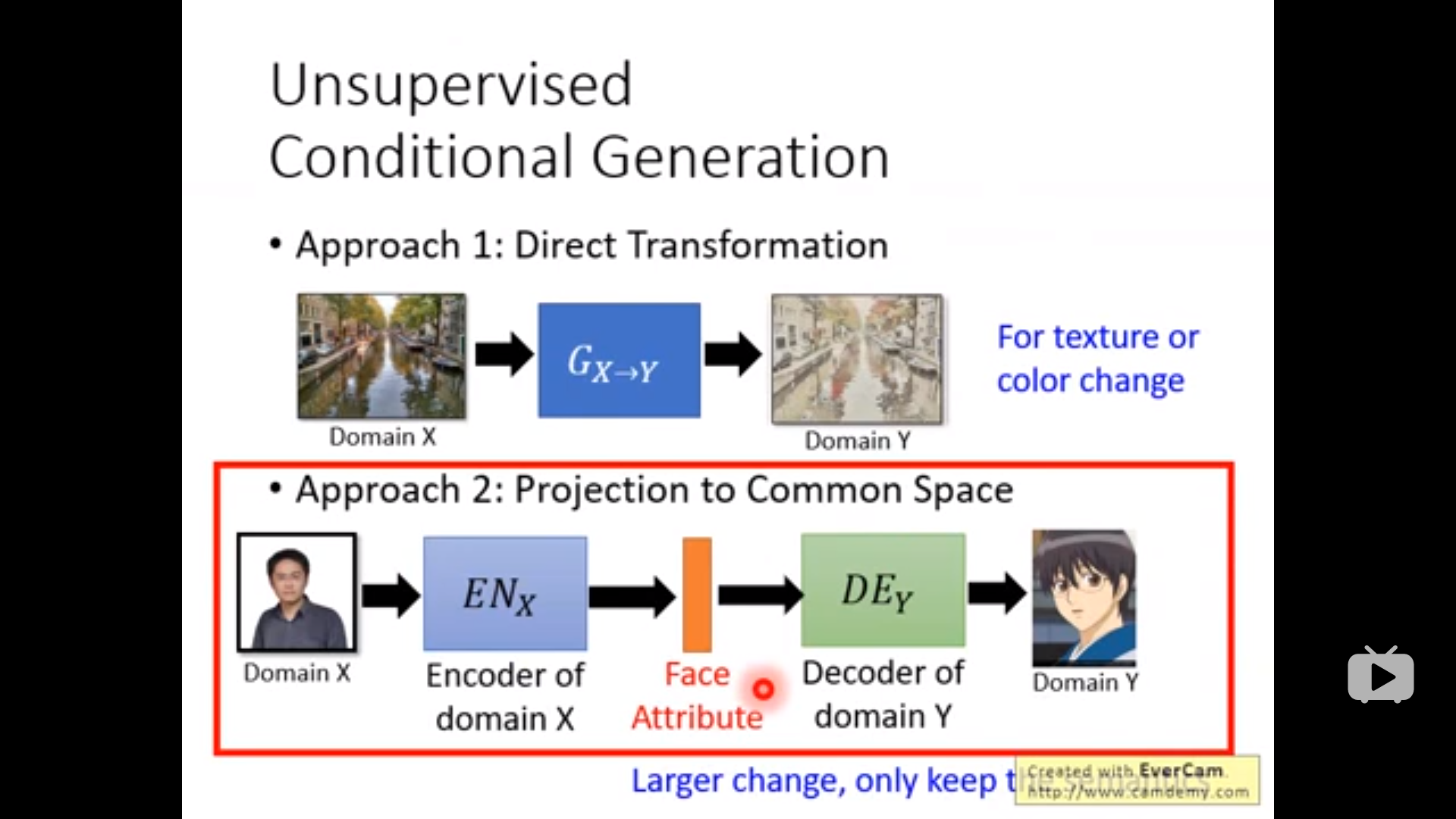
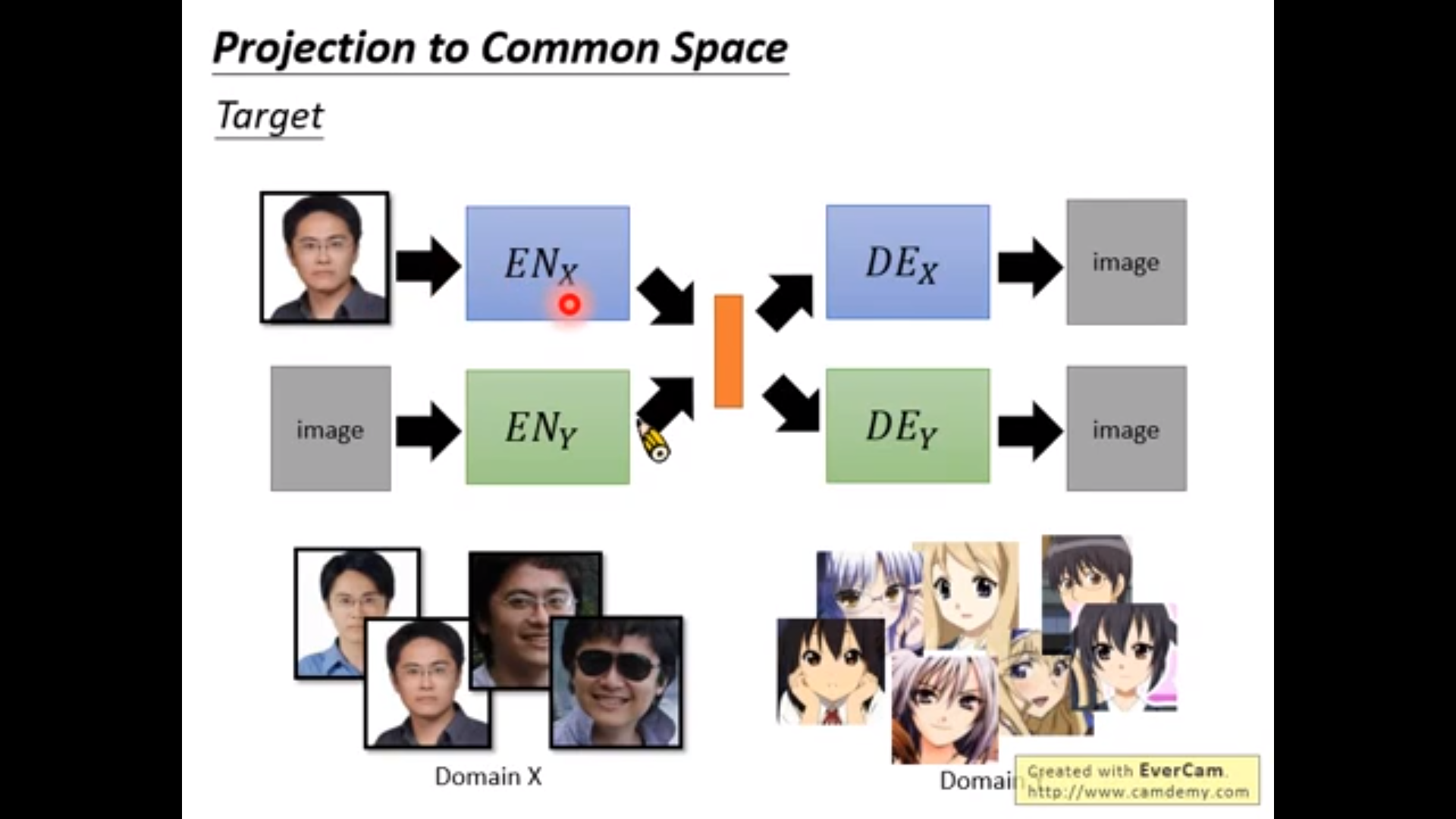
下面是一种训练方法,但是两个generator会完全没有关系
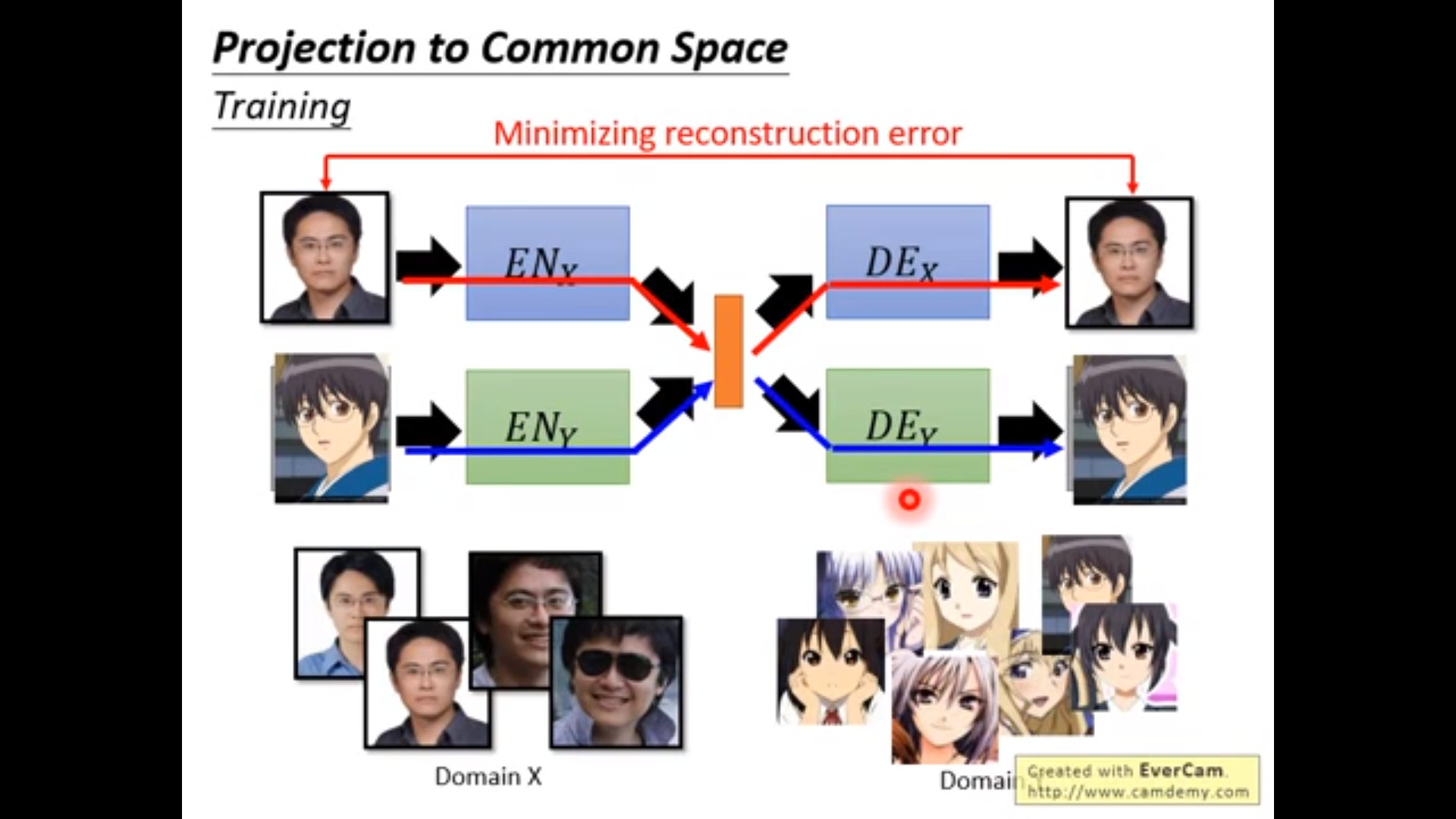
解决办法:
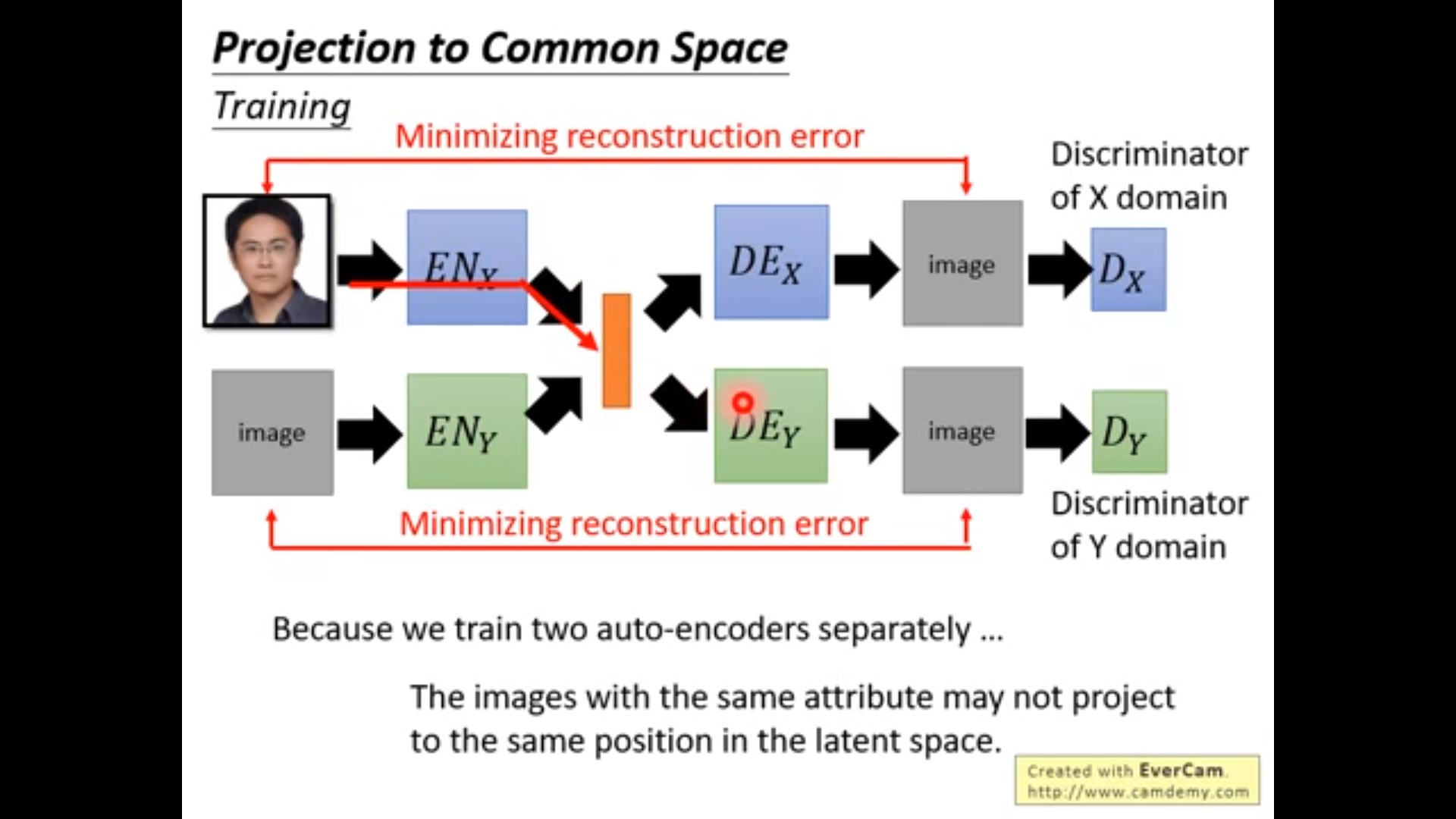
方法一:画虚线的地方share参数
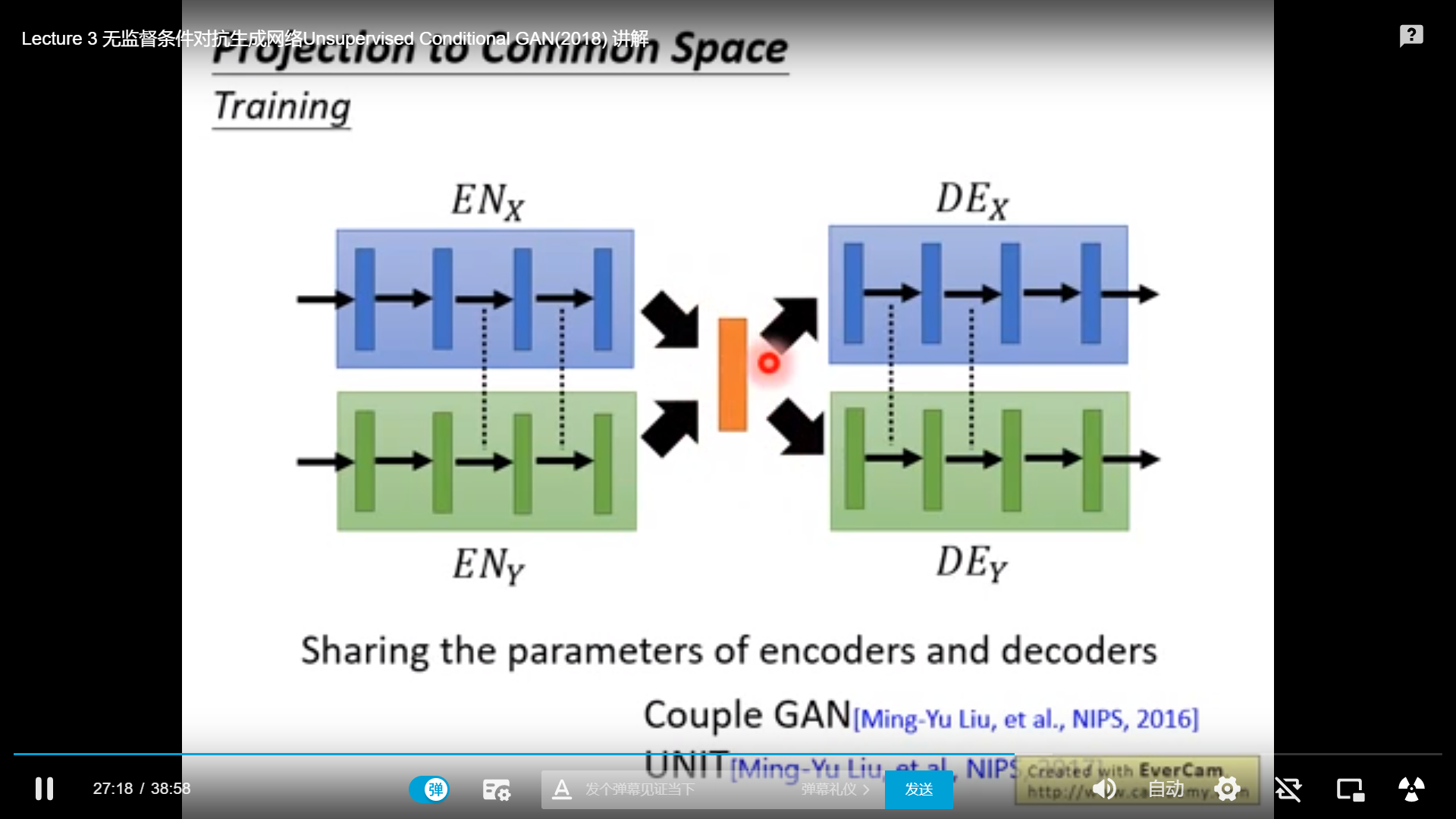
方法二:
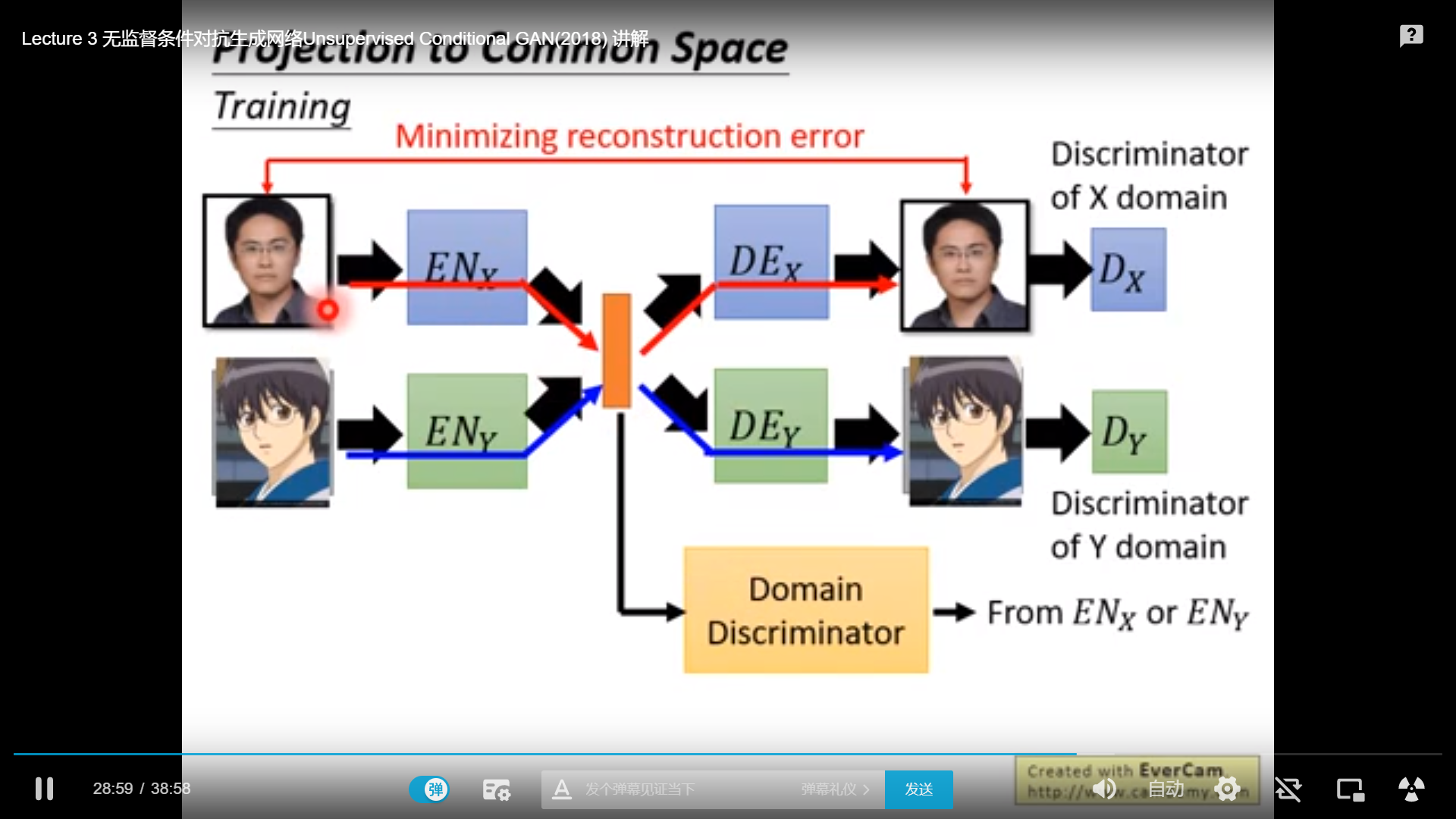
方法三:
