一、Pandas的增删改
数据情况:

1.1 增加
1)直接赋值
# 替换掉温度的后缀℃
df.loc[:, "bWendu"] = df["bWendu"].str.replace("℃", "").astype('int32')
df.loc[:, "yWendu"] = df["yWendu"].str.replace("℃", "").astype('int32')

实例:计算温差
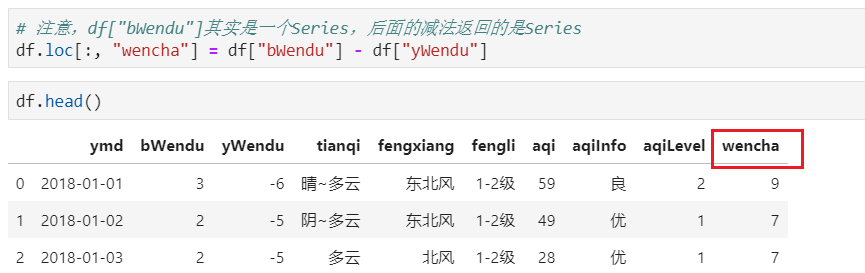
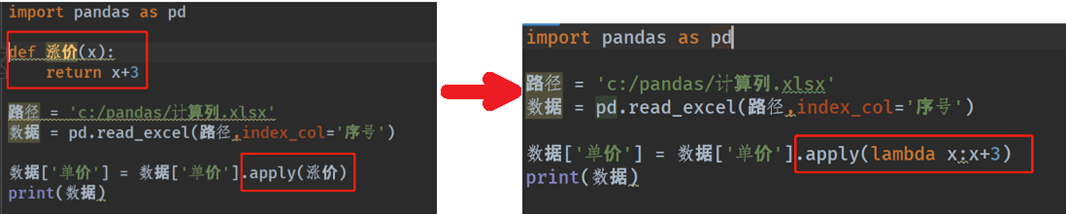
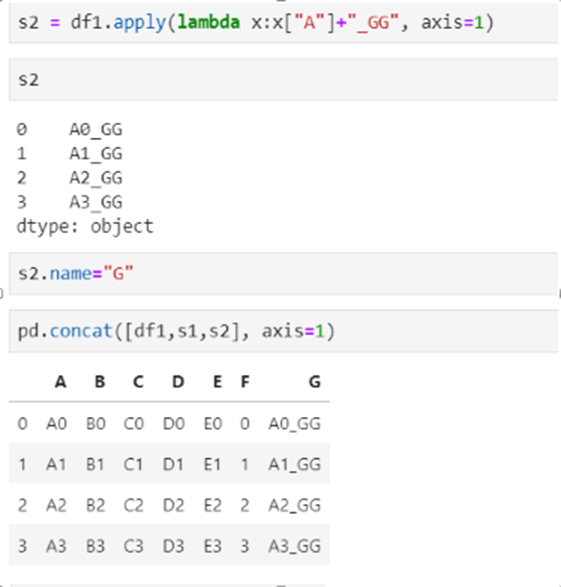
2)df.apply方法
Apply a function along an axis of the DataFrame.
Objects passed to the function are Series objects whose index is either the DataFrame's index (axis=0) or the DataFrame's columns (axis=1).
是一种函数方式变编程方法:函数作为一个对象,能作为参数传递给其它参数,并且能作为函数的返回值。例如:
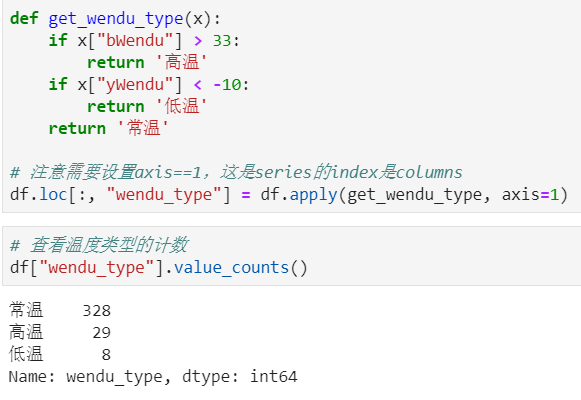
实例:添加一列温度类型:
- 如果最高温度大于33度就是高温
- 低于-10度是低温
- 否则是常温
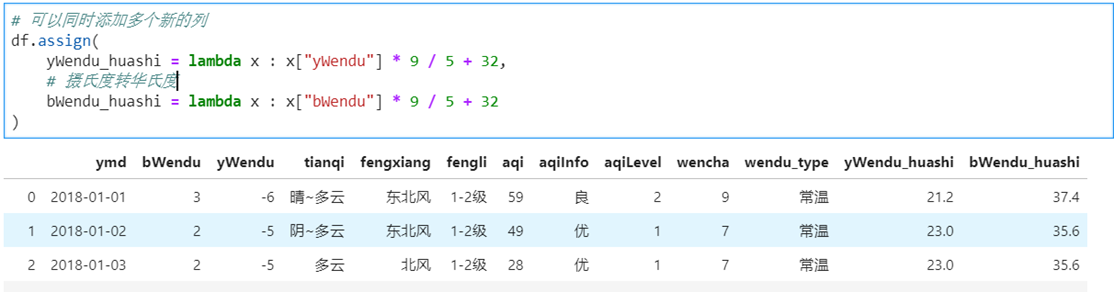
3)df.assign方法
Assign new columns to a DataFrame.
Returns a new object with all original columns in addition to new ones.
实例:将温度从摄氏度变成华氏度
4)按条件选择分组分别赋值
按条件先选择数据,然后对这部分数据赋值新列
实例:高低温差大于10度,则认为温差大

5)增加列名
df.columns = ['列名1','列名2']
6)列和行添加
列添加

行添加
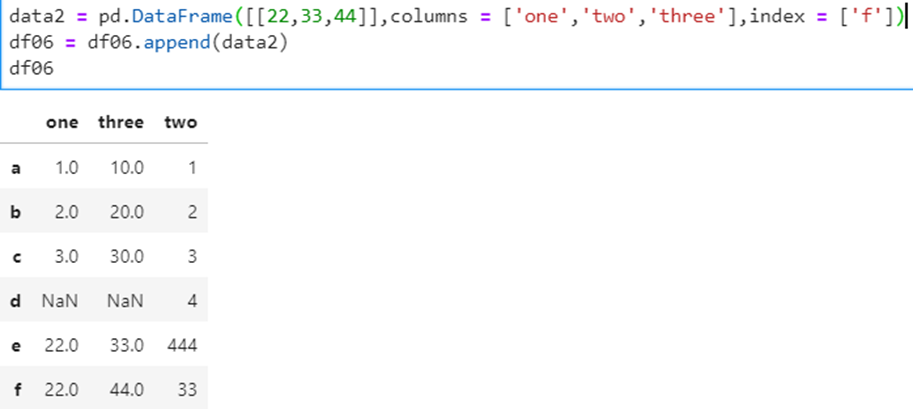
使用后面介绍的concat
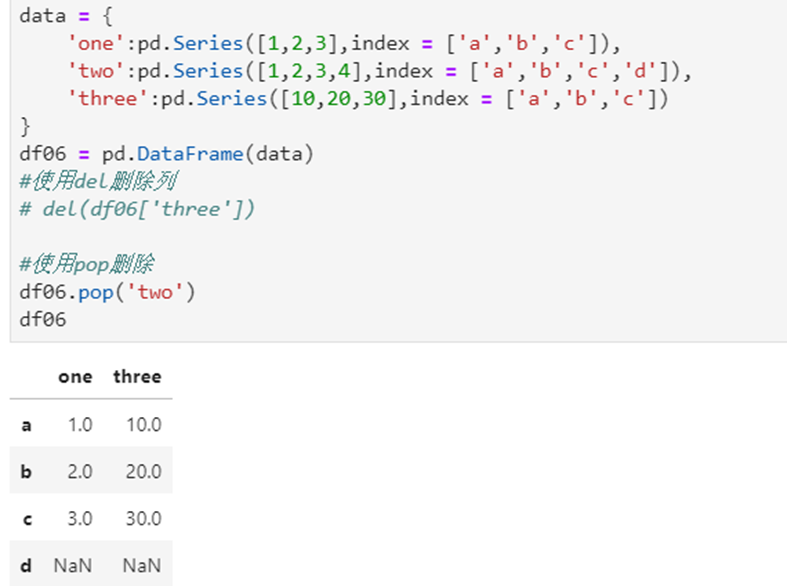
1.2 删除
列删除
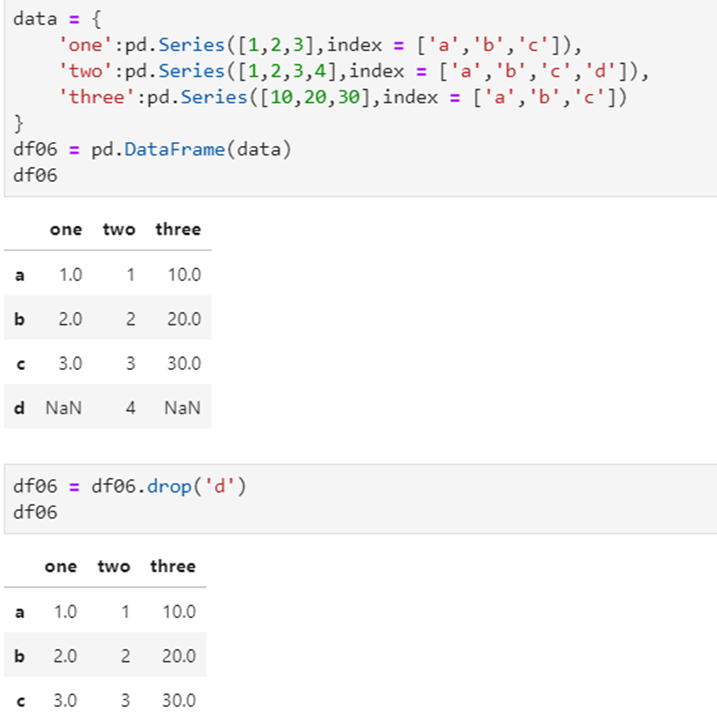
行删除drop
其实行列删除都可以:
1、删除某列或某行数据可以用到pandas提供的方法drop
2、drop方法的用法:drop(labels, axis=0, level=None, inplace=False, errors='raise')
-- axis为0时表示删除行,axis为1时表示删除列
3、常用参数如下:

注意:凡是会对原数组作出修改并返回一个新数组的,往往都有一个 inplace可选参数。如果手动设定为True(默认为False),那么原数组直接就被替换。
而采用inplace=False之后,原数组名对应的内存值并不改变,需要将新的结果赋给一个新的数组或者覆盖原数组的内存位置。
1.3 修改
1)列修改

2)修改之替换replace
1)dataframe或series都可以使用,例如
df.replace('原来的数据','新的数据',inplace=True)
2)替换的新方式
①字典替换(推荐使用)
例如:
路径 = 'c:/pandas/替换.xlsx'
数据 = pd.read_excel(路径)
字典 = {'A':20,'B':30}
数据.replace(字典,inplace=True) #字典里的建作为原值,字典里的值作为替换的新值
②列表替换
数据.replace(['A','B'],[20,30],inplace=True)
进阶:如果想要替换的新值是一样的话:数据.replace(['A','B'],30,inplace=True)
3)替换部分内容
数据['城市'] = 数据['城市'].str.replace('城八','市')
4)正则表达式替换
数据.replace('[A-Z]',88,regex=True,inplace=True)
二、Pandas数据统计函数
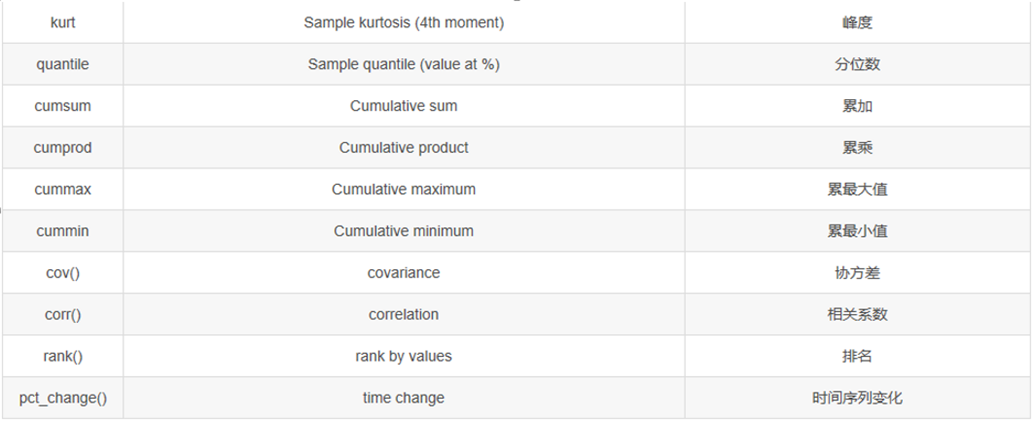
2.1 统计函数汇总

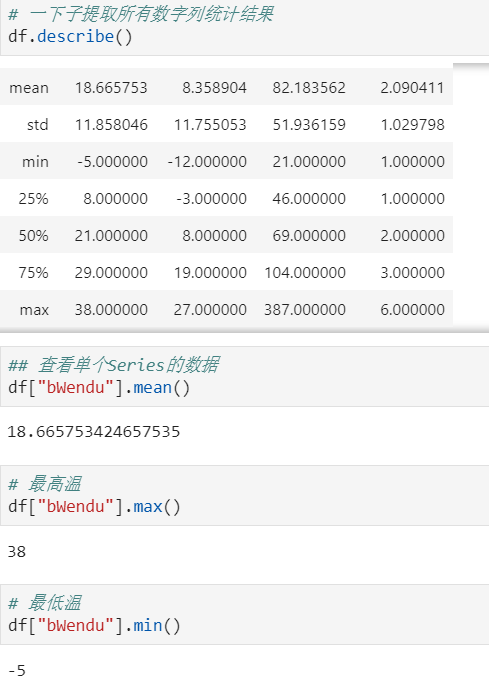
2.2 汇总类统计
原始数据

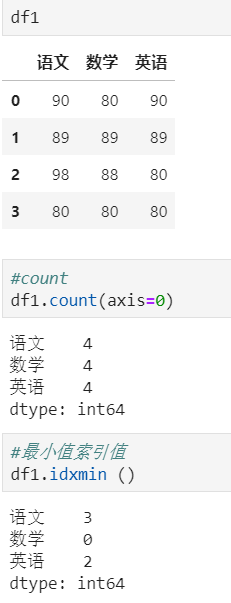
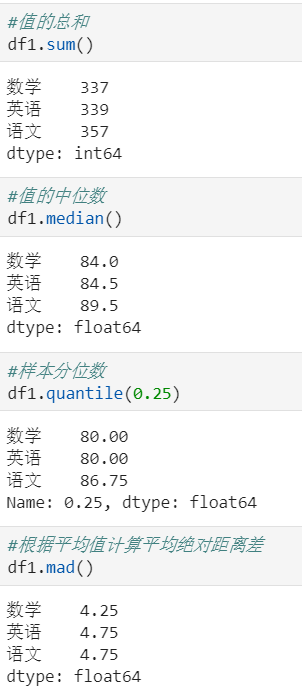
其它统计函数:
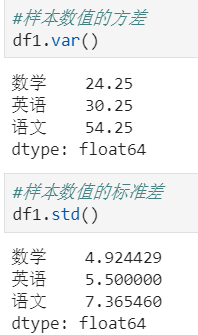
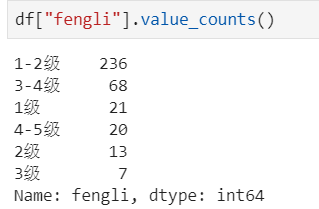
2.3 唯一去重和按值计数
唯一去重:一般不用于数值列,而是枚举、分类列

按值计数
2.4 相关系数和协方差
用途(超级厉害):
- 两只股票,是不是同涨同跌?程度多大?正相关还是负相关?
- 产品销量的波动,跟哪些因素正相关、负相关,程度有多大?
来自知乎,对于两个变量X、Y:
- 协方差:衡量同向反向程度,如果协方差为正,说明X,Y同向变化,协方差越大说明同向程度越高;如果协方差为负,说明X,Y反向运动,协方差越小说明反向程度越高。
- 相关系数:衡量相似度程度,当他们的相关系数为1时,说明两个变量变化时的正向相似度最大,当相关系数为-1时,说明两个变量变化的反向相似度最大

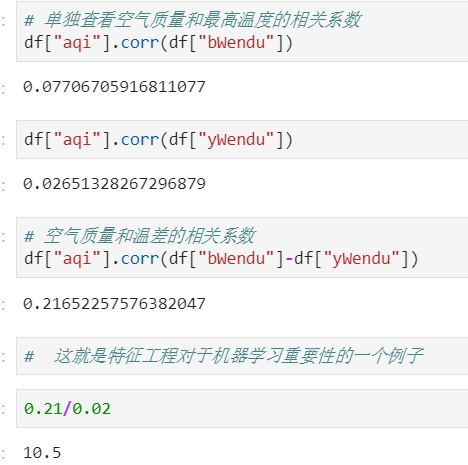
说明可以通过变量之间的运算来提取特征。
三、Pandas对缺失值的处理
Pandas使用这些函数处理缺失值:
- isnull和notnull:检测是否是空值,可用于df和series
- dropna:丢弃、删除缺失值
- axis : 删除行还是列,{0 or 'index', 1 or 'columns'}, default 0
- how : 如果等于any则任何值为空都删除,如果等于all则所有值都为空才删除
- inplace : 如果为True则修改当前df,否则返回新的df
- fillna:填充空值
- value:用于填充的值,可以是单个值,或者字典(key是列名,value是值)
- method : 等于ffill使用前一个不为空的值填充forword fill;等于bfill使用后一个不为空的值填充backword fill
- axis : 按行还是列填充,{0 or 'index', 1 or 'columns'}
- inplace : 如果为True则修改当前df,否则返回新的df
3.1 删除函数dropna
使用DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数说明:
- axis:axis=0: 删除包含缺失值的行;axis=1: 删除包含缺失值的列,默认为0,即按照行
-
how: 与axis配合使用
how='any' :只要有缺失值出现,就删除该行或列
how='all': 所有的值都缺失,才删除行或列
-
thresh: axis中至少有thresh个非缺失值,否则删除
比如 axis=0,thresh=10:标识如果该行中非缺失值的数量小于10,将删除这一行
- subset: list:在哪些列表中查看
- inplace: 是否在原数据上操作。如果为真,返回None否则返回新的copy,去掉了缺失值
举例:
print(数据.dropna()) # 删除有空值的行
print(数据.dropna(axis=1)) # 删除有空值的列
print(数据.dropna(how='all')) # 删除所有值为Nan的行
print(数据.dropna(thresh=2)) # 至少保留两个非缺失值
print(数据.dropna(subset=['语文','数学'])) # 在哪些列表中查看
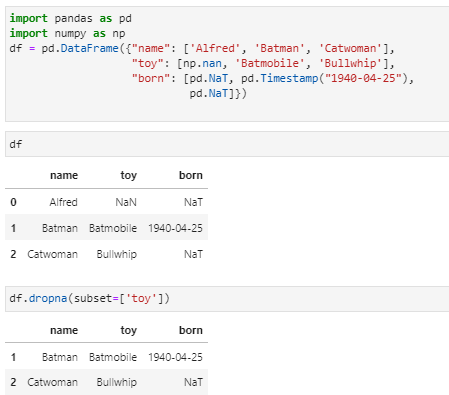
3.2 填充fillna
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
- value: scalar, dict, Series, or DataFrame dict 可以指定每一行或列用什么值填充
-
method: {'backfill', 'bfill', 'pad', 'ffill', None}, default None
在列上操作
ffill / pad: 使用前一个值来填充缺失值
backfill / bfill :使用后一个值来填充缺失值
- limit 填充的缺失值个数限制。应该不怎么用
举例:
print(数据.fillna(0)) # 用常数填充
print(数据.fillna({'语文':0.1,'数学':0.2,'英语':0.3})) # 通过字典填充不同的常数
实例:特殊Excel的读取、清洗、处理
文档:

步骤1:读取
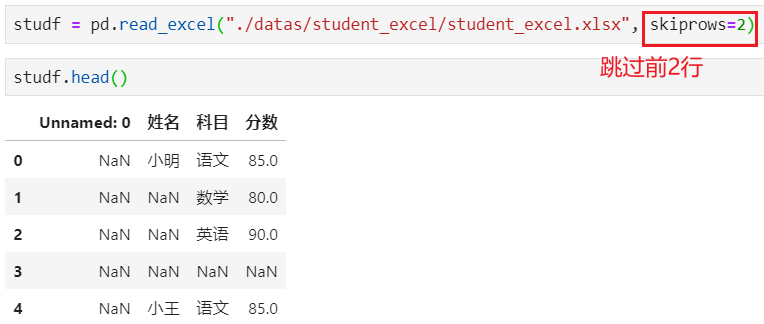
步骤2:检测空值
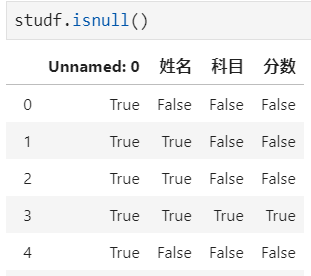
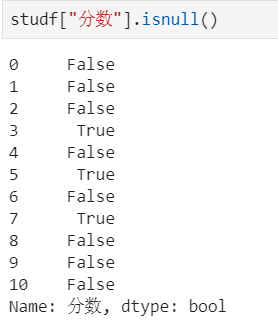
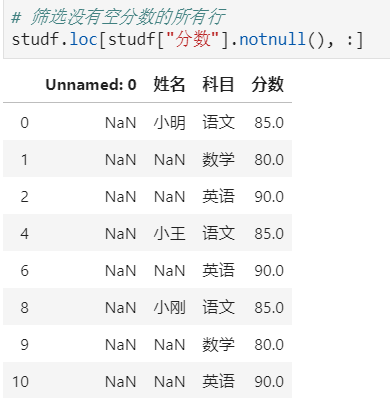
步骤3:删除掉全是空值的列
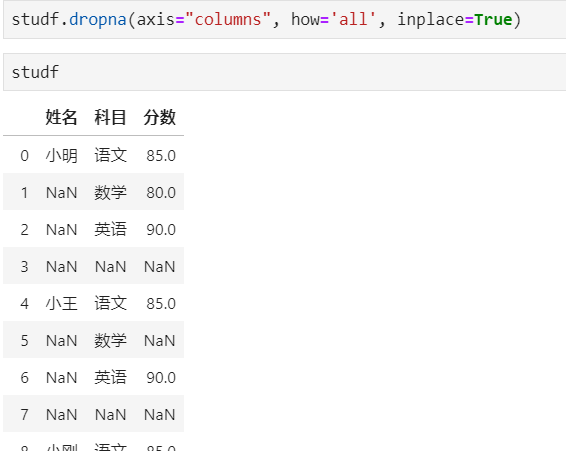
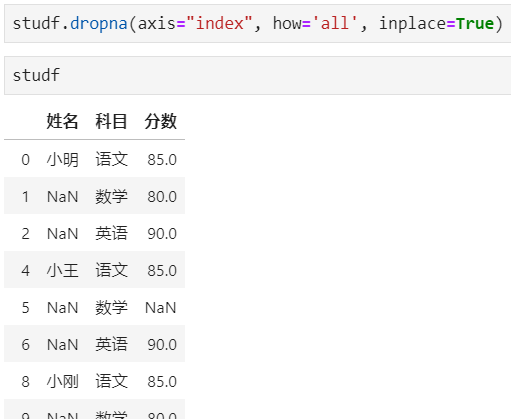
步骤4:删除掉全是空值的行
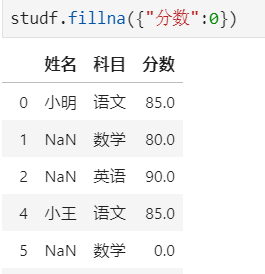
步骤5:将分数列为空的填充为0分

步骤6:将姓名的缺失值填充
使用前面的有效值填充,用ffill:forward fill

步骤7:将清洗好的excel保存

均值/中位数/众数插补
df["Age"] = df["Age"].fillna(df["Age"].median()) #中位数,若是均值使用mean,众数使用mode。
四、Pandas数据排序
1、Series的排序:
Series.sort_values(ascending=True, inplace=False)
参数说明:
- ascending:默认为True升序排序,为False降序排序
- inplace:是否修改原始Series
2、DataFrame的排序:
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last')
参数说明
- by:字符串或者List<字符串>,单列排序或者多列排序
- axis:如果axis=0,那么by="列名";如果axis=1,那么by="行号";
- ascending:True则升序,可以是[True,False],即第一字段升序,第二个降序
- inplace=True:不创建新的对象,直接对原始对象进行修改;
- inplace=False:对数据进行修改,创建并返回新的对象承载其修改结果。
- kind:排序方法,{'quicksort', 'mergesort', 'heapsort'}, default 'quicksort'。似乎不用太关心
- na_position : {'first', 'last'}, default 'last',默认缺失值排在最后面
4.1 Series的排序

4.2 DataFrame的排序
1)单列排序
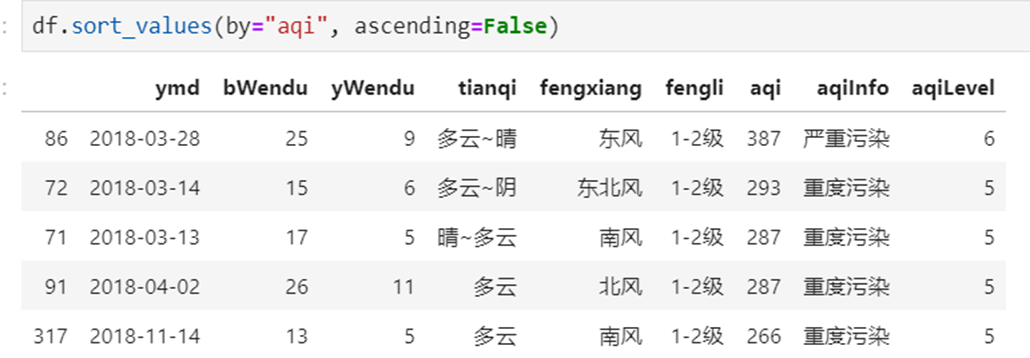
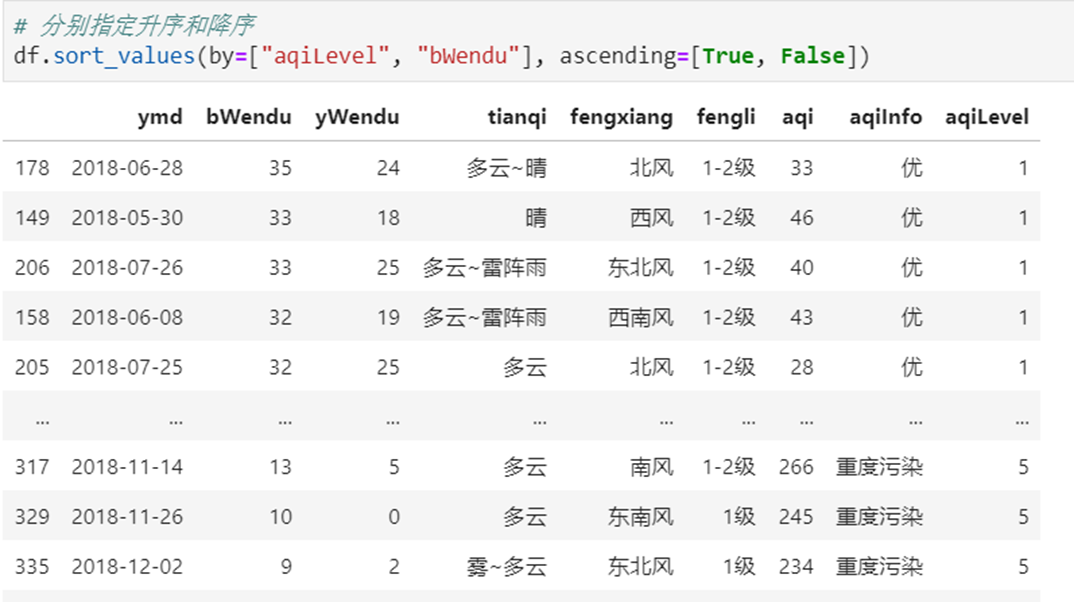
2)多列排序

还可以多个差异化排序
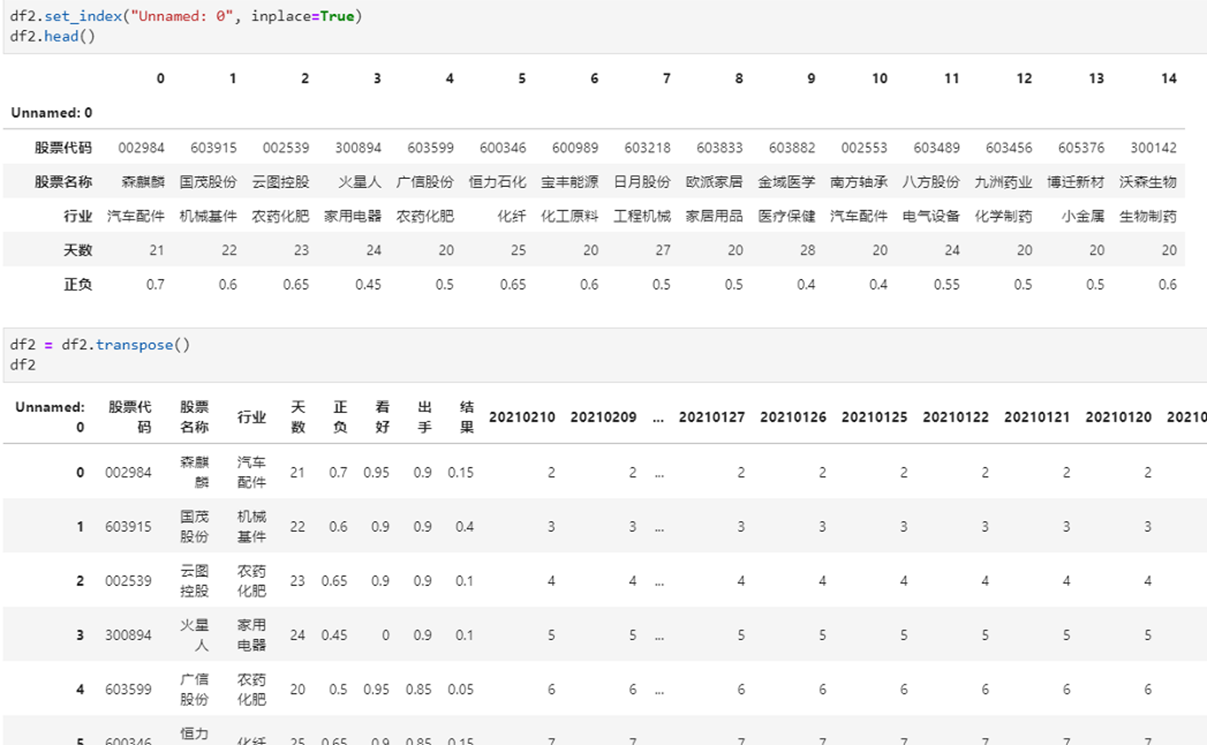
五、转置
import pandas as pd
路径 = 'c:/pandas/转换.xlsx'
数据 = pd.read_excel(路径)
数据2 = pd.DataFrame(数据.values.T,index=数据.columns,columns=数据.index)
就是使用了numpy内置的矩阵转置方法,这样的操作速度最快。
说明:直接使用:df.T 也可以。
六、重复值处理
6.1 删除重复:
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
参数
subset:用来指定特定的列,可以是多列,默认是所有列
keep:指定处理重复值的方法:
first:保留第一次出现的值
last:保留最后一次出现的值
False:删除所有重复值,留下没有出现过重复的
inplace:是直接在原来数据上修改还是保留一个副本
6.2 提取重复
DataFrame.duplicated(subset=None, keep='first')
参数
subset:用来指定特定的列,可以是多列,默认是所有列
keep:指定处理重复值的方法:
first:保留第一次出现的值
last:保留最后一次出现的值
False:删除所有重复值,留下没有出现过重复的
inplace:是直接在原来数据上修改还是保留一个副本