神经网络与深度学习(更新至第6讲 循环神经网络)_哔哩哔哩_bilibili
上一讲说模型迭代的时候要在验证集上错误率不再下降为止,为何要强调是验证集,而不是训练集呢?这就涉及到模型的泛化和正则化。
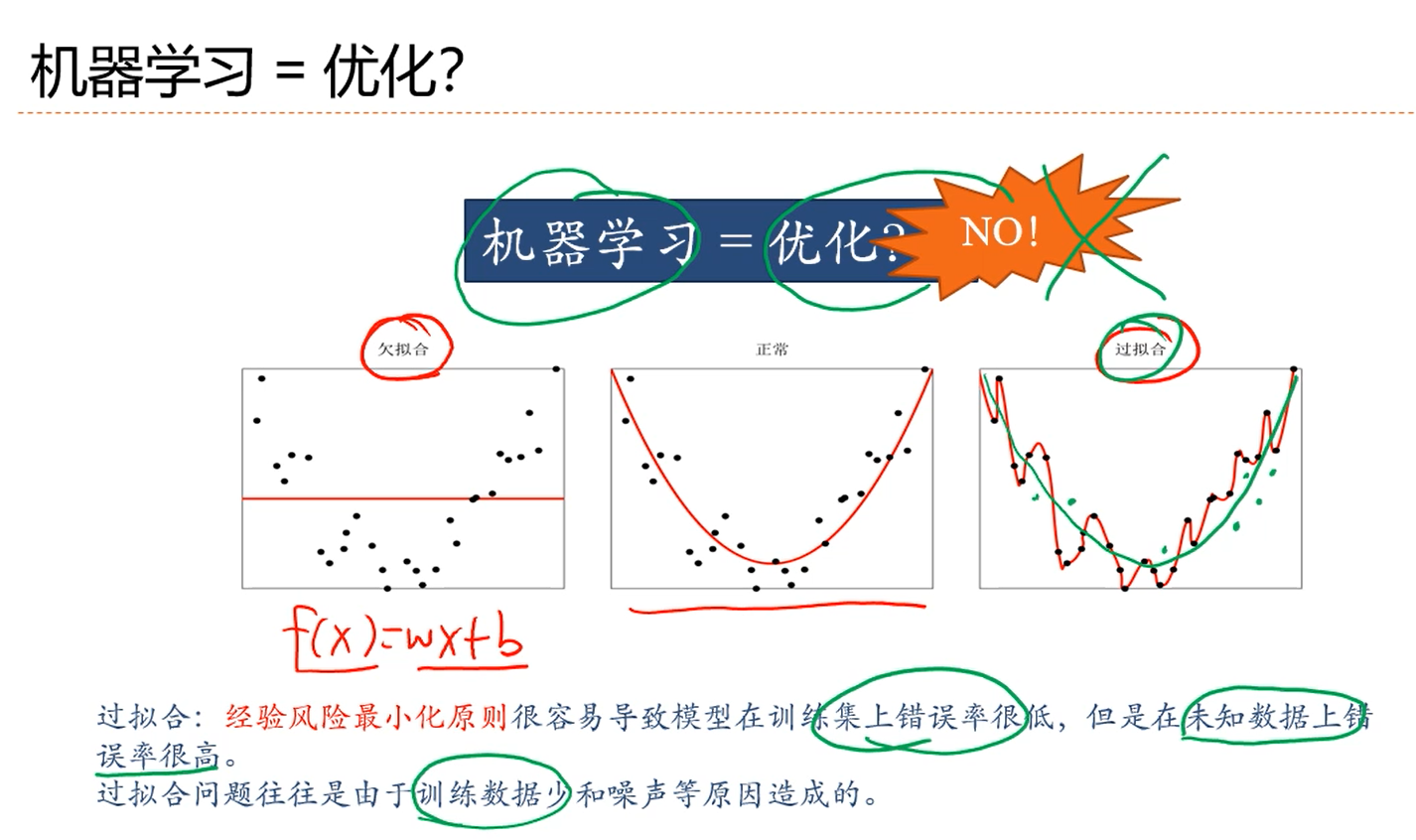
注解:
1.欠拟合:直线。
2.正常:二次曲线。
3.过拟合:比二次曲线复杂的曲线(增加了模型的复杂度),模型可以穿过训练集上所有点,在训练集上的错误率为0.会发现:对于新样本,这条曲线都预测不对,即:对新样本点错误率很高。过拟合的原因可能是:训练样本少或者模型复杂度过高。
4.所以,机器学习,不等同于优化一个损失函数。因为机器学习关注的不是在训练集上的错误率,而是关注的是整个(训练)数据分布上的错误率。
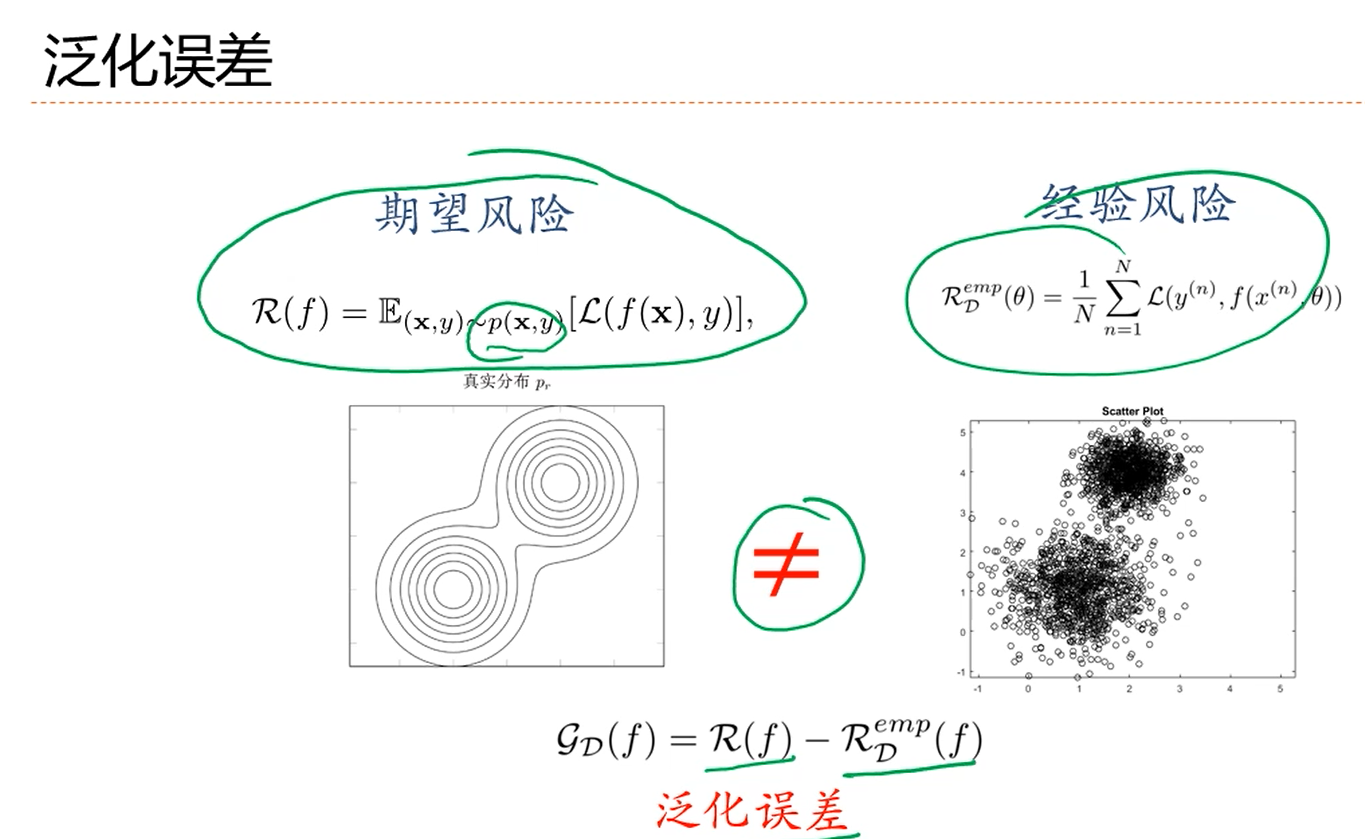
注解:
1.p(X,y)代表训练样本的数据的分布类型。
2.机器学习既期望经验损失比较低,也期望泛化误差比较小。

注解:
1.增加模型复杂度就可能会造成过拟合。
2.降低泛化误差的一个有效手段就是:正则化。
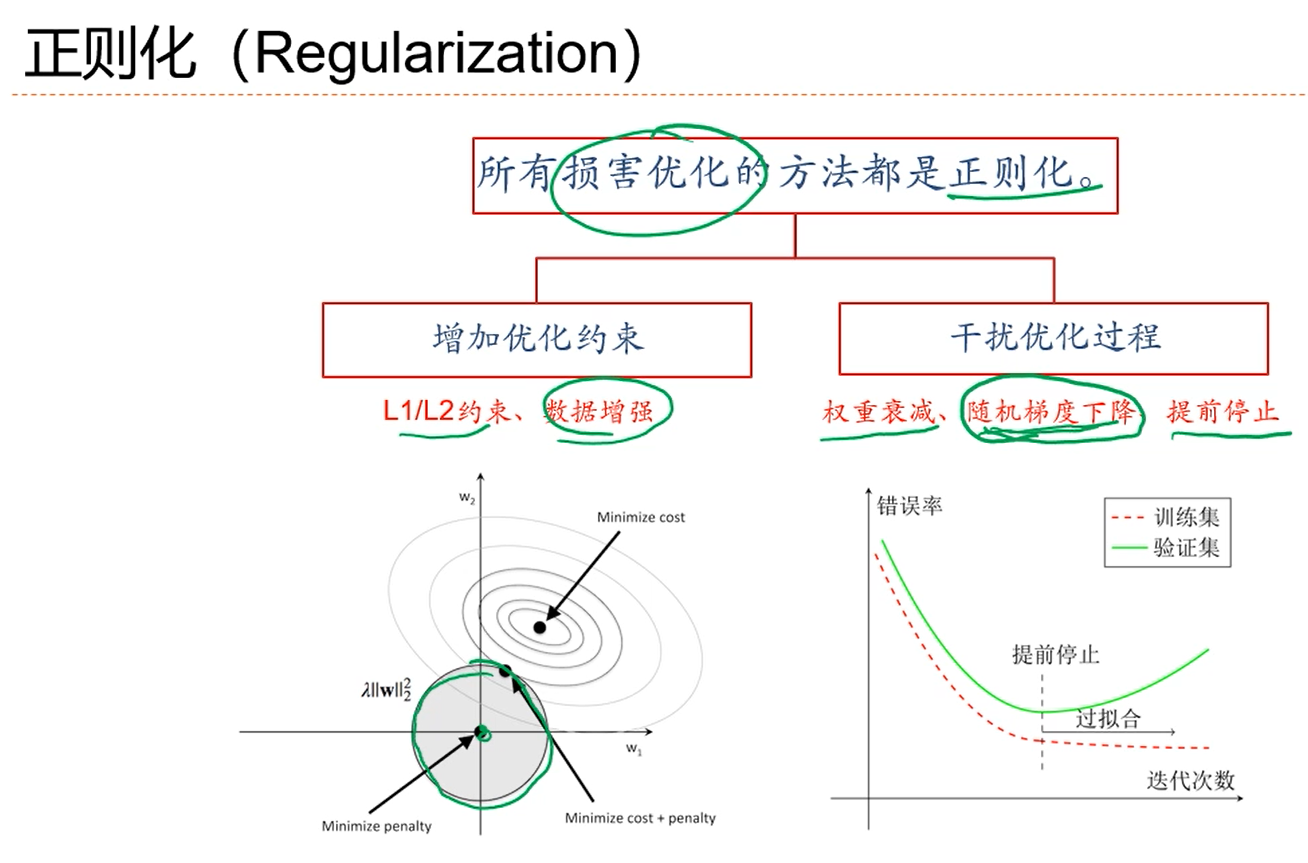
注解:
1.上图左边是L2正则化,L2正则化约束w取值在原点附近(?),限制了模型能力,避免模型过拟合。
2.通过数据增强的方式构造出一些新的样本,增加训练数据量,这也是一种约束方法。
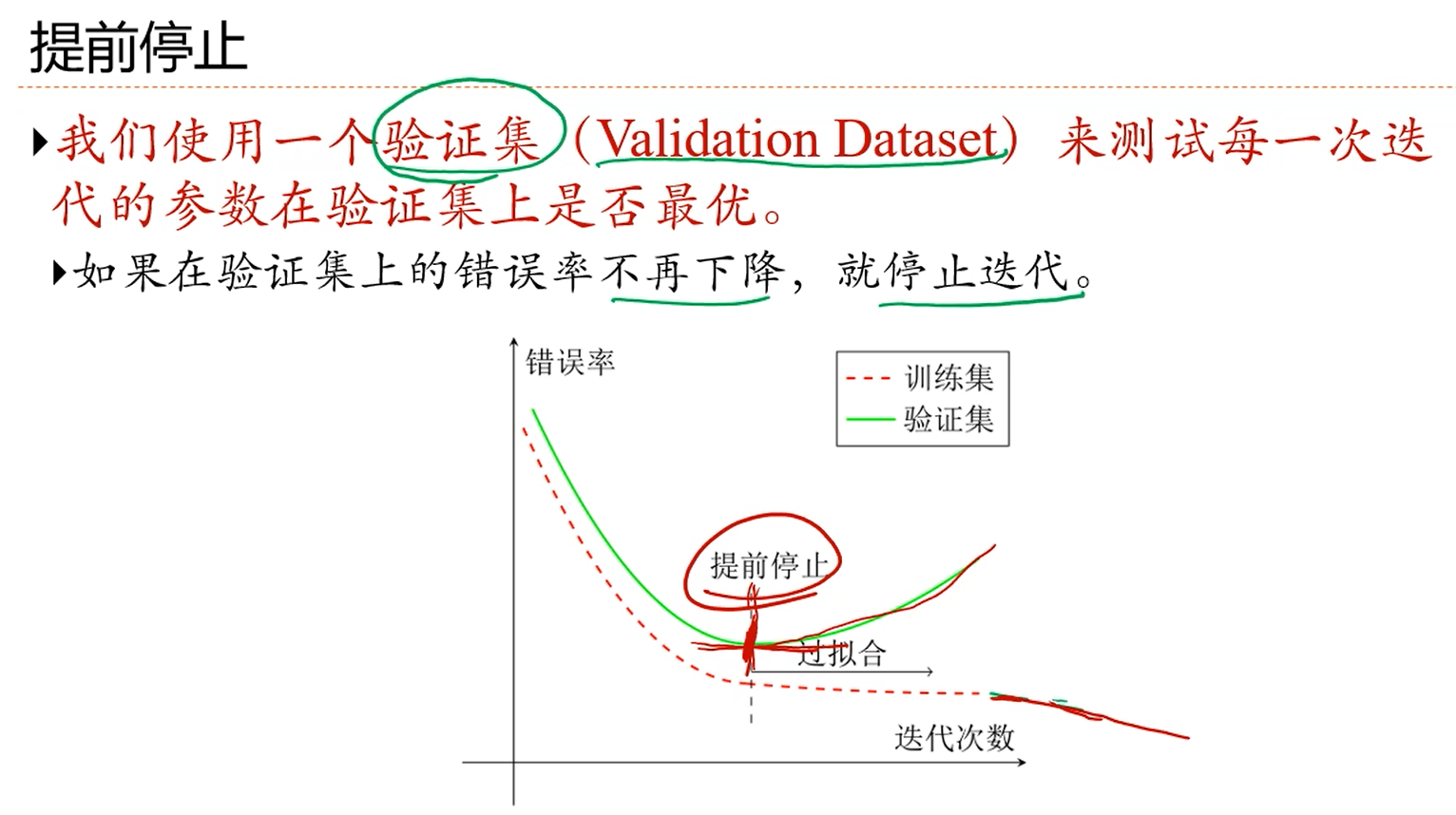
注解:
1.验证集是从样本集中分出来的,和训练集都是独立同分布采样的。
2.提前停止是用的最多的一个正则化方法。
3.测试集和验证集、测试集:数据集一般会分成训练集、验证集和测试集。在训练集上训练两个神经网络模型,这两个模型的差别可能是神经网络的层数不同,或者每层神经网络的神经元个数以及正则化的一些参数的不同等等,我们将这些参数称为超参数。在验证集上评估不同模型的拟合能力或者说好坏,所以,训练集是用来调整权值参数的数据集,验证集用来评估不同网络模型的表现,一旦通过比较找到了表现好的网络模型,就在测试集上最后测试一次泛化误差,以此作为网络模型在给定的数据分布上的泛化误差的估计。
假如只设计(涉及)一个网络模型,那么应该就只需要训练集和测试集就行了,在训练集上把神经网络的权值参数调整到最优,然后在测试集上最后做一次泛化误差估计。
也就是说,验证集是用来从设计的不同的网络模型中选择出一个好的模型的。当在训练集上的误差不再减小的时候,或者说正确率不再升高的时候,就认为在当前网络模型下,权值参数是最优的参数了。