xpath的更多语法: https://docs.microsoft.com/zh-cn/previous-versions/dotnet/netframework-2.0/ms256039(v=vs.80)?redirectedfrom=MSDN
注意: 使用xpath helper或者chrome中的copy xpath都是从element中提取数据的,但是爬虫获取的是url对应的响应,往往和elements不一样
1.获取文本
html/head/title/text() # 获取html下head下title的文本 获取title下的文本 文本里不包含下一级
html/head/title//text() # 获取title下所有的文本 包含下一级的文本
2.获取属性
head/link/@href # 获取head下的link的href属性
3.定位
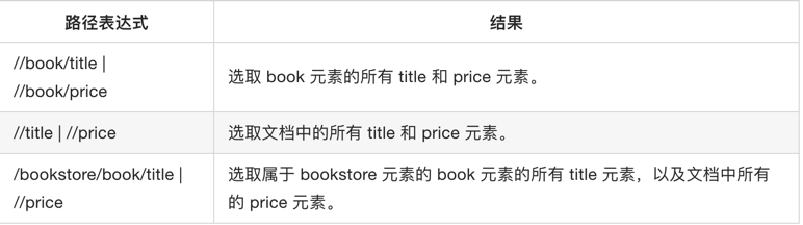
//标签名[@属性名="属性值"]
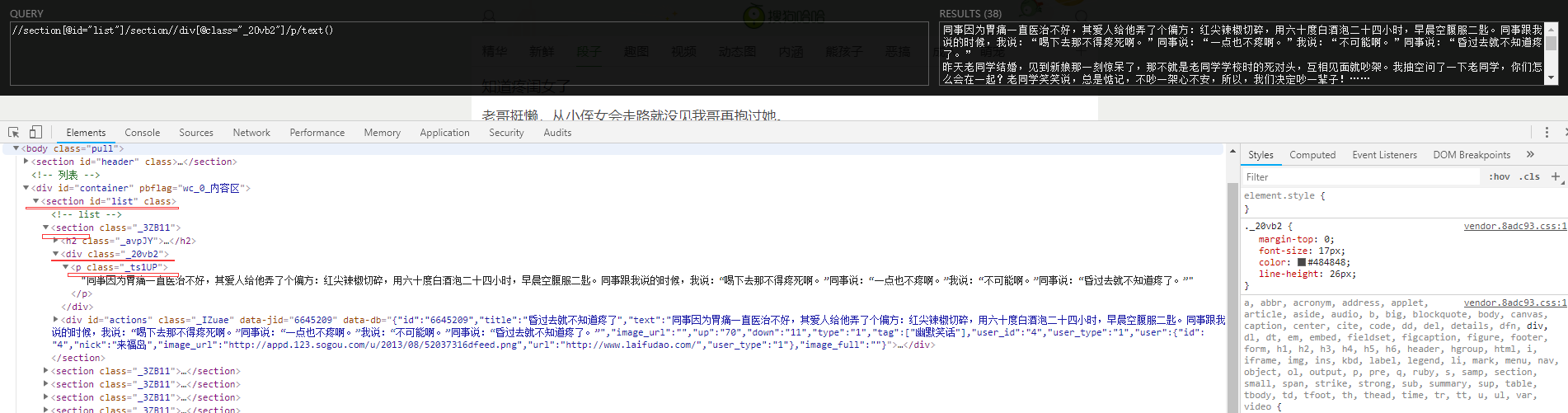
//section[@id="list"]/section//div[@class="_20vb2"]/p/text()
4.本节点"."和上一节点".."
html/head/./../body
5.根据文本内容获取标签
//a[text()="下一页"]/@href # 根据下一页文本获取a标签链接地址
6.包含
html.xpath("//li[contains(@class,'item-1')]/a/@href") # class要用小括号包住
7.节点选择语法
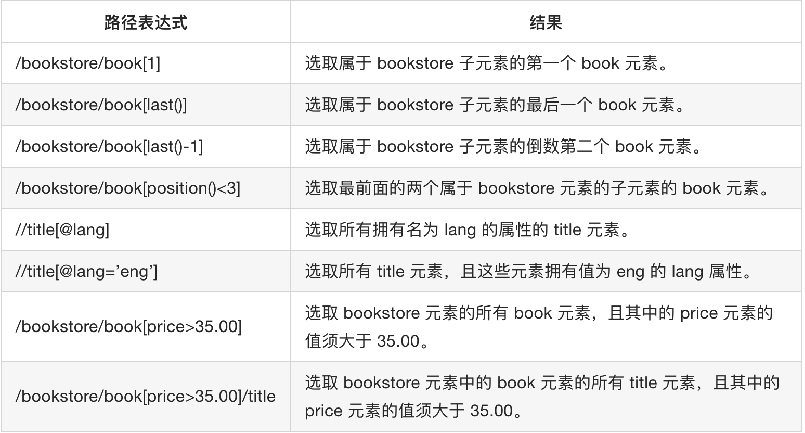
查找某个特定的节点或者包含某个指定的值的节点
选择未知节点
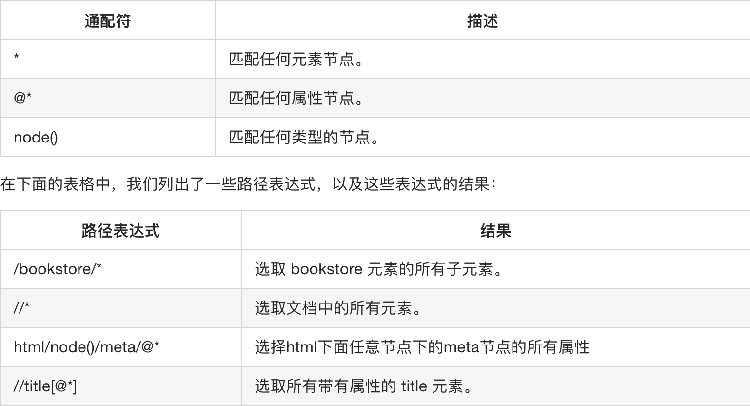
选取若干路径