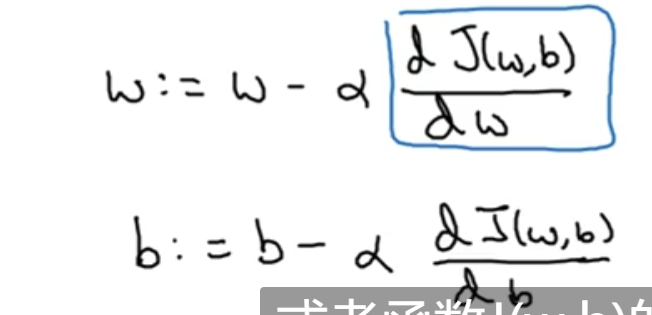https://www.bilibili.com/video/BV1FT4y1E74V?p=10
损失函数:
![]()
(y(hat),y)=(预测值,标签值)
损失函数衡量了参数w,b在训练集上的训练效果。
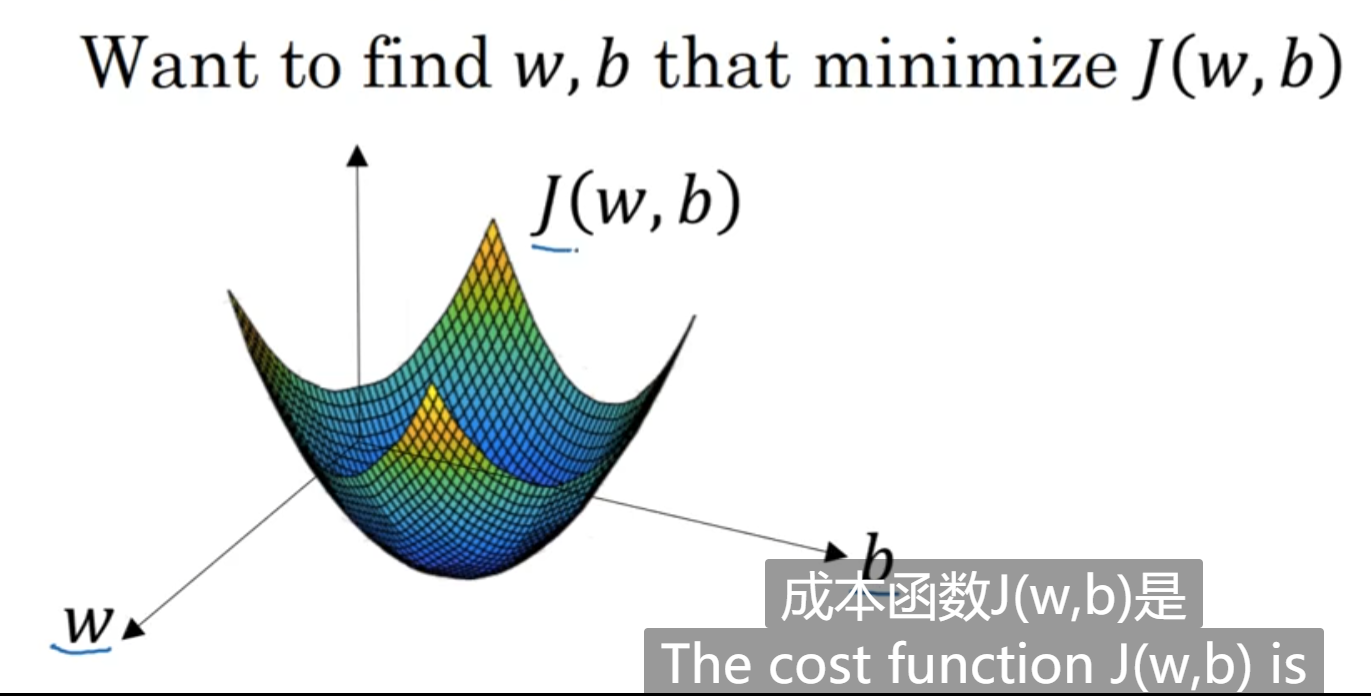
如上图:w,b表示空间参数(spatial parameters),这里当作是自变量,找到参数w,b使得costfunction取得最小值。其实,w,b可以是高维的向量,这里为了绘图方便,都表示成了一个实数。
要注意的点:
1.要用某些之初始化w和b.
2.假如函数是凸函数,则可以初始化为任意的位置上,它都能很容易的到达最低点。
3.假如函数是非凸函数,则不可以初始化在随意的位置上。

经过多部迭代之后,函数能够收敛到全局最优点。
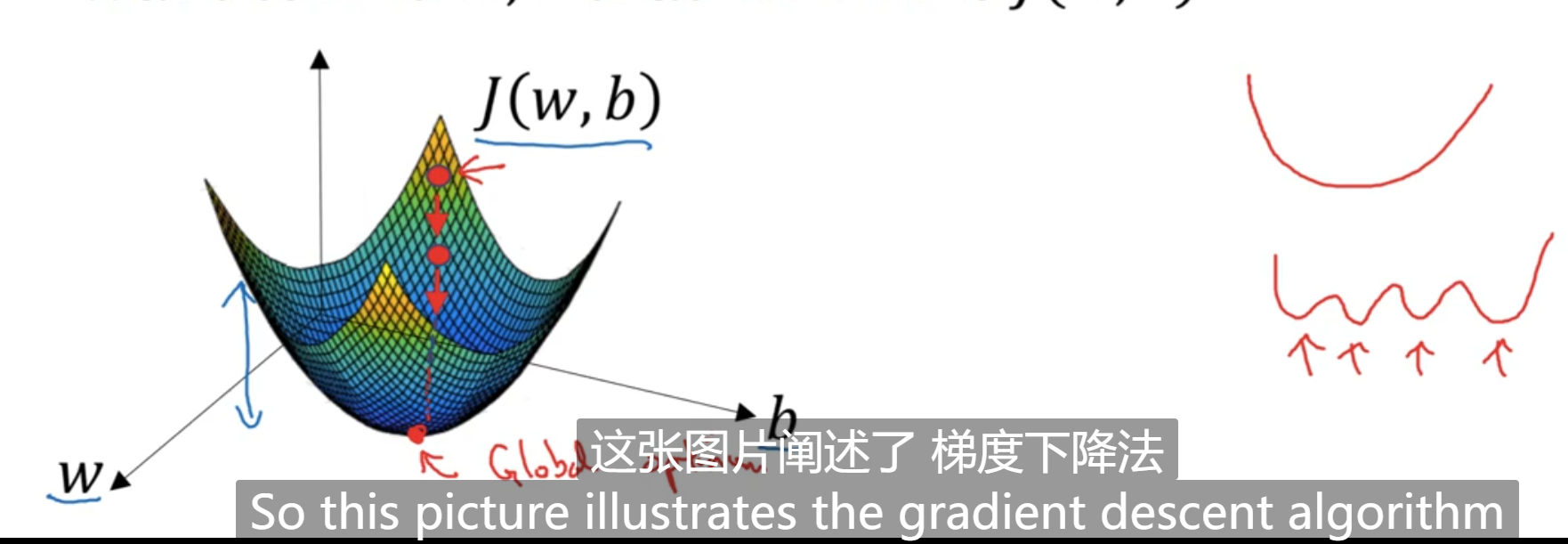
先用一维的曲线说明梯度下降的过程:

在算法收敛之前,会重复对参数进行求导更新。α是学习率,可以控制每一次更新的时候的步长。或者说梯度下降的步长。
假设参数w的初始化位置如下图红色圆圈所示:

因为在上图所示位置处,导数的值是正的,所以更新的过程,w会向左边移动,J最终会收敛到最低点。
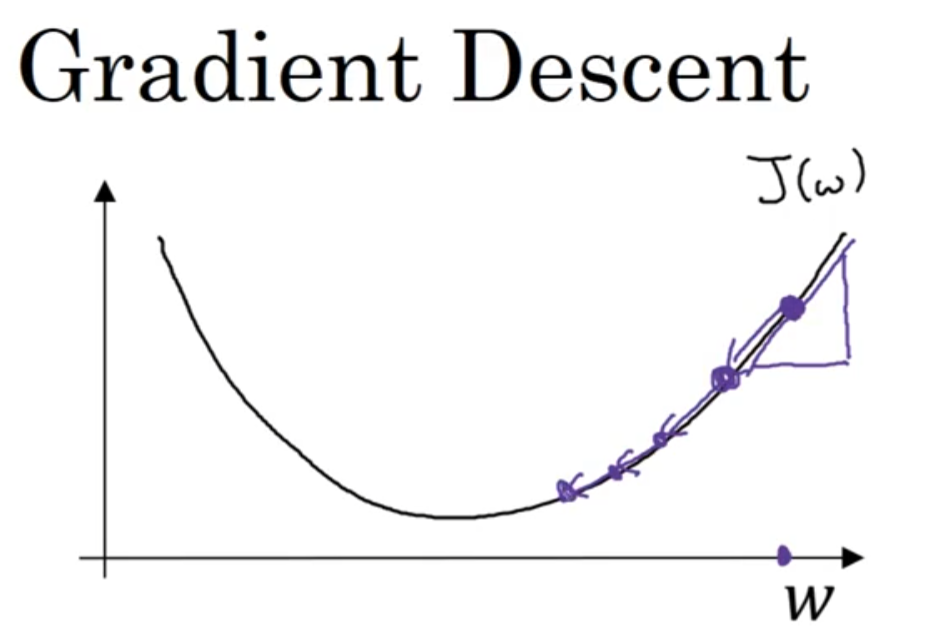
假如w的初始值一开始在左边,此时导数的值是负的,在w更新的过程中,它会向右边移动,也可以让J收敛到最低位置处。

当有偏置b的时候,参数的更新公式如下所示: