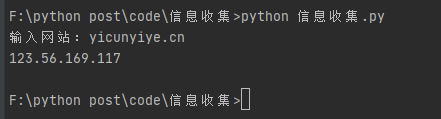
0x01 ip查询
import socket
domain = input("输入网站:")
ip = socket.gethostbyname(domain)
print(ip)
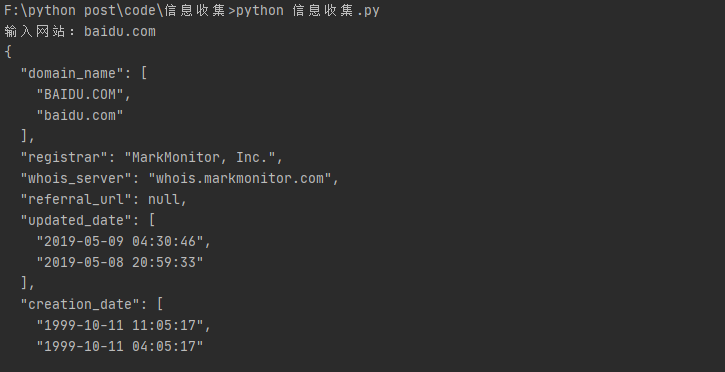
0x02 whois查询
需要安装python-whois模块
#whois查询
from whois import whois
domain = input("输入网站:")
data = whois(domain)
print(data)
0x03 子域名收集
result.scheme : 网络协议
result.netloc: 服务器位置(也有可能是用户信息)
result.path: 网页文件在服务器中的位置
result.params: 可选参数
result.query: &连接键值对
##子域名
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse
import sys
def bing_search(site,pages):
subdomain = []
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36',
'Accept': '*/*',
'Accept-Language': 'en-US,en;q=0.5',
'Accept-Encoding': 'gzip,deflate',
"Referer": "https://www.bing.com/?mkt=zh-CN"
}
for i in range(1,int(pages)+1):
url = "https://www.bing.com/search?q="+site+"&qs=n&sp=-1&pq="+site+"&sc=9-9&sk=&cvid=0136E796B9494E9E97F282AFC3E557B8&first="+str((int(i)-1)*10 -1)+"&FORM=PERE"
conn = requests.session()
conn.get("https://www.bing.com/",headers=headers)
html = conn.get(url,stream=True,headers=headers,timeout=18)
soup = BeautifulSoup(html.content,'html.parser')
h2 = soup.findAll('h2')
for i in h2:
try:
link = i.a.get('href')
domain = str(urlparse(link).scheme+"://"+urlparse(link).netloc)
if domain in subdomain:
pass
else:
if site in domain:
subdomain.append(domain)
print(domain)
f = open('result.txt','w')
f.write(str(subdomain).replace("'","").replace(",","
").replace("["," ").replace("]",""))
f.close()
except Exception as e:
continue
if __name__ == '__main__':
if len(sys.argv) == 3:
site = sys.argv[1]
page = sys.argv[2]
else:
print("usage: %s baidu.com 10" % sys.argv[0])
sys.exit(-1)
subdomain = bing_search(site,page)
input("输入任意键结束")
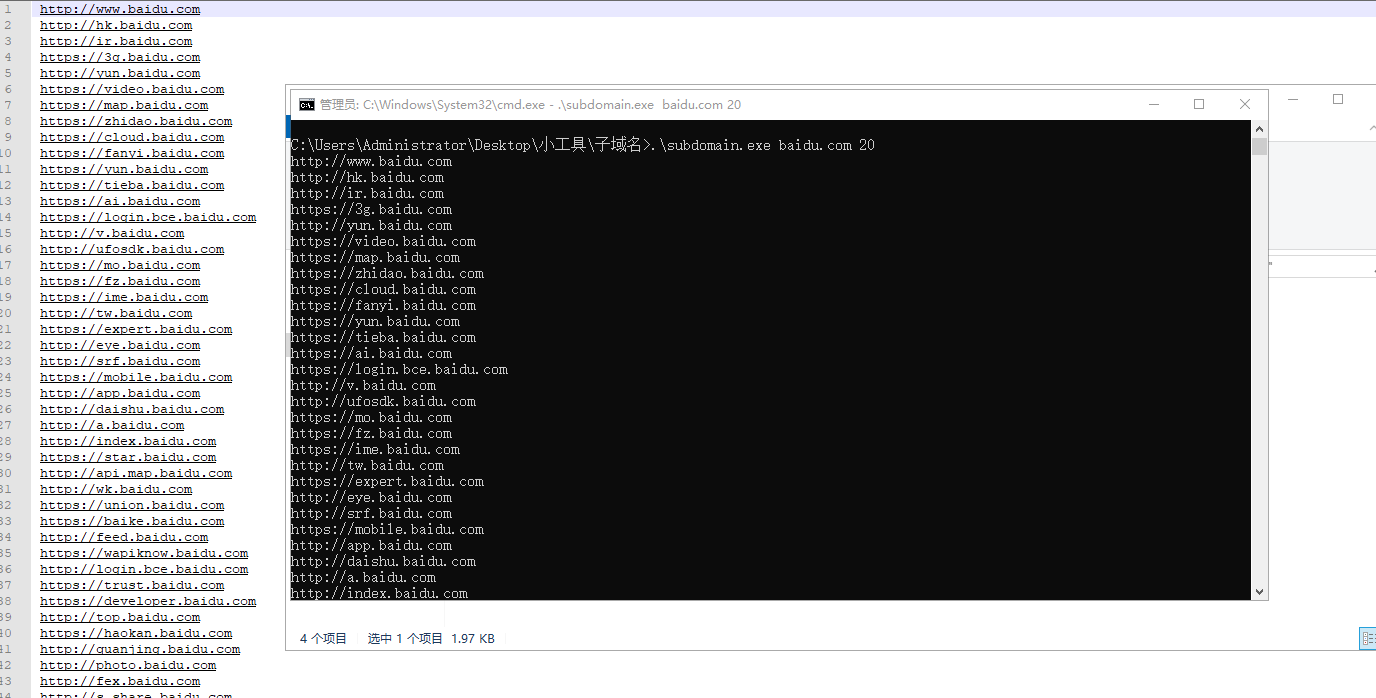
运行效果
参考文档
Requests文档