1. Spring MVC和Struts2的区别
* SpringMVC是方法级别的拦截,一个方法对应一个request上下文,方法独享req/res,结果通过ModelMap交回框架,方法间不共享变量。
* Struts2是类级别拦截,一个请求创建一个Action,一个Action对象对应一个request上下文,且Action变量是共享的。
* SpringMVC拦截器有用的独立的AOP。Struts2拦截器有自己的interceptor机制
* SpringMVC的入口是Servlet,Struts2是Filter
* SpringMVC集成了Ajax,通过@ResponseBody就可以实现,直接返回响应文本。
* Struts2把request/session等变量封装成一个个Map,给每个Action使用,保证线程安全,原则上是比较耗费内存的。
* SpringMVC非线程安全,Struts2线程安全。
3. Cookie和Session的共同点、区别及联系(生命周期)?
共同点:
都是为了保持访问用户与后端服务器的交互状态(HTTP是一种无状态协议)。
> cookie保存在浏览器中,不安全。而session是保存在服务端的。
> session是基于cookie发送的。
> cookie的生命周期很长,而session很短,一般也就几十分钟。
区别及联系(生命周期):
Cookie是用户访问服务器,服务器将K-V返回给客户端并加上一些限制条件,客户端下次访问将带着完整数据返回。
Session是基于Cookie来工作的,Session是客户端第一次访问服务器生成(第一次通过request.getSession生成)的默认名为"JSESSIONID"值为sessionId值的K-V(HttpSession)并回传(response)给客户端,客户端每次访问服务端时,就只用带着这一个K-V即可
4. Session生命周期
服务端收到用户请求后,会检查catalina.Manager(实现类StandManager)的sessions窗口中是否有SessionId标识,如果有则说明之前已为客户端建立过Session(若没有则会新建一个Session),在客户端得到SessionId后,会从StandManager对象的Session集合中试图找到和SessionId对应的Session对象,没有则会新建一个Session对象,加入Manager的Session集合,并将SessionId随着response一起返回给客户端。
Session对象的生命周期由org.apache.catalina.Manager进行管理,所有HttpSession对象与SessionId对应
StandardManager类负责Servlet容器中所有的StandardSession对象的生命周期管理。当Servlet容器重启或关闭时,StandardManager负责持久化没有过期的StandardSession对象,它会将所有的StandardSession对象持久化到一个以"SessionS.ser"为文件名的文件中,到Servlet容器重启时,也就是StandardManager初始化时,它会重新读取这个文件,解析出所有Session对象,重新保存在StandardManager的sessions集合中。
5. 如何设置Cookie和Session的时长
* Cookie什么时候会关闭?
> a 默认cookies失效时间是直到关闭浏览器,cookies失效,也可以指定cookies时间。
Cookie c = new Cookie("userAge", "16"); c.setMaxAge(58); httpServletResponse.addCookie(c);
* Session什么时候会关闭?
> a 默认Session保存在服务器端默认失效时间是30分钟,和浏览器没有关系,也可以指定session时间,超时则关闭。
> b 程序调用httpSession.invalidate();
> c 服务器被停止
方法一:
httpSession.setMaxInactiveInterval(50);
方法二:
<session-config> <session-timeout>30</session-timeout> </session-config>
6. Collection类和接口
List:
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, Serializable{} public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, Serializable{} public class Vector<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, Serializable
Set:
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, Serializable{} //内部实现使用HashMap的key public class LinkedHashSet<E> extends HashSet<E> implements Set<E>, Cloneable, Serializable public class TreeSet<E> extends AbstractSet<E> implements NavigableSet<E>, Cloneable, Serializable
Map:
public class HashMap<K, V> extends AbstractMap<K, V> implements Map<K, V>, Cloneable, Serializable //Entry public class TreeMap<K, V> extends AbstractMap<K, V> implements NavigableMap<K, V>, Cloneable, Serializable //根据key排序,默认是按升序排序 public class ConcurrentHashMap<K, V> extends AbstractMap<K, V> implements ConcurrentMap<K, V>, Serializable //线程安全的HashMap代替HashTable public class LinkedHashMap<K, V> extends HashMap<K, V> implements Map<K, V> //有序,记录的插入顺序,在遍历的时候会比HashMap慢 public class Hashtable<K, V> extends Dictionary<K, V> implements Map<K, V>, Cloneable, Serializable
7. 集合有哪些?ArrayList和LinkedList的区别?
ArrayList内部使用数组实现
LinkedList内部使用链表实现
Vector内部使用数组实现但线程安全
HashSet内部使用HashMap实现,放入HashSet中的集合元素实际上由HashMap的key来保存,而HashMap的value则存储了一个PRESENT,它是一个静态的Object对象。所以向HashSet中添加一个已经存在的元素不会覆盖原来已有的集合元素。
TreeSet是一个内部元素排序版的HashSet
TreeMap是一个内部元素排序版的HashMap
HashMap是非线程安全
HashTable是synchronized
LinkedHashMap和LinkedHashSet 是有序的。
8. 线程安全的集合有哪些?
1)HashMap
a)ConcurrentSkipListMap
跳表,这是一个Map,使用跳表的数据结构进行快速查找
跳表实现Map和哈希算法实现Map不同之处:哈希并不会保存元素的顺序,而跳表内所有元素都是排序的(根据key进行排序)。所以,如果需要有序性,跳表是不2选择。
b)ConcurrentHashMap
高效的并发HashMap,可以理解为一个线程安全的HashMap
public static Map map1 = Collections.synchronizedMap(new HashMap()); ConcurrentHashMap<String, String> map123 = new ConcurrentHashMap<String,String>();
以ConcurrentHashMap为例,它内部进一步细分了16个段(SEGMENT),如果要在ConcurrentHashMap中增加一个新的表项,并不是将整个HashMap加锁,而是首先根据hashcode得到该表项应该存放在哪个段中,然后对该段加锁,并完成put()操作,在多线程环境中,如果多个线程同时进行put操作,只要被加入的表项不存在同一个段中,则线程间便可以做到真正的并行,由于默认16个段,如果幸运的话,ConcurrenthashMap可以同时接受16个线程同时插入(如果都插入不同的段中),从而大大提供其吞吐量。缺点正是由于它有16个段管理各个表项,导致它在计算size()时,必须得到16个段的锁,
2)List
a)CopyOnWriteArrayList
高效读取,在读多写少的场合,这个List的性能非常好,远远好于Vector。
List<String> l2 = Collections.synchronizedList(new ArrayList<String>());
3)队列
a)ConcurrentLinkedQueue
高效读写队列,高效的并发队列,使用链表实现,可以看做一个线程安全的LinkedList。
b)BlockingQueue
数据共享通道,这是一个接口,JDK内部通过链表、数组等方式实现了这个接口,表示阻塞队列,非常适合用于作为数据共享的通道。
* ArrayBlockingQueue:基于数组实现的,适合做有界队列,
* LinkedBlockingQueue:基于链表实现的,适合做无界队列,
BlockingQueue,压入数据:
offer():当队列满了,返回false,当队列没满,正常执行。
put():当队列满了,进入等待状态,直到队列有空余位置。
BlockingQueue,弹出数据,会从队列的头部获得一个元素:
pool():当队列为空时,返回null
take():当队列为空时,进入等待状态
9. Get和Post的区别?哪个会产生编码问题?
GET只允许 ASCII 字符。POST没有限制。GET的QueryString解码字符集默认的ISO-8859-1。POST是通过BODY传递到服务端的,解码用Header下ContentType的Charset编码格式。
GET对URL的长度是受限制的(URL 的最大长度是 2048 个字符)。POST无限制。
GET所发送的数据是URL的一部分,使用URL传参。POST比GET更安全,因为参数在HttpBody中,不显示出来,安全性高些。
因为GET从语义上是读操作,用于获取指定URL上的资源,状态是不会改变的,所以Get是安全的,GET返回的内容可以被浏览器、Cache服务器缓存起来。因发送参数和地址都一致,故IE浏览器会从缓存中取
POST语义是追加/添加数据,所以是不安全的,每次提交POST,参与的代码都会认为这个操作会修改操作对象资源的状态,于是,POST是不安全的,返回的内容不会被缓存
10. 线程的几种状态,及如何创建线程
* 新建状态(New):
当用new操作符创建一个线程时, 例如new Thread(r),线程还没有开始运行,此时线程处在新建状态。 当一个线程处于新生状态时,程序还没有开始运行线程中的代码
* 就绪状态(Runnable)
当线程对象调用start()方法即启动了线程,start()方法创建线程运行的系统资源,并调度线程运行run()方法。当start()方法返回后,线程就处于就绪状态。
处于就绪状态的线程并不一定立即运行run()方法,线程还必须同其他线程竞争CPU时间,只有获得CPU时间才可以运行线程。
* 运行状态(Running)
当线程获得CPU时间后,它才进入运行状态,真正开始执行run()方法.
* 阻塞状态(Wait/Sleep Blocked)
线程运行过程中,可能由于各种原因进入阻塞状态:
1>线程调用sleep(30)进入睡眠状态。--------属于线程类(Thread)的方法!!!!!!
2>调用yield()静态方法。
3>b线程调用a.join(),等待a线程走完,再走下去
4>wait/notify,线程调用一个对象的wait方法将进入阻塞,直到该对象的notify方法被调用。-----属于Object类的方法!!!!!!!!!
所谓阻塞状态是正在运行的线程没有运行结束,暂时让出CPU,这时其他处于就绪状态的线程就可以获得CPU时间,进入运行状态。
* 死亡状态(Dead)
1) run方法正常退出而自然死亡,
2) 一个未捕获的异常终止了run方法而使线程猝死。
为了确定线程在当前是否存活着(就是要么是可运行的,要么是被阻塞了),需要使用isAlive方法。如果是可运行或被阻塞,这个方法返回true; 如果线程仍旧是new状态且不是可运行的, 或者线程死亡了,则返回false.
11. 如何设置线程优先级
thread.setPriority(); // 1~10级,默认5级
12. 几种常用的数据结构及内部实现原理?
链表:一个链表由很多节点组成,每个节点包含表示内容的数据域和指向下一个节点的链域两部分。正是通过链域将节点连接形成一个表。围绕链表的基本操作有添加节点、删除节点和查找节点等。
堆栈:限定了只能从线性表的一端进行数据的存取,这一端称为栈顶,另一端为栈底。 入栈操作是先向栈顶方向移动一位,存入数据;出栈操作则是取出栈顶数据,然后向栈底移动一位。体现LIFO/FILO的思想。
队列:限定了数据只能从线性表的一端存入,从另一端取出。存入一端成为队尾,取出一端称为队首。体现LILO/FIFO的思想。
二叉树:树中的每个节点最多有两个子节点。这两个子节点分别称为左子节点和右子节点。在建立二叉搜索树时,要求一个节点的左子节点的关键字值小于这个节点而右子节点的关键字值大于或等于这个节点。常见的遍历操作有前序、中序和后序遍历。
13. JVM优化策略
1)Minor/Full GC的时间足够的小
2)Minor/Full GC的次数足够的少
3)发生Full GC的周期足够的长
1和2相悖论,要想GC时间小必须要一个更小的堆,要保证GC次数足够少,必须保证一个更大的堆,我们只能取其平衡。
64位操作系统最大能支持128G内存,
堆内存变大后,虽然垃圾收集频率减少,但垃圾回收的时间变长。如果对内存为14G,那么每次Full GC将长达数十秒。
因此,对于使用大内存的程序来说,一定要减少Full GC的频率,如果每天只有一两次Full GC,而且发生在半夜, 那完全可以接受。要减少Full GC的频率,就要尽量避免太多对象进入老年代,可以有以下做法:
a)确保对象都是“朝生夕死”的
b)一个对象使用完后应尽快让他失效,然后尽快在新生代中被Minor GC回收掉,尽量避免对象在新生代中停留太长时间。
c)提高大对象直接进入老年代的门槛
d)通过设置参数-XX:PretrnureSizeThreshold来提高大对象的门槛,尽量让对象都先进入新生代,然后尽快被Minor GC回收掉,而不要直接进入老年代。
-Xms1280m -Xmx1280m -XX:NewSize=500m -XX:MaxNewSize=500m
-XX:PretrnureSizeThreshold:设计大过指定大小的对象之间进入老年代
MaxTenuringThreshold:设置超过这个年龄的会进入老年代。minor GC每进行一次,存活下来的对象年龄+1,默认年龄超过15的会进入老年代。
-vmargs -Xms128M -Xmx512M -XX:PermSize=64M -XX:MaxPermSize=128M
-vmargs 说明后面是VM的参数,所以后面的其实都是JVM的参数了
-Xms128m JVM初始分配的堆内存
-Xmx512m JVM最大允许分配的堆内存,按需分配
-XX:PermSize=64M JVM初始分配的非堆内存
-XX:MaxPermSize=128M JVM最大允许分配的非堆内存,按需分配
14. Spring如何实现事务管理的?
Spring 的事务,可以说是 Spring AOP 的一种实现。基本原理如下
public class TxHandler implements InvocationHandler { private Object originalObject; public Object bind(Object obj) { this.originalObject = obj; return Proxy.newProxyInstance(obj.getClass().getClassLoader(),obj.getClass().getInterfaces(),this); } public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { Object result = null; if (!method.getName().startsWith("save")) { UserTransaction tx = null; try { tx = (UserTransaction) (new InitialContext().lookup("java/tx")); result = method.invoke(originalObject, args); tx.commit(); } catch (Exception ex) { if (null != tx) { try { tx.rollback(); } catch (Exception e) { } } } } else { result = method.invoke(originalObject, args); } return result; } }
Spring的事务管理机制实现的原理,就是通过这样一个动态代理对所有需要事务管理的Bean进行加载,并根据配置在invoke方法中对当前调用的 方法名进行判定,并在method.invoke方法前后为其加上合适的事务管理代码,这样就实现了Spring式的事务管理。Spring中的AOP实 现更为复杂和灵活,不过基本原理是一致的。
15. Spring IOC原理
IOC控制反转:控制的什么被反转了?就是:获得依赖对象的方式反转了,由Spring容器来实现这些相互依赖对象的创建、协调工作;
IOC的一个重点是在系统运行中,动态的向某个对象提供它所需要的其他对象。这一点是通过DI(Dependency Injection,依赖注入)来实现的。
依赖注入是通过反射机制实现的,在实例化一个类时,它通过反射调用类中set方法将事先保存在HashMap中的类属性注入到类中。
16. Spring AOP原理
AOP面向切面编程,是基于动态代理(由Java反射机制生成)实现的,AOP对业务逻辑中的各个部分切割隔离,使耦合度降到最低,增强了系统的重用性和可维护性。
AspectJ使用案例:
<aop:aspectj-autoproxy/> @Aspect @Pointcut("execution(** spittr2.web.action.HomeAction.*(..))") @Before("pointBase()") @AfterReturning("pointBase()") @AfterThrowing(value="pointBase()",throwing="ex") @Around("pointBase()")
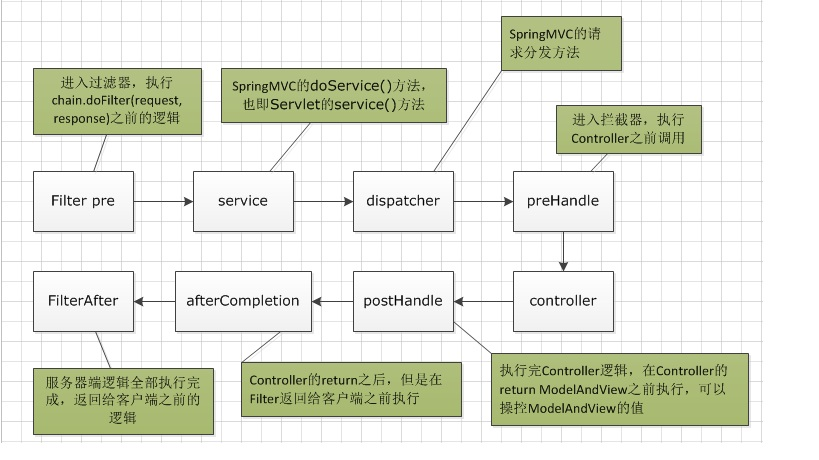
17. 过滤器和拦截器的区别
拦截器是基于java的反射机制的,而过滤器是基于函数回调;
拦截器不依赖与servlet容器,过滤器依赖与servlet容器;
拦截器只能对Action/Controller请求起作用,而过滤器则可以对几乎所有的请求起作用;
拦截器可以访问Action/Controller上下文、值栈里的对象,而过滤器不能访问;
在Action生命周期中,拦截器可以多次被调用,而过滤器只能在容器初始化时调用一次;
18. 存储过程样例
CREATE PROCEDURE pro_name(IN id INTEGER,IN year VARCHAR(30),OUT totalSize INTEGER) BEGIN DECLARE age INT DEFAULT 0; DECLARE t_name VARCHAR(50); DECLARE sqlStr varchar(4000) default ''; DECLARE error_num INTEGER DEFAULT 0; -- 是否有错误发生 DECLARE CONTINUE HANDLER FOR SQLEXCEPTION SET error_num = 1; -- 当发生异常时将error_num设成1 START TRANSACTION; -- 开启事务 IF id=1 THNE SET t_name = CONCAT('t_ace_appraise',LEFT(year,2)); IF EXISTS (SELECT 1 FROM information_schema.`TABLES` where TABLE_NAME=t_name) SET sqlStr = CONCAT(sqlStr,"select ....."); END IF; END IF; SET sqlStr2 = CONCAT("select count(*) into @totalSize from (",sqlStr,") as tc") SET @sql2 = sqlStr2 ; -- 注意很重要,将连成成的字符串赋值给一个变量(可以之前没有定义,但要以@开头) PREPARE stat2 FROM @sql2; -- 预处理需要执行的动态SQL,其中stmt是一个变量 EXECUTE stat2; -- 执行SQL语句 DEALLOCATE PREPARE stat2; -- 释放掉预处理段 END
20.mybatis中#和?的区别
因为MyBatis启用了预编译功能,所以
#{}:在预编译过程中,会把#{}部分用一个占位符?代替,执行时,将入参替换编译好的sql中的占位符“?”,能够很大程度防止sql注入
${}:在预编译过程中,${}会直接参与sql编译,直接显示数据,无法防止Sql注入,一般用于传入表名或order by动态参数
SQL注入
select * from ${tableName} where name = #{name}
如果表名为user; delete user; --
上述sql就会变为:
select * from user; delete user; -- where name = ?;
就会达到非法删除user表的功效
MyBatis是如何做到SQL预编译的呢?
其实在框架底层,是JDBC中的PreparedStatement类在起作用
21. equals源码
equals是根类Obeject中的方法。源代码如下
public boolean equals(Object obj) { return (this == obj); }
可见默认的equals方法,直接调用==,比较对象地址。
不同的子类,可以重写此方法,进行两个对象的equals的判断。
22. 为什么重写equals()和hashCode()方法
如果重写了equals()也必须重写hashCode(),否则就会违反Object.hashCode的通用约定,从而导致该类无法与所有基于散列值(hash)的集合类(如:HashMap)结合在一起正常运行
hashCode()的返回值和equals()的关系如下:
如果x.equals(y)返回“true”,那么x和y的hashCode()必须相等。
如果x.equals(y)返回“false”,那么x和y的hashCode()有可能相等,也有可能不等。
23. HashMap API
HashMap
void clear() 从此映射中移除所有映射关系(可选操作)。
boolean containsKey(Object key) 如果此映射包含指定键的映射关系,则返回 true。
boolean containsValue(Object value) 如果此映射将一个或多个键映射到指定值,则返回 true。
Set<Map.Entry<K,V>> entrySet() 返回此映射中包含的映射关系的 Set 视图。
boolean equals(Object o) 比较指定的对象与此映射是否相等。
V get(Object key) 返回指定键所映射的值;如果此映射不包含该键的映射关系,则返回 null。
int hashCode() 返回此映射的哈希码值。
boolean isEmpty() 如果此映射未包含键-值映射关系,则返回 true。
Set<K> keySet() 返回此映射中包含的键的 Set 视图。
V put(K key, V value) 将指定的值与此映射中的指定键关联(可选操作)。
void putAll(Map<? extends K,? extends V> m) 从指定映射中将所有映射关系复制到此映射中(可选操作)。
V remove(Object key) 如果存在一个键的映射关系,则将其从此映射中移除(可选操作)。
int size() 返回此映射中的键-值映射关系数。
Collection<V> values() 返回此映射中包含的值的 Collection 视图。
Entry
boolean equals(Object o) 比较指定对象与此项的相等性。
K getKey() 返回与此项对应的键。
V getValue() 返回与此项对应的值。
int hashCode() 返回此映射项的哈希码值。
V setValue(V value) 用指定的值替换与此项对应的值(可选操作)。
Iterator
boolean hasNext() 判断当前元素是否存在,并指向下一个元素
V next() 返回当前元素, 并指向下一个元素。
24. HashMap的key可以是null吗?
HashMap的key和value都可以为null,且key为null时的Entry节点 存在于 Entry[] table 的第一位
TreeMap的key和value都不能为null
25. 一个重复的集合如何进行去重并排序
方法一:变体类实现Comparable中compareTo方法
public class bbb implements Comparable<bbb>{ private String name; private Integer order; public int compareTo(bbb arg0) { //升序(默认) return this.getOrder().compareTo(arg0.getOrder()); //降序 //return arg0.getOrder().compareTo(this.getOrder()); } } //调用Collections排序方法 Collections.sort(list);
方法二:根据Collections.sort重载方法来实现
Collections.sort(list, new Comparator<bbb>() { public int compare(bbb bbb, bbb t1) { //升序(默认) return bbb.getOrder().compareTo(t1.getOrder()); //降序 return t1.getOrder().compareTo(bbb.getOrder()); } });
26. static块可以调用非static变量吗
不能,因为静态方法在类装载的时候就分配了内存块,而非静态的方法和变量在new这个类的对象的时候才分配内存块
而在静态方法内可以访问静态变量或者静态方法
27. Servlet是单例的,怎么个单例法
Servlet容器默认是采用单实例多线程的方式处理多个请求的:
1)当web服务器启动的时候(或客户端发送请求到服务器时),Servlet就被加载并实例化(只存在一个Servlet实例);
2)容器初始化化Servlet主要就是读取配置文件(例如tomcat,可以通过servlet.xml的<Connector>设置线程池中线程数目,初始化线程池通过web.xml,初始化每个参数值等等。
3)当请求到达时,Servlet容器通过调度线程(Dispatchaer Thread) 调度它管理下线程池中等待执行的线程(Worker Thread)给请求者;
4)线程执行Servlet的service方法;
5)请求结束,放回线程池,等待被调用;
(注意:避免使用实例变量(成员变量),因为如果存在成员变量,可能发生多线程同时访问该资源时,都来操作它,照成数据的不一致,因此产生线程安全问题)
从上面可以看出:
第一:Servlet单实例,减少了产生Servlet的开销;
第二:通过线程池来响应多个请求,提高了请求的响应时间;
第三:Servlet容器并不关心到达的Servlet请求访问的是否是同一个Servlet还是另一个Servlet,直接分配给它一个新的线程;如果是同一个Servlet的多个请求,那么Servlet的service方法将在多线程中并发的执行;
第四:每一个请求由ServletRequest对象来接受请求,由ServletResponse对象来响应该请求;
28. singleton实现
public class A { public static B b; static{ b=new B("yifan"); } public static B getB(){ return b; } }
29. List是怎么扩容的?
// 最重要的复制元素方法 elementData = Arrays.copyOf(elementData, newCapacity);
Arrays.copyOf功能是实现数组的复制,返回复制后的数组
30. having的作用
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用。如:查找订单总金额少于 2000 的客户
SELECT Customer,SUM(OrderPrice) FROM Orders GROUP BY Customer HAVING SUM(OrderPrice)<2000
31. 执行计划,explain中有几种类型?
ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行
index:Full Index Scan,index与ALL区别为index类型只遍历索引树
range:索引范围扫描,对索引的扫描开始于某一点,返回匹配值域的行,常见于between、<、>等的查询
ref:非唯一性索引扫描,返回匹配某个单独值的所有行。常见于使用非唯一索引即唯一索引的非唯一前缀进行的查找
eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描
const、system:当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量。system是const类型的特例,当查询的表只有一行的情况下, 使用system
NULL:MySQL在优化过程中分解语句,执行时甚至不用访问表或索引
32. wait / notify的作用,和sleep的区别?
1)sleep()是Thread类的方法静态方法,wait() / notify()是Object类中的实例方法
2)wait() / notify()必须用在synchronized代码块中调用,否则会抛出异常(因为wait()需要释放对象锁,如果不在synchronized代码块中不能保证拥有对象锁)
3)当在synchronized代码块中使用sleep(),线程会被挂起,但不会释放对象锁,如果有其他线程执行该synchronized代码块,一直会被阻塞,等待该线程被唤醒释放对象锁。
4)当在synchronized代码块中使用wait(),线程会被挂起,需要notify()唤醒,但该线程会释放对象锁,所以其他线程可以执行该synchronized代码块。
33. 线程同步的几种方式
1)同步方法
2)同步代码块
3)使用特殊域变量(volatile)实现线程同步
4)使用重入锁(ReentrantLock)实现线程同步
5)使用局部变量(ThreadLocal)实现线程同步
6)使用阻塞队列(LinkedBlockingQueue等)实现线程同步
ConcurrentHashMap(线程安全的HashMap)
CopyOnWriteArrayList(高效读)
ConcurrentLinkedQueue(高效读写队列)
BlockingQueue(数据共享通道)
ConcurrentSkipListMap(跳表)
7)使用原子变量(AtomicInteger)实现线程同步
34. 输入输出流
文件流(基本流):FileInputStream(File/Url)、FileOutputStream(File/Url) —— read/write/close
对象流:ObjectInputStream(InputStream) 、ObjectOutputStream(OutputStream) —— readObject/writeObject
缓冲流:BufferedInputStream(InputStream)、BufferedOutputStream(OutputStream) —— read/write/flush/close
字符流:InputStreamReader(InputStream,charsetName)、OutputStreamWriter(OutputStream,charsetName) —— read/write
缓冲流:BufferedReader、BufferedWriter —— readLine/write
//读取文件 InputStreamReader isr = new InputStreamReader(new FileInputStream("C:\\Users\\Administrator\\Desktop\\新建文本文档.txt"), "UTF-8"); BufferedReader wb = new BufferedReader(isr); String line = null; while((line=wb.readLine())!=null){ System.out.println(line); } isr.close(); //写入(追加)文件 OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("C:\\Users\\Administrator\\Desktop\\新建文本文档.txt",true),"UTF-8"); BufferedWriter bw = new BufferedWriter(osw); bw.newLine(); bw.write("有声有色");//将它写入缓存中,如果缓存满了则自己flush; bw.flush(); osw.close();
行输入:PrintWriter —— print
35. 索引分哪几类,添加索引注意什么
聚集索引:一个表只能有一个,但是速度较快,占用空间大,相对的,建立的时候消耗也大。在聚集索引中,表中行的物理顺序与键值的逻辑(索引)顺序相同。如果某索引不是聚集索引,则表中行的物理顺序与键值的逻辑顺序不匹配。与非聚集索引相比,聚集索引通常提供更快的数据访问速度。
非聚集索引:一个表可以有多个。
普通索引:添加INDEX —— ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
主键索引:添加PRIMARY KEY —— ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
唯一索引:添加UNIQUE —— ALTER TABLE `table_name` ADD UNIQUE ( `column` )
全文索引:添加FULLTEXT —— ALTER TABLE `table_name` ADD FULLTEXT ( `column`)
复合索引 —— ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )
36. mongodb和mysql的区别,什么时候用
1)MySQL是关系型数据库,使用简单,方便,有统一的SQL语句,支持事务一致性。
MongoDB是文档式数据库,必须使用专用的API进行操作,不过大部分操作都绕不过增删改查,学习起来也方便,不支持事务一致性。
2)MySQL里数据模型是二维线性表,里面每一个元素都是不可再分的原子,而且同一列的数据类型是相同的。
MongoDB数据模型就比较灵活,一张表就是一个document,里面的每一个数据都是一个collection,如果将一个document当作二维表看,里面的每一个元素都是可以是一个原子数据或者是一个collection,而且同一列的数据类型可以不一致,所以一般MongoDB的管理软件都把一个数据用json格式来显示
3)MySQL适用于传统的对关联要求高的方面,
MongoDB更多用于Logging、SNS等以K-V居多的需求,但是两种数据库其实都能胜任大多数需求。
4)MongoDB还提供gridfs文件系统,可以很容易做成分布式架构
MySQL无法分布式管理
5)MongoDB比MySQL快,因为它有Memory-Mapping(磁盘上映射到内存上)以及它不用处理事物
37. mybatis传两个值用什么类型?
<resultMap id="XXBean" type="com.yweb.entity.User"> <result property="id" column="id"></result> <result property="url" column="url"></result> <result property="name" column="name"></result> </resultMap>
1)基于下标
public List<XXBean> getXXBeanList(String id,String code);
<select id="getXXBeanList" resultType="XXBean"> select * from user where id=#{0} and name=#{1} </select>
2)Map/List封装多参数
public List<XXBean> getXXBeanList(HashMap map);
<select id="getXXBeanList" parameterType="hashMap" resultType="XXBean"> select * from user where id=#{id} and code=#{code} </select>
3)基于注解
public List<XXBean> getXXBeanList(@Param("id") String id_id,@Param("code") String code_code);
<select id="getXXBeanList" resultType="XXBean"> select * from user where id=#{id} and name=#{code} </select>
38. Mybatis如何插入后返回主键?
MySql和SqlServer 支持主键自增长的数据库:
<insert id="add" parameterType="com.yweb.entity.User" keyProperty="id" useGeneratedKeys="true"> insert into (name,age) values ('zs',18) </insert>
Oracle不支持主键自增长的数据库:
<insert id="AltName.insert" parameterType="AltName"> <selectKey resultType="long" keyProperty="id"> SELECT SEQ_TEST.NEXTVAL FROM DUAL </selectKey> insert into altname(primaryName,alternateName,type)values(#{primaryName},#{alternateName},#{type}) </insert>
39. Mybatis批量插入
insert into u_user(nickname) values <foreach collection="list" item="item" separator=","> (<if test="item.nickname!=null and item.nickname != ''"> #{item.nickname} </if>) </foreach>
40. MYSQL中如何查2到10的元素?
select * from test_table LIMIT 1,10
注意:LIMIT从0开始计数
41. 集合类的顶层接口有哪些?
总共有两大接口:Collection 和Map ,一个元素集合,一个是键值对集合; 其中List和Set接口继承了Collection接口,一个是有序元素集合,一个是无序元素集合;而ArrayList和 LinkedList 实现了List接口,HashSet实现了Set接口,这几个都比较常用; HashMap 和HashTable实现了Map接口,并且HashTable是线程安全的,但是HashMap性能更好; 注意:所有集合(List、Set以及Map)都实现了Cloneable(原型模式)和Serializable(序列化)