目录
- 研究背景
- 论文思路
- 公式推导
- 实验结果
一、研究背景
复杂句子较难做情感分析,如"我买了一部手机, 它的相机是精彩的, 但电池寿命很短", (Socher et al., 2011; Appel et al., 2016 ) 不能够捕捉到这种细微的情绪的意见目标。
再例如, "Except Patrick, all other actors don't play well ", 词"except " 和 短语"don't play well " 对 "Patrick " 产生积极的情绪。由 LSTM很难合成这些特征, 因为他们的位置是分散的基于单一注意的方法 (例如, (Wang et al., 2016) ) 也不能克服这样的困难, 因为一个attention 集中在多个单词上可能隐藏每个被关注的词的特征。
二、论文思路
2.1 论文框架:
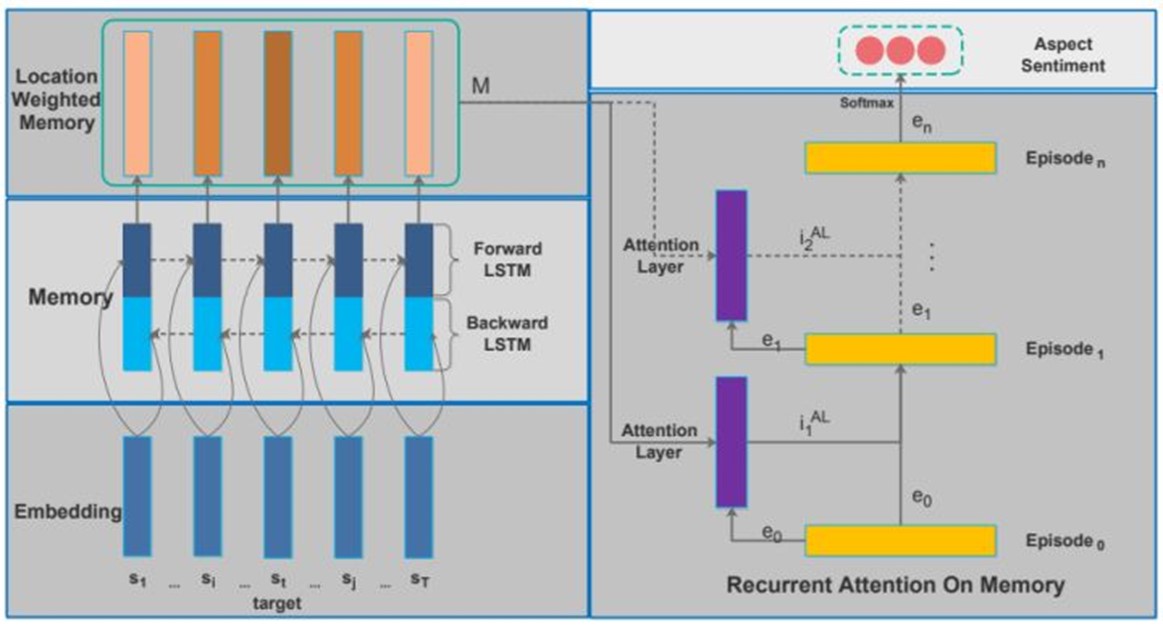
- 采用双向 LSTM (BLSTM) 从输入来产生memory
- 将memory 切片按其相对位置加权到目标, 使同一句子中的不同目标有自己的量身定做的memory 。
- 在此之后, 对位置加权memory 进行了多重attention , 并将注意力结果用recurrent network (i.e. GRUs ) 进行了非线性的结合。
- 最后, 对 GRU 网络的输出进行了 softmax, 以预测目标的情绪。
2.2 技术特点:
1、多重注意机制的方法来合成难句结构中的重要特征--使得较远的信息也能理解;
对比1:MemNet-Tang et al. (2016) ,这篇文章也采用了多重关注的思想,但他们的向量提供给 softmax 用作分类的仅仅是最后的attention , 本质上是输入向量的线性组合。而本文模型将多重关注的结果与 GRU 网络相结合, 它从 RNNs 中继承了不同的行为, 如遗忘、维护和非线性变换, 从而使预测精度更高。
对比2:(Wang et al.,2016; Tang et al., 2016)。本文不同点:其一,我们在输入和attention 层加入了memory module。因此我们能识别语句的合成特征(比如:"not wonderful enough")),其二(更重要的):我们用一种非线性的方法把注意的结果结合起来,(Wang et al.,2016; Tang et al., 2016)用的是单层,我们用过的是多层。
2、标准化attention
对比:(Kumar et al., 2015)也使用了多层,但是它将attention分数独立地分配到记忆片上,其attention处理更加复杂,而我们生成一个标准化的attention分布来处理来自记忆的信息。
2.3 论文测试集
四个数据集:
对餐厅领域 来自SemEval 2014 (Pontiki et al., 2014)
笔记本电脑领域的评论 来自SemEval 2014 (Pontiki et al., 2014)
一组推特数据, 收集由 (Dong et al., 2014)
一个中国新闻评论的数据集
三、公式推导
3.1 输入部分

d是单词的维度,V是词向量大小。
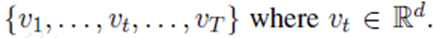
L可能被模型调整。如果不进行调整,该模型可以利用原始嵌入空间中显示的单词相似性。如果它被调优,我们预计模型将捕获一些对情绪分析任务有用的内在信息。
3.2 BLSTM for Memory Building
利用的其实就是 BLSTM,没有什么特殊的地方:
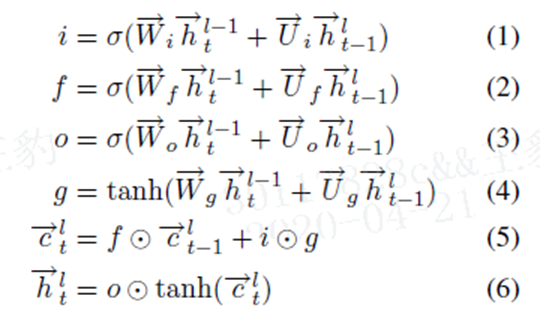
i,f,o分别表示是否更新当前输入数据,是否在memory cell中忘记这些信息,再memory cell中的信息是否传递到输出。
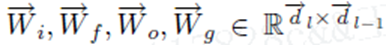

dl表示前向LSTM中第l层的隐藏cells。 反向的LSTM做同样的事情,除了输入时反向的。最终的memory生成的为下式,表示两者h的结合。

3.3 Position-Weighted Memory
一个单词离目标越近,其记忆的权重就越高。我们将距离定义为单词与目标之间的单词数。一下是t单词对应的权值,这在上式中已经体现作用。

其中 tmax 为输入句子的最大长度
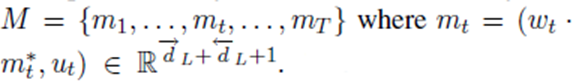
加权记忆的目的是提高近距离的感叹词的权重,而recurrent attention module(下面将讨论)则用于处理远距离的感叹词。因此,他们一起工作,期望更好的预测精度
3.4 Recurrent Attention on Memory
要准确预测一个目标的情绪,关键是:
- 正确地从它的位置加权存储器中提取相关信息;--采取多层attention解决
- 适当制作情感分类等信息输入:采用GRU(有更少的参数)与attention结果非线性结合
每次attention后,用GRU更新episode e:
输入值有两个:
1、初始的e0都是0向量
2、3.3输出的M矩阵


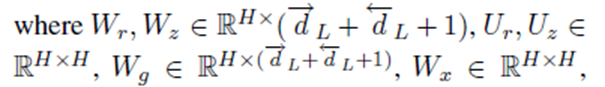
H是隐藏层的大小。我们计算每个记忆片的归一化的为:
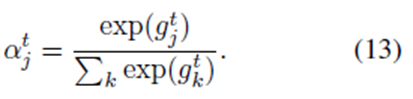
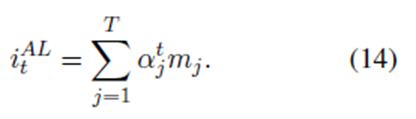
3.5 Output and Model Training
在memory经过N次attention后,将最后的en输入到softmax中进行分类。
损失函数为交叉熵损失和正二则化得方式:
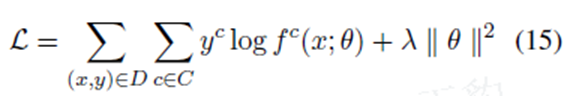
C是分类的数量,D是训练的数据集,y是ont-hot编码的向量,f是模型预测情感分析的类。
四、实验结果
4.1 主要结果
方法比 MemNet 在所有四数据集上的性能都好, 特别是在新闻评论数据集上, 其改进超过了10%。

4.2 Attention Layers 的效果

4.3 Embedding Tuning 的效果
比较的嵌入优化策略有:
· RAM-3AL-T-R: 它不预先训练单词嵌入, 而是随机初始化嵌入, 然后在受监督的训练阶段对其进行微调。
· RAM-3AL-T: 最初使用预训练的嵌入, 并且在训练中也进行了调整。
· RAM-3AL-NT: 训练中未调整预训练的嵌入。