https://www.bilibili.com/video/BV1aE411T7Gf/?spm_id_from=333.788.recommend_more_video.15





2D识别/j检测/分割的缺点:不知道检测出来的人离自己或者机器有多远。理想的情况是让机器感知到3D世界,并做一定的交互。


人能感知到3维世界,但是机器不行。
人看兔子是有3维形状的,但是机器只认为它是一连串的点。
3d点云的优点是含有几何信息。采集是数据不受光照的影响,这一点和Image是有区别的。
缺点或者说挑战:
1.不规则,近密远疏。不想image那样,按照pixel有规则的排列。
2. 无序。打乱后,还是表示同一个对象,但是计算机这时候认为不是一个对象了,因为点的矩阵不一样了。


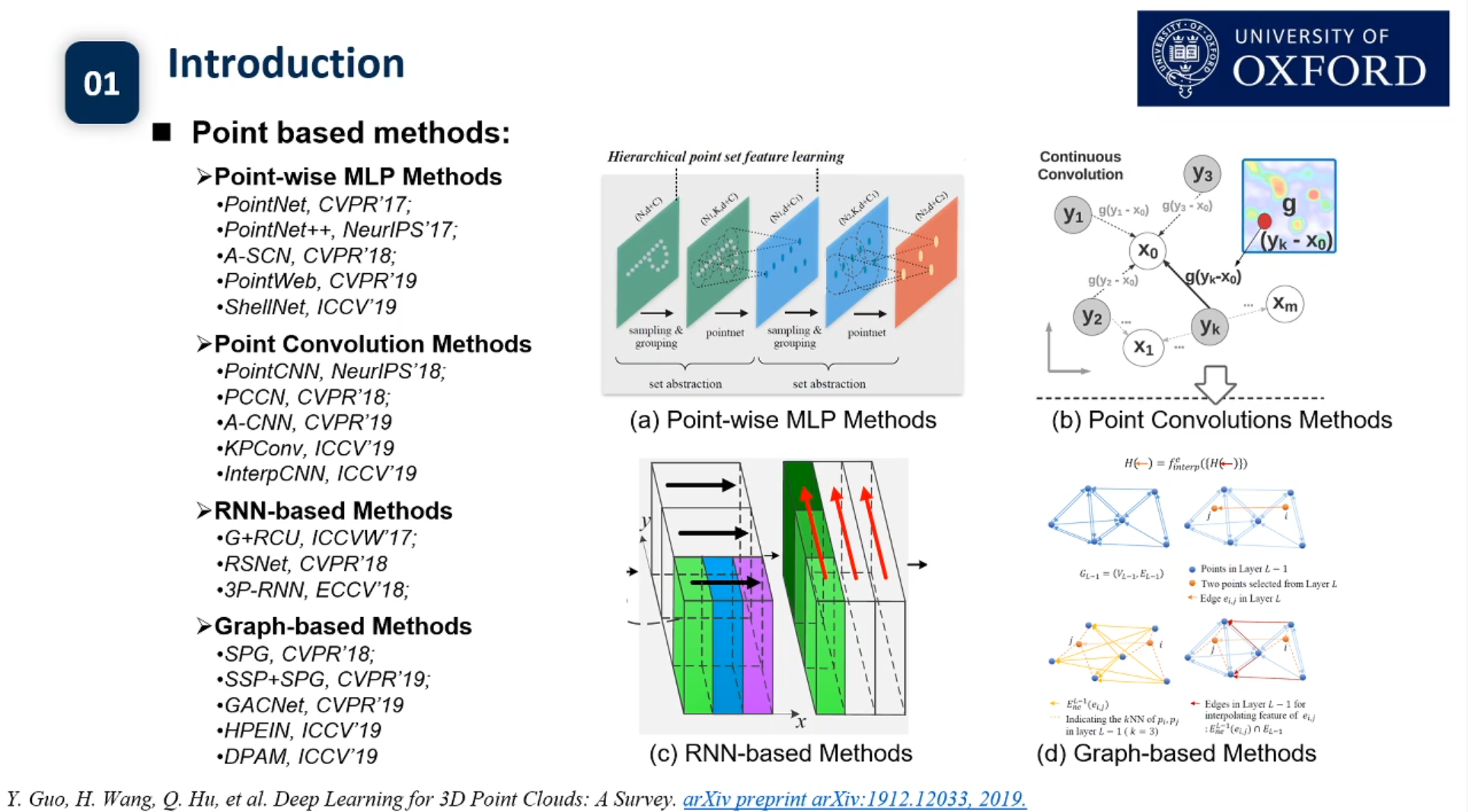
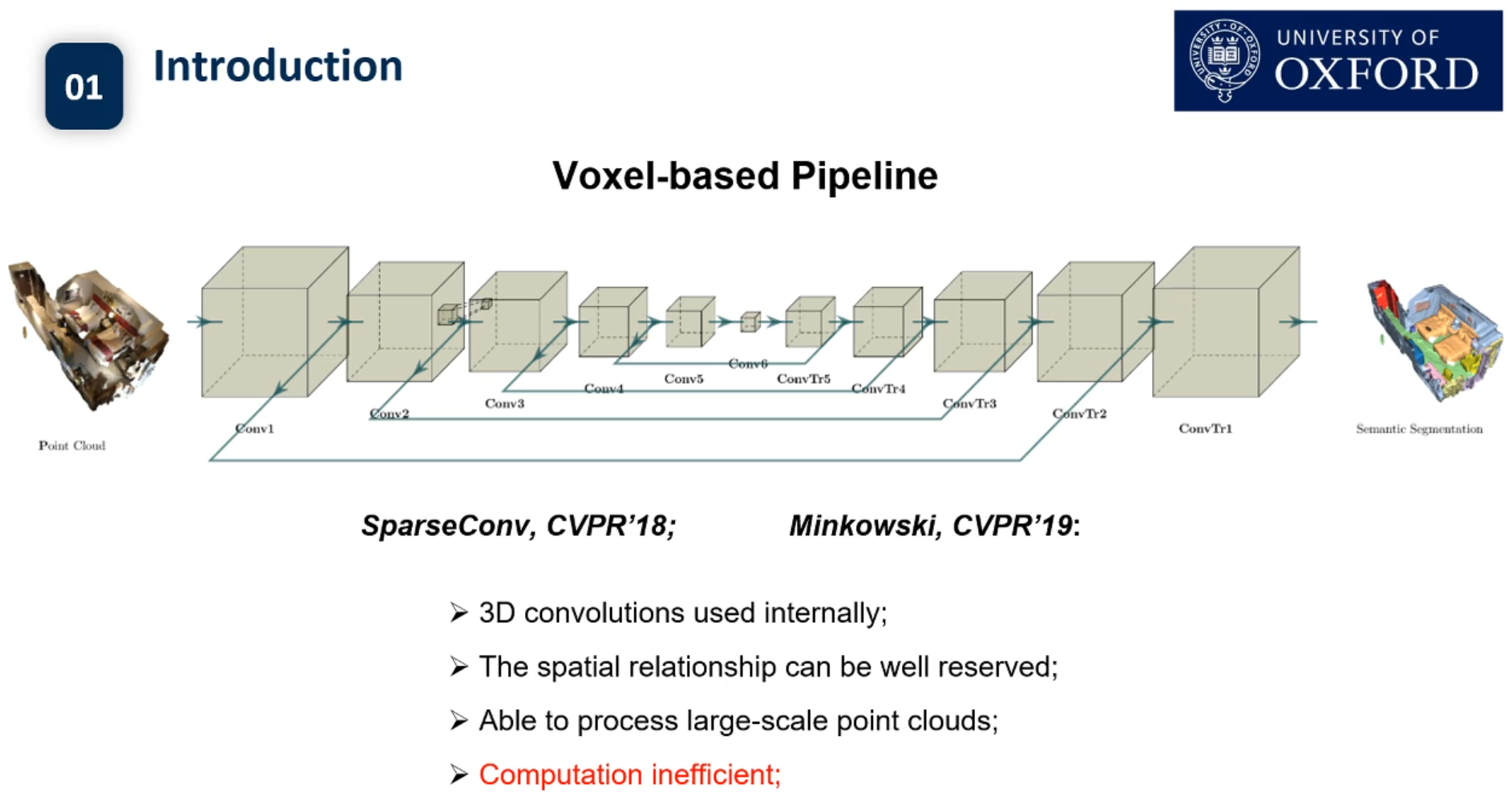
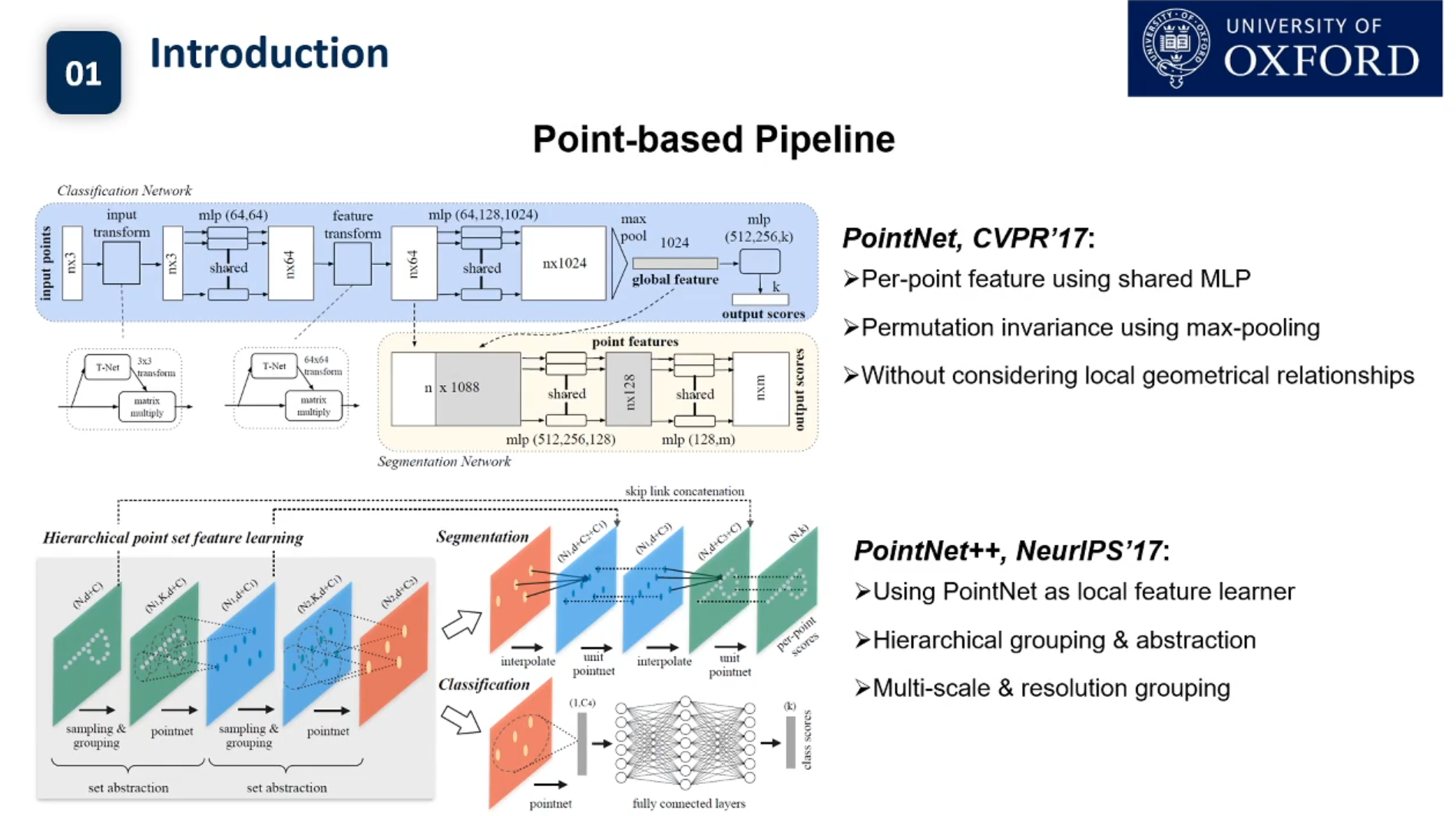



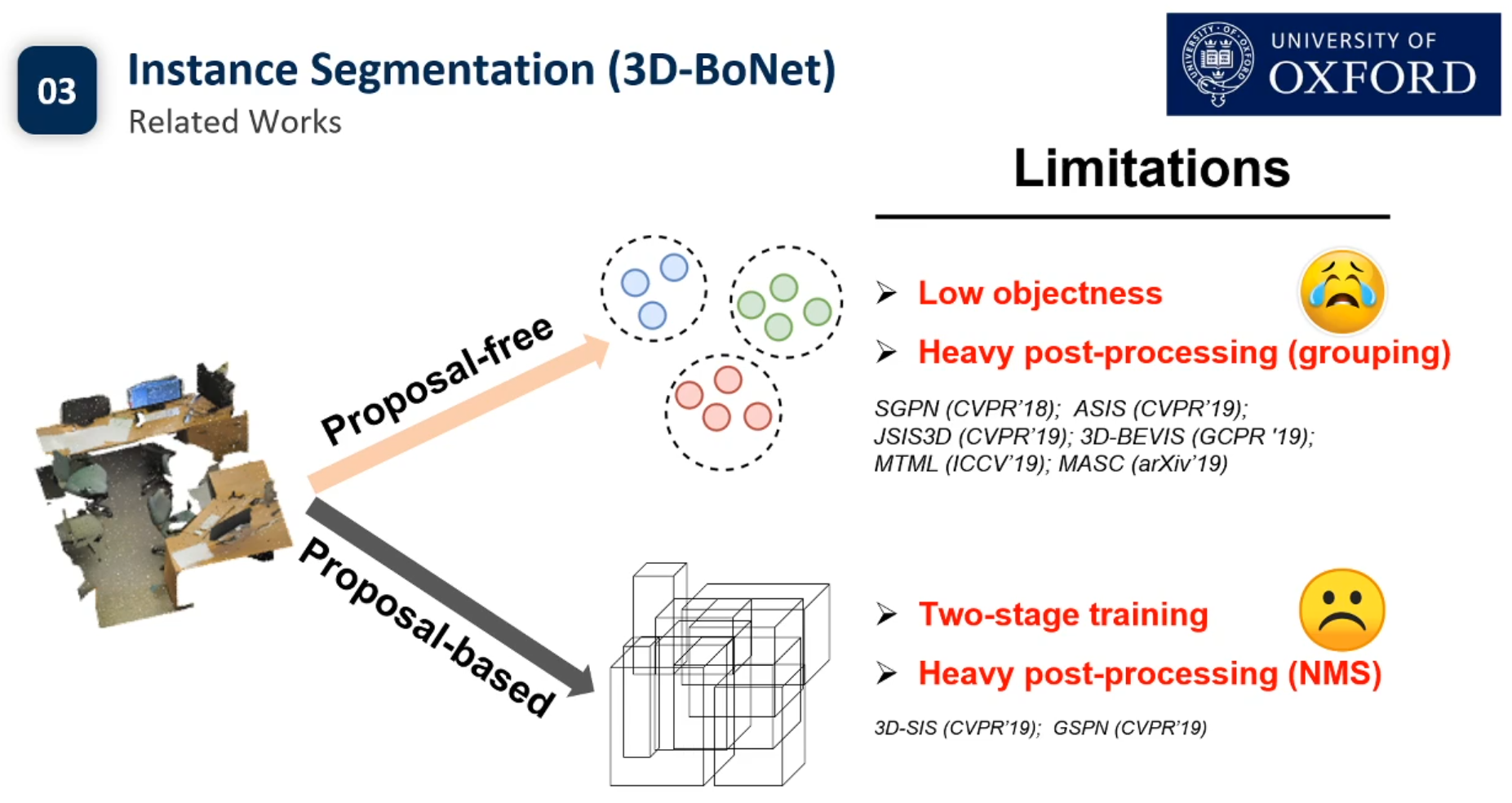
semantic segmentation是把一个场景中所有的椅子输出为一个标签,instance segmentation在所有椅子输出一个标签的基础上,还是把每一把椅子区分开,每一把椅子都要有不同的标签,是更加细粒度的语义识别,更加高层次的一个理解。
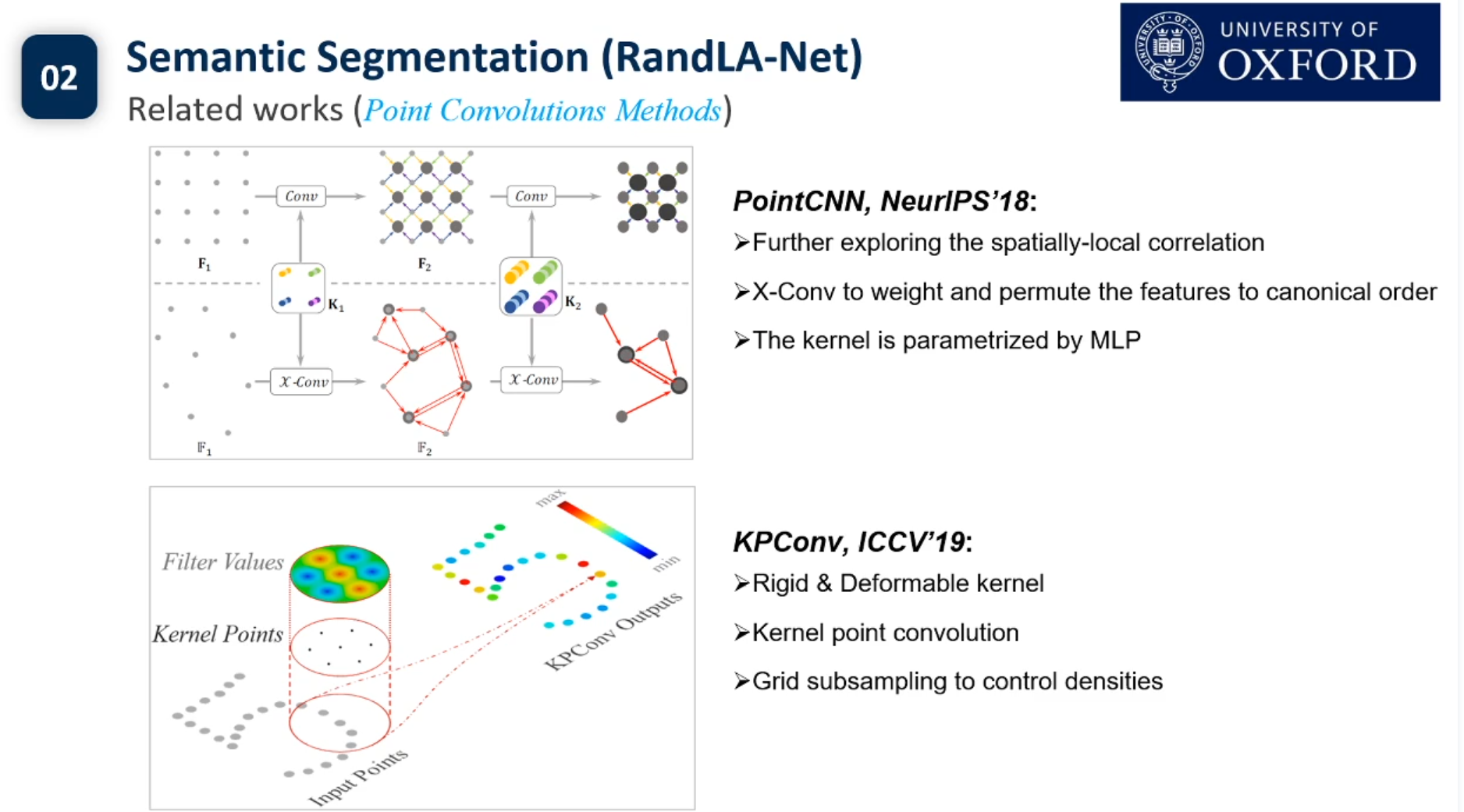
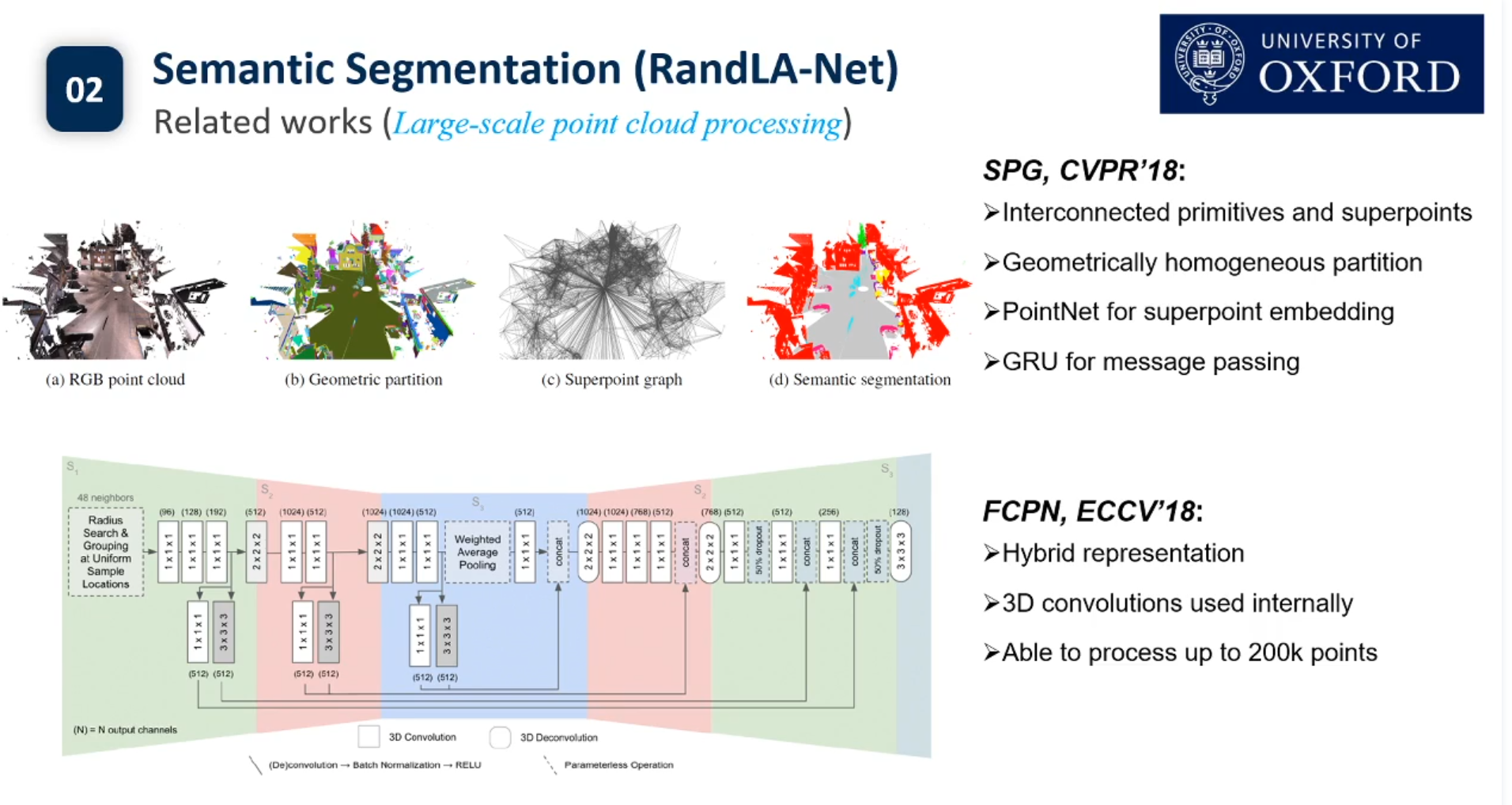
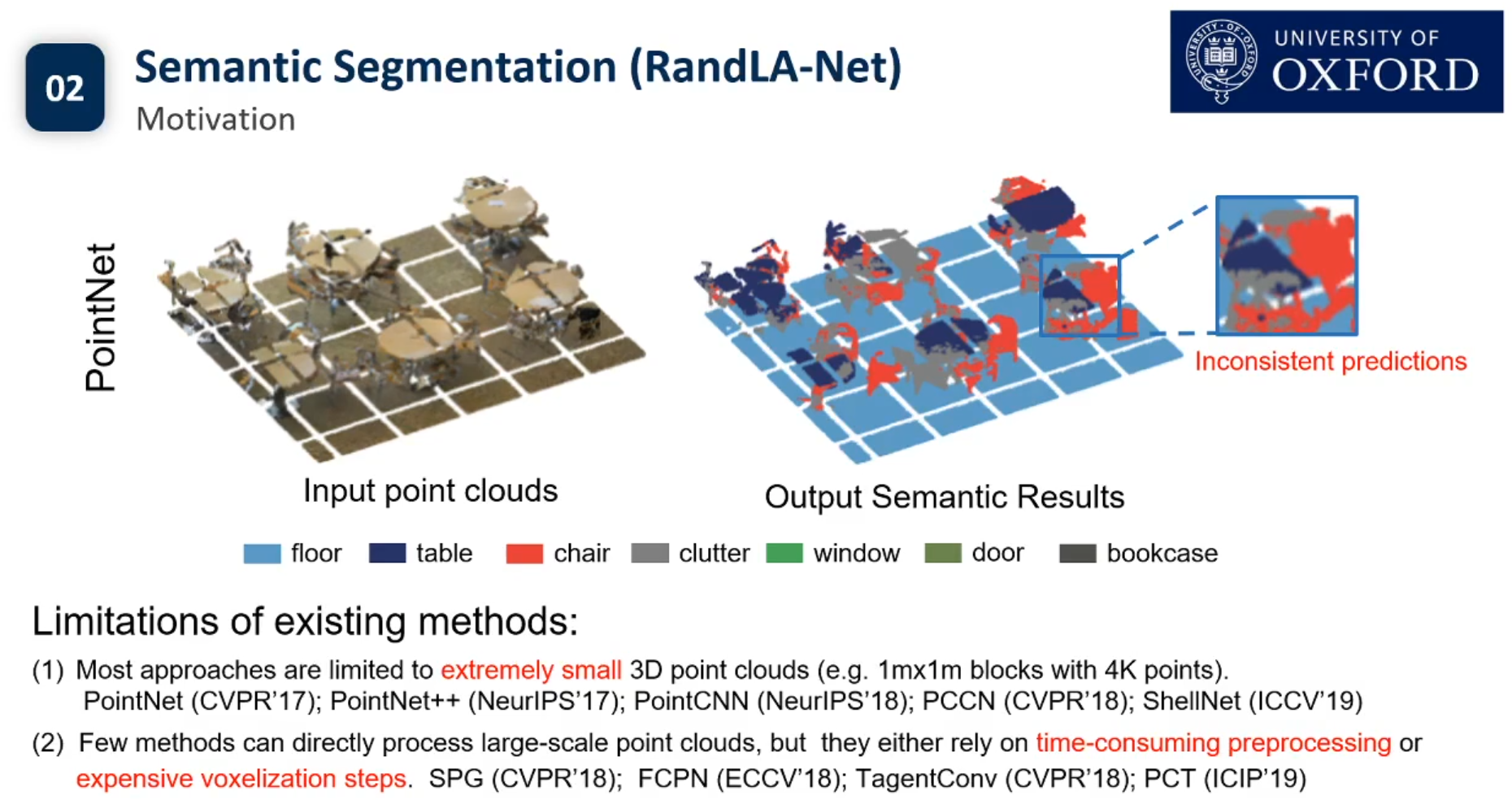
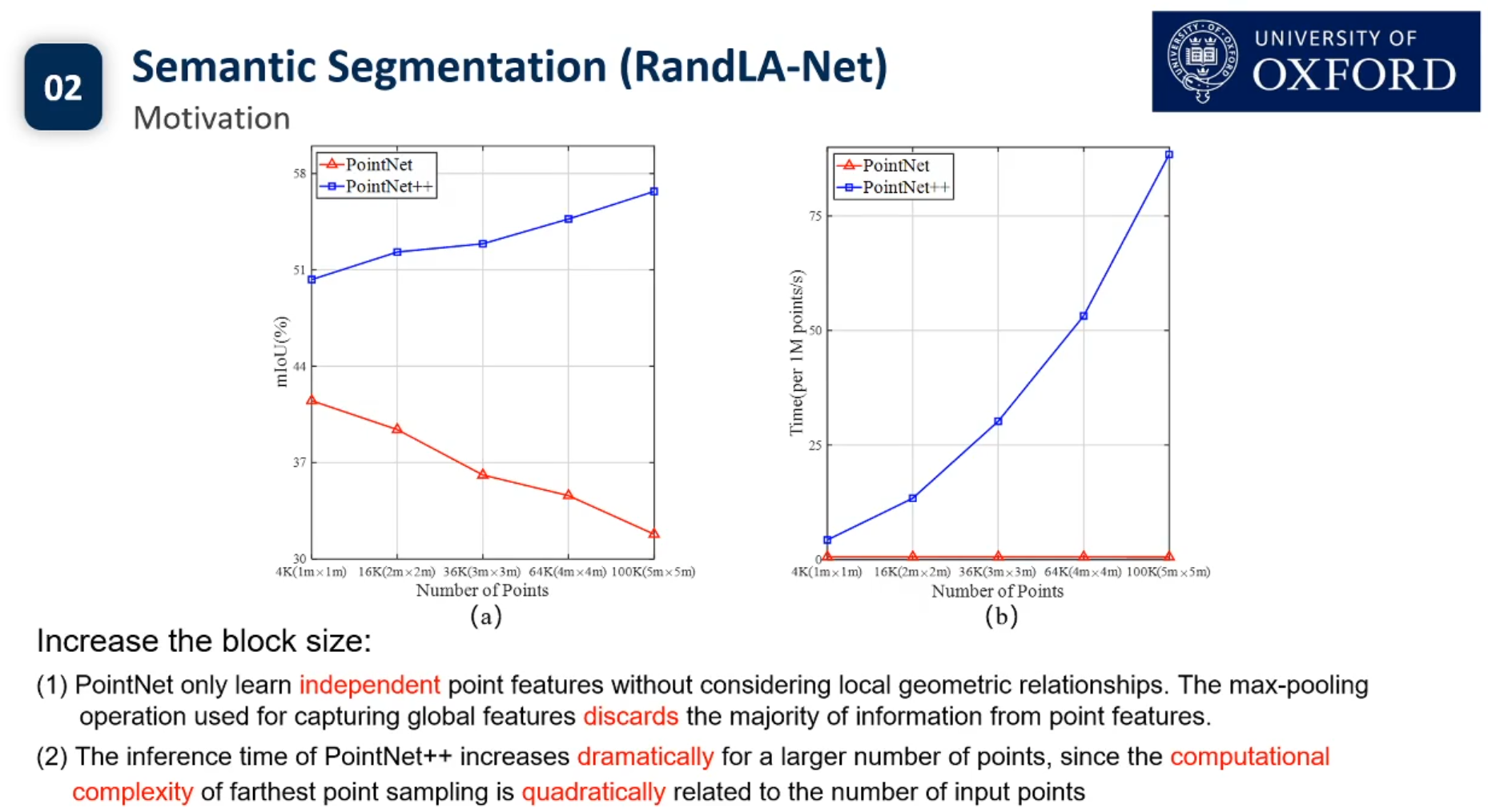


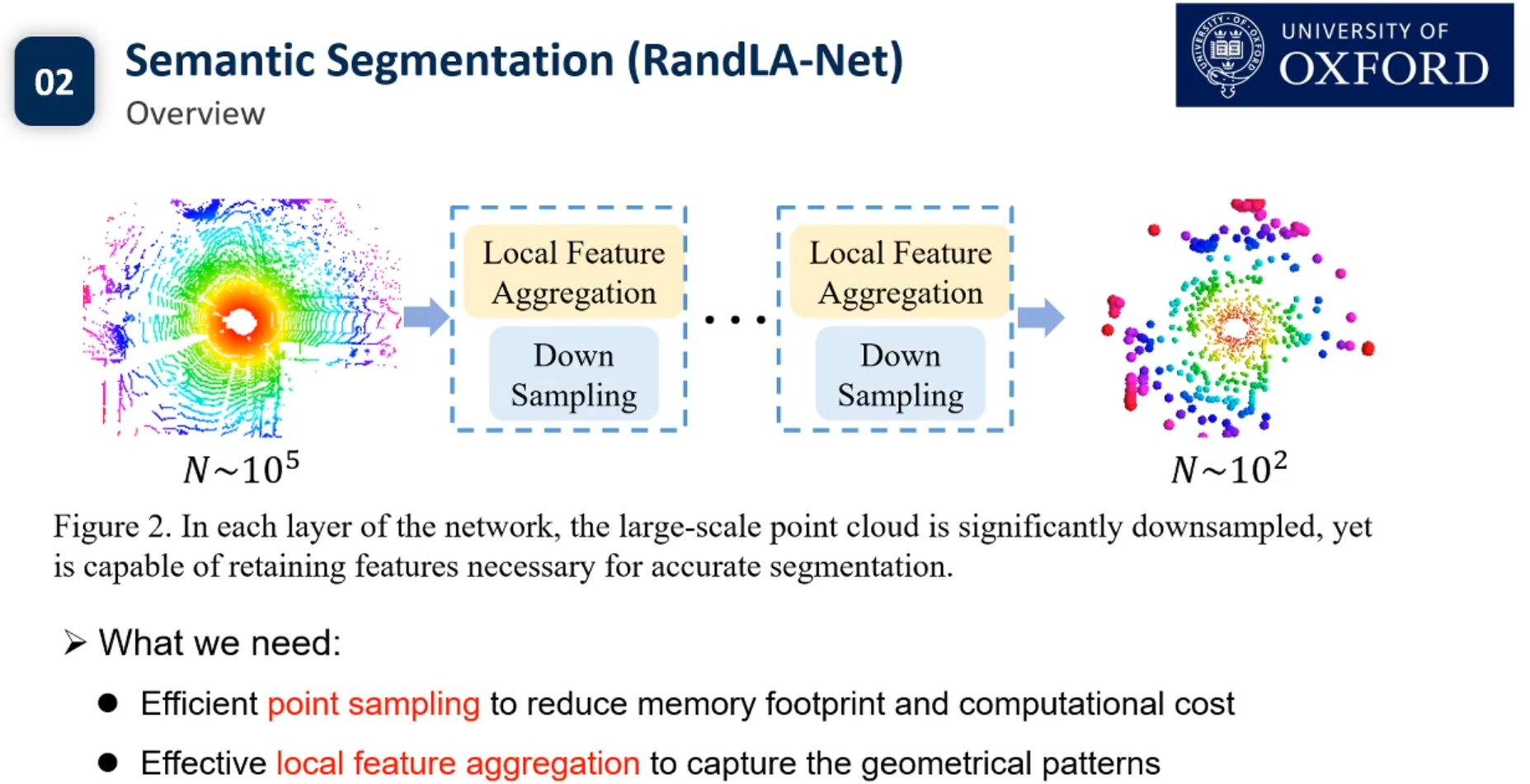




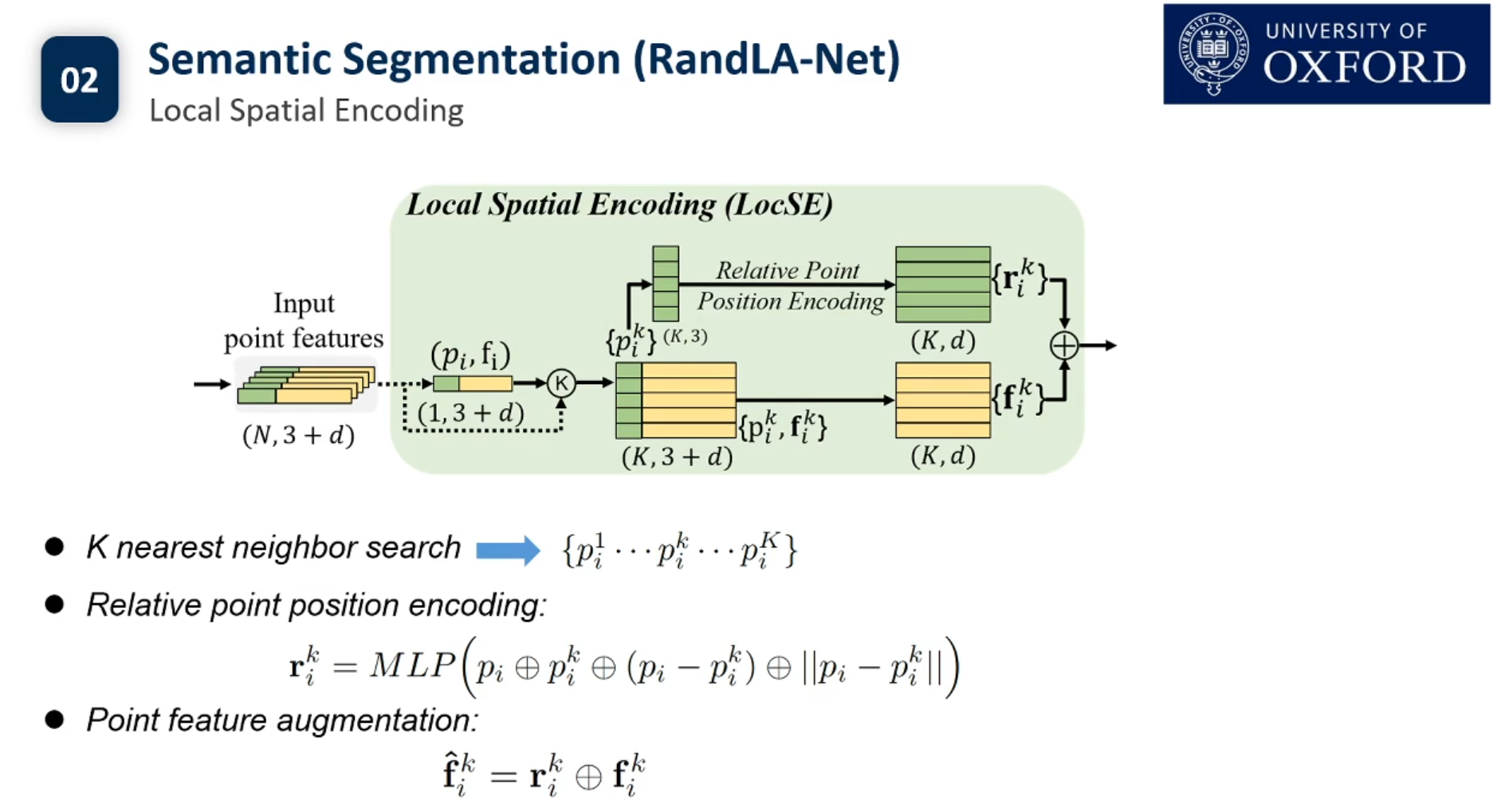

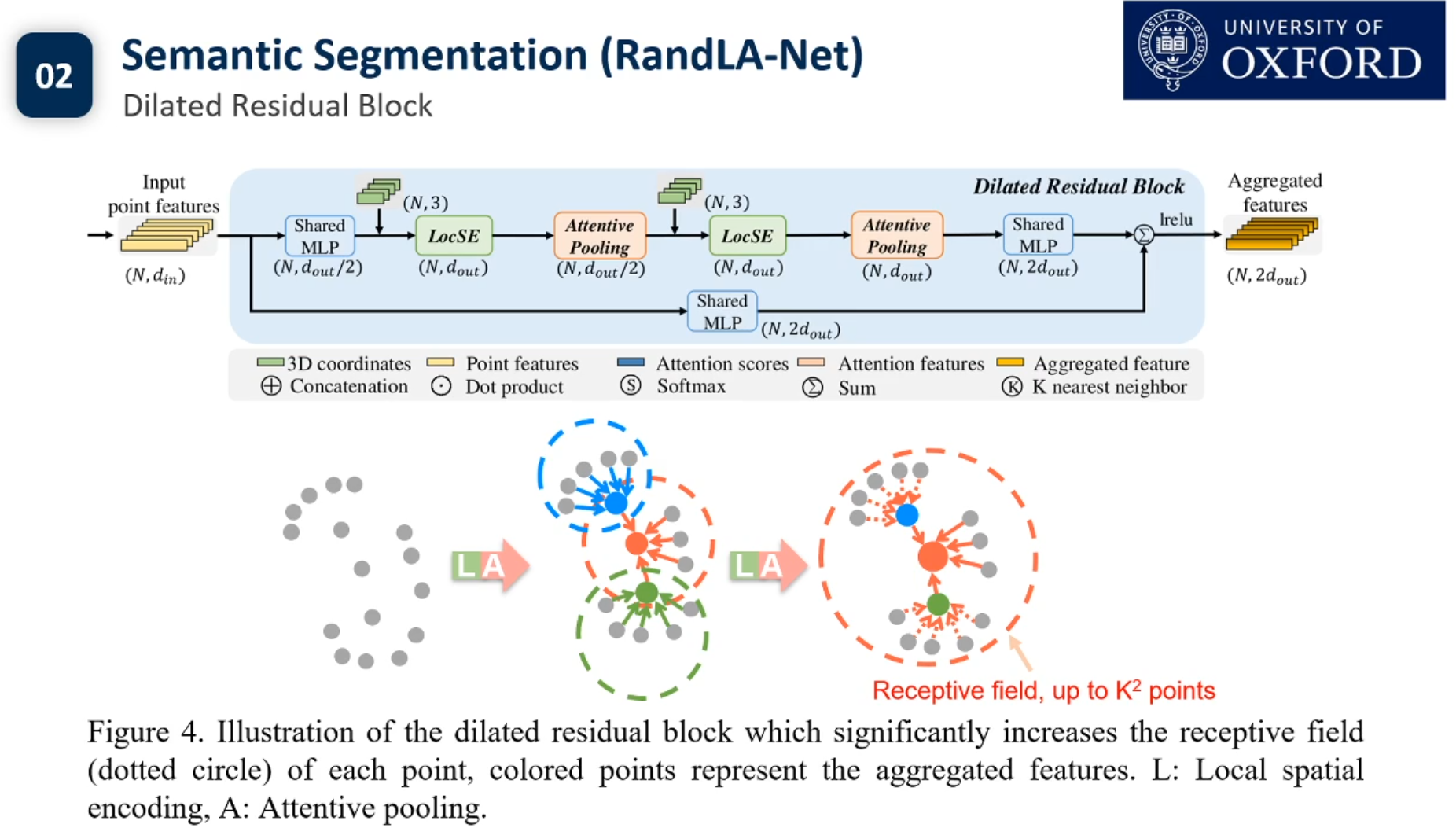
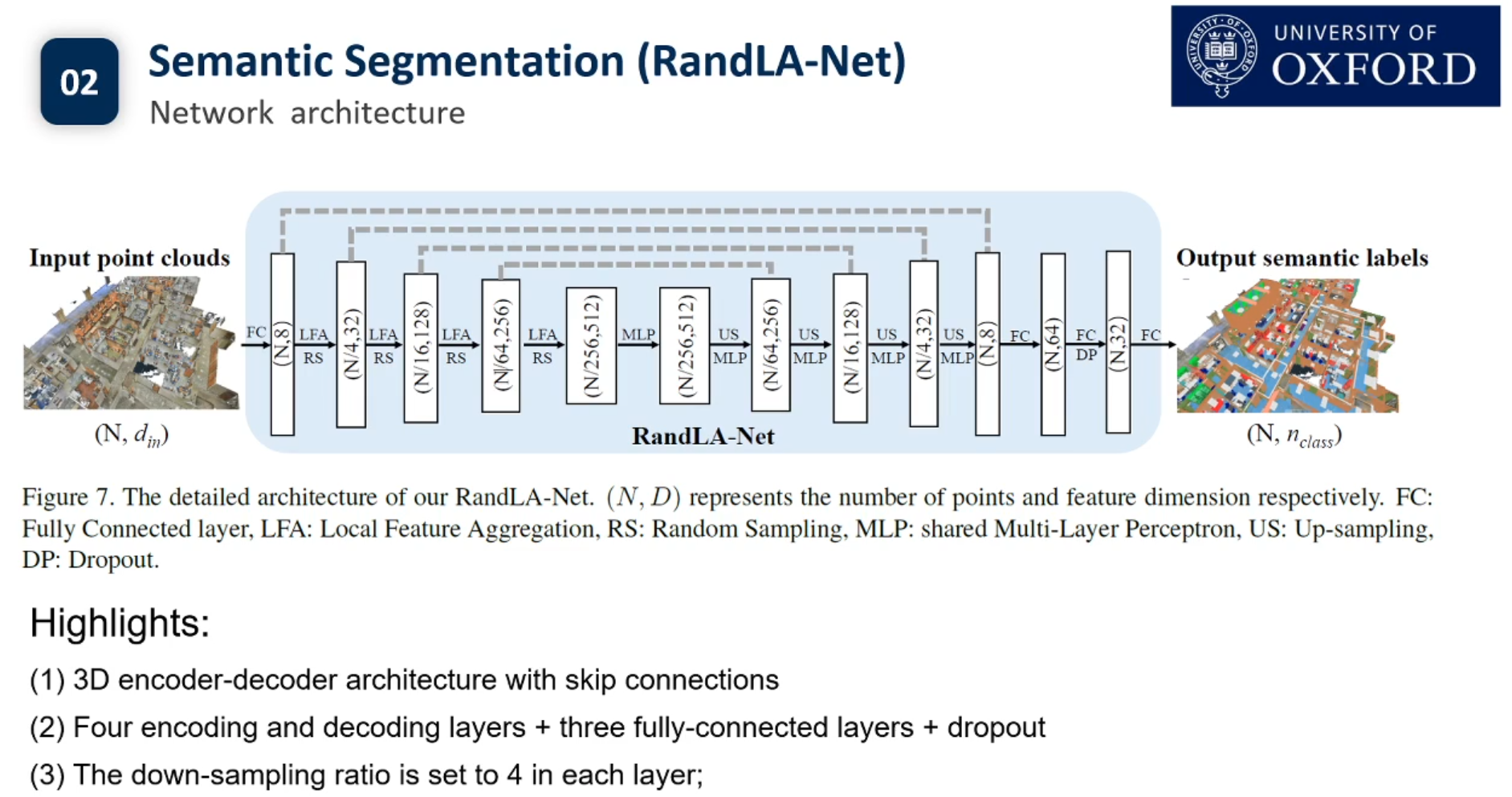
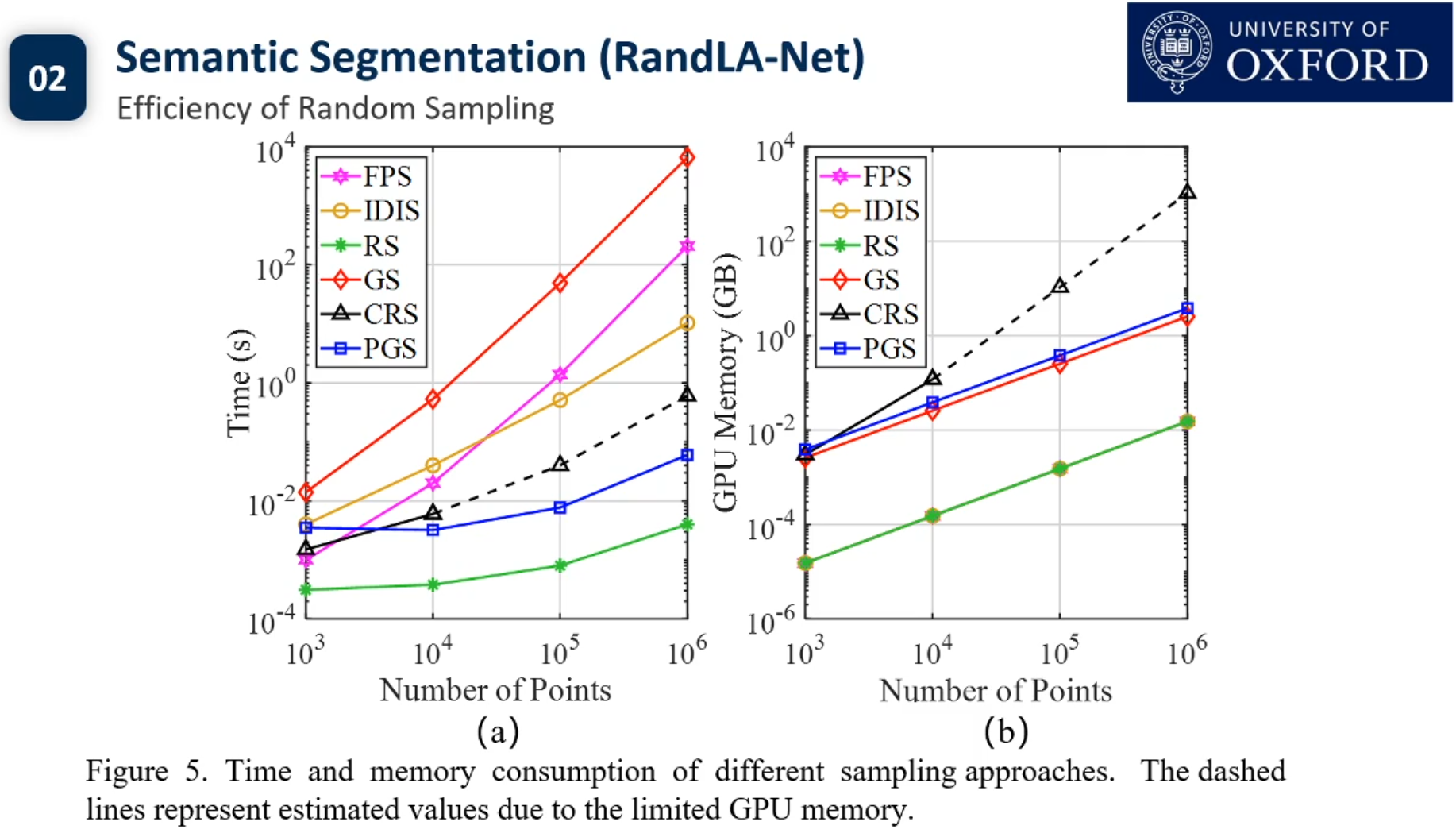
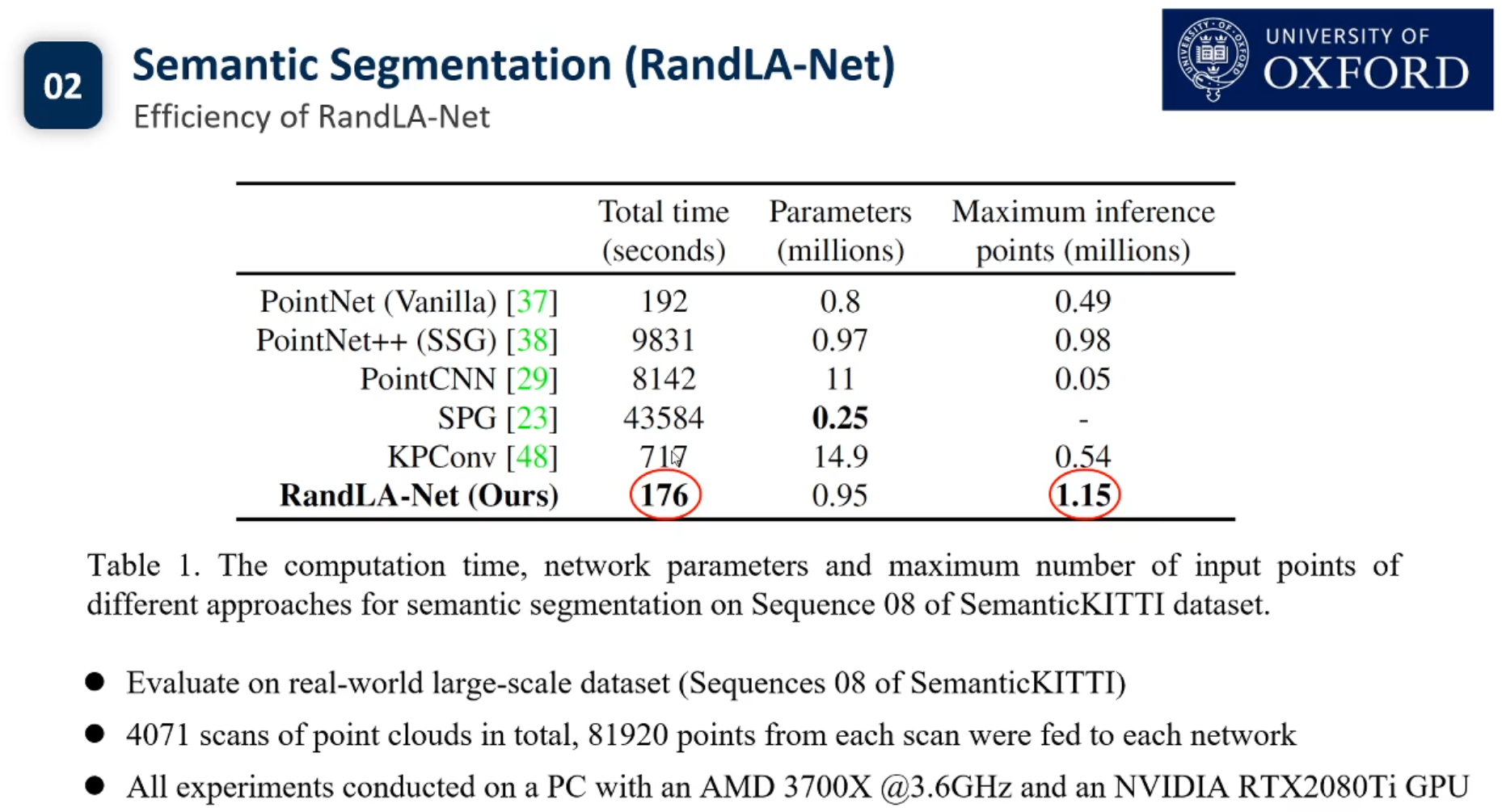
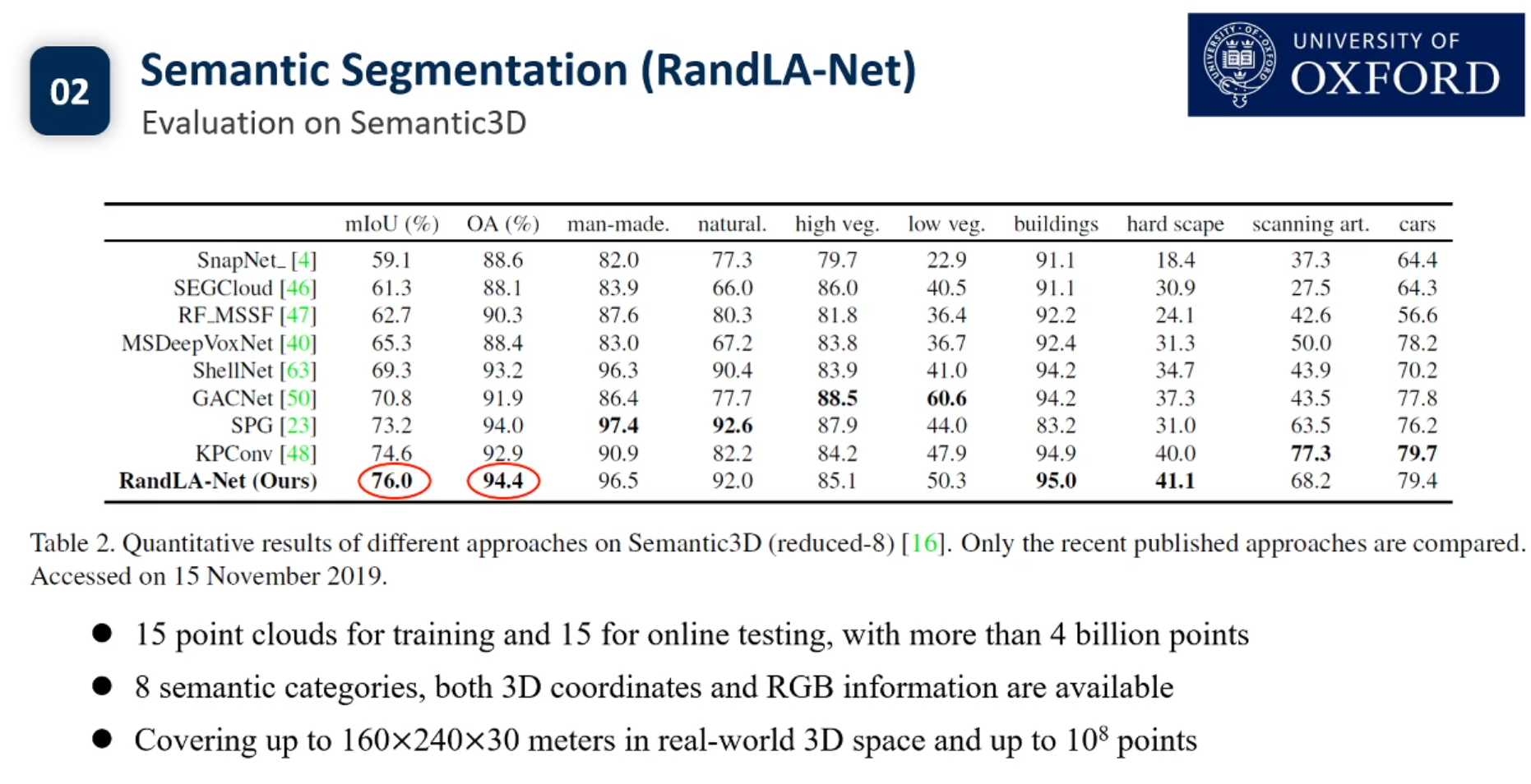
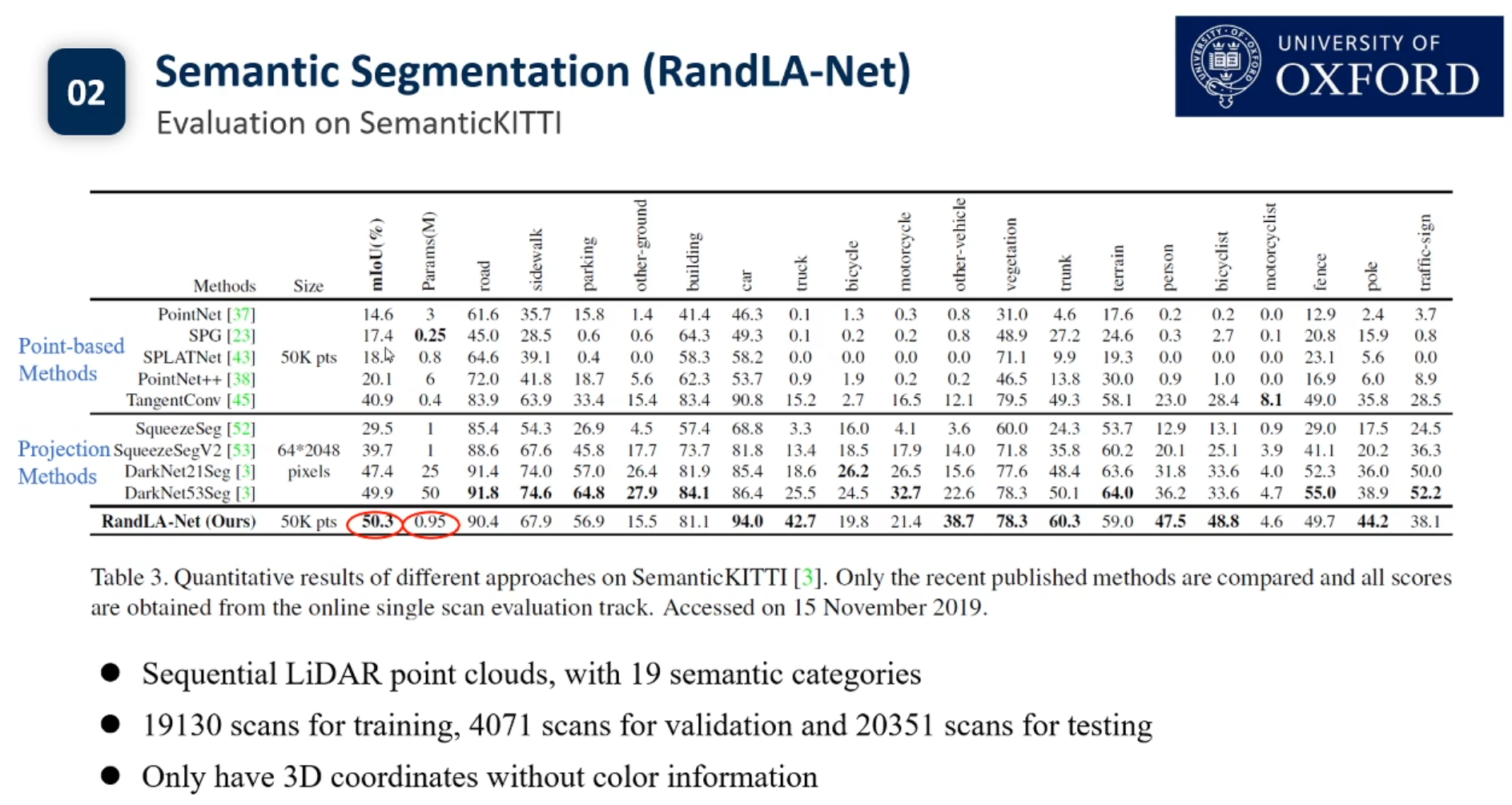
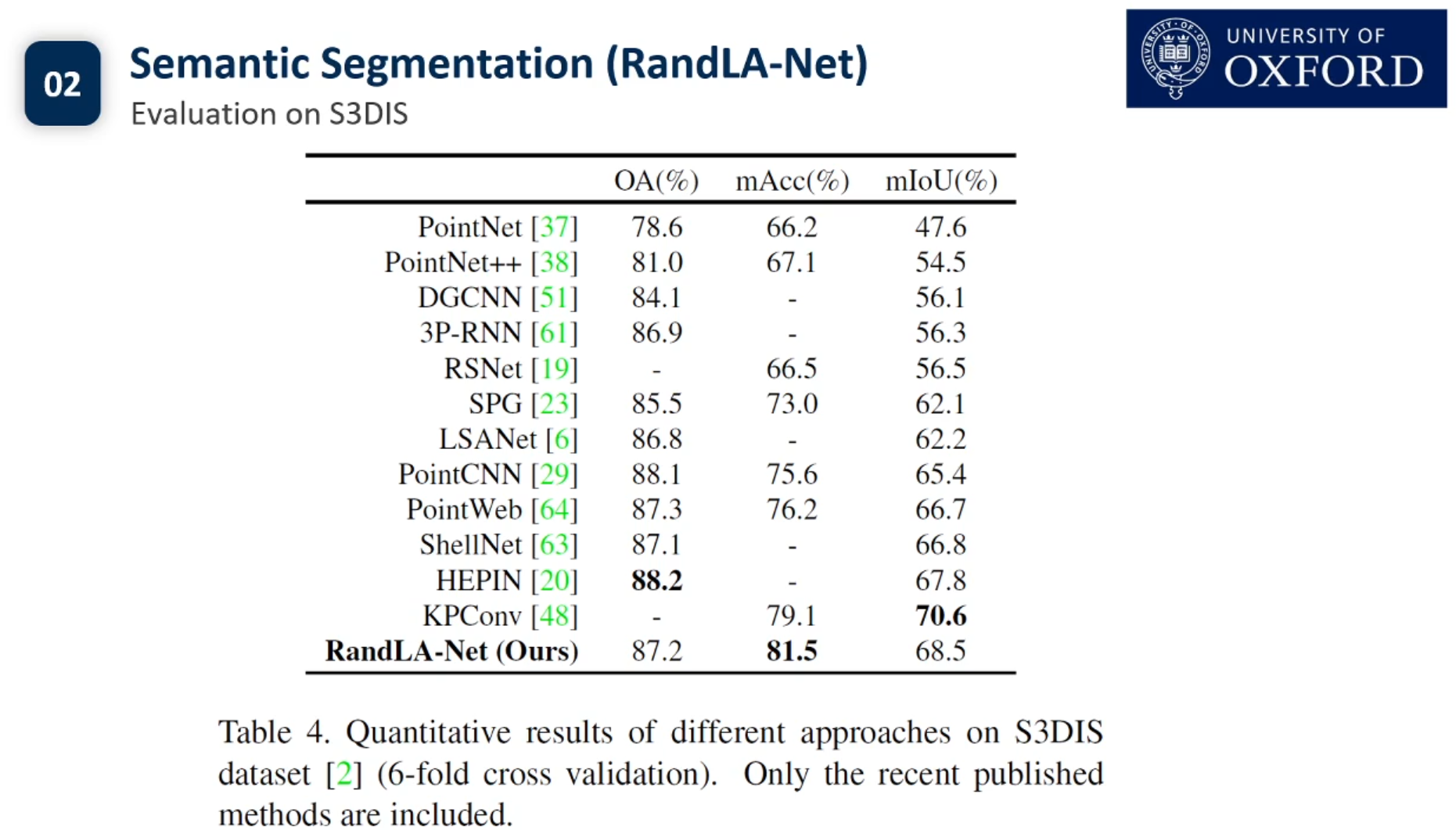
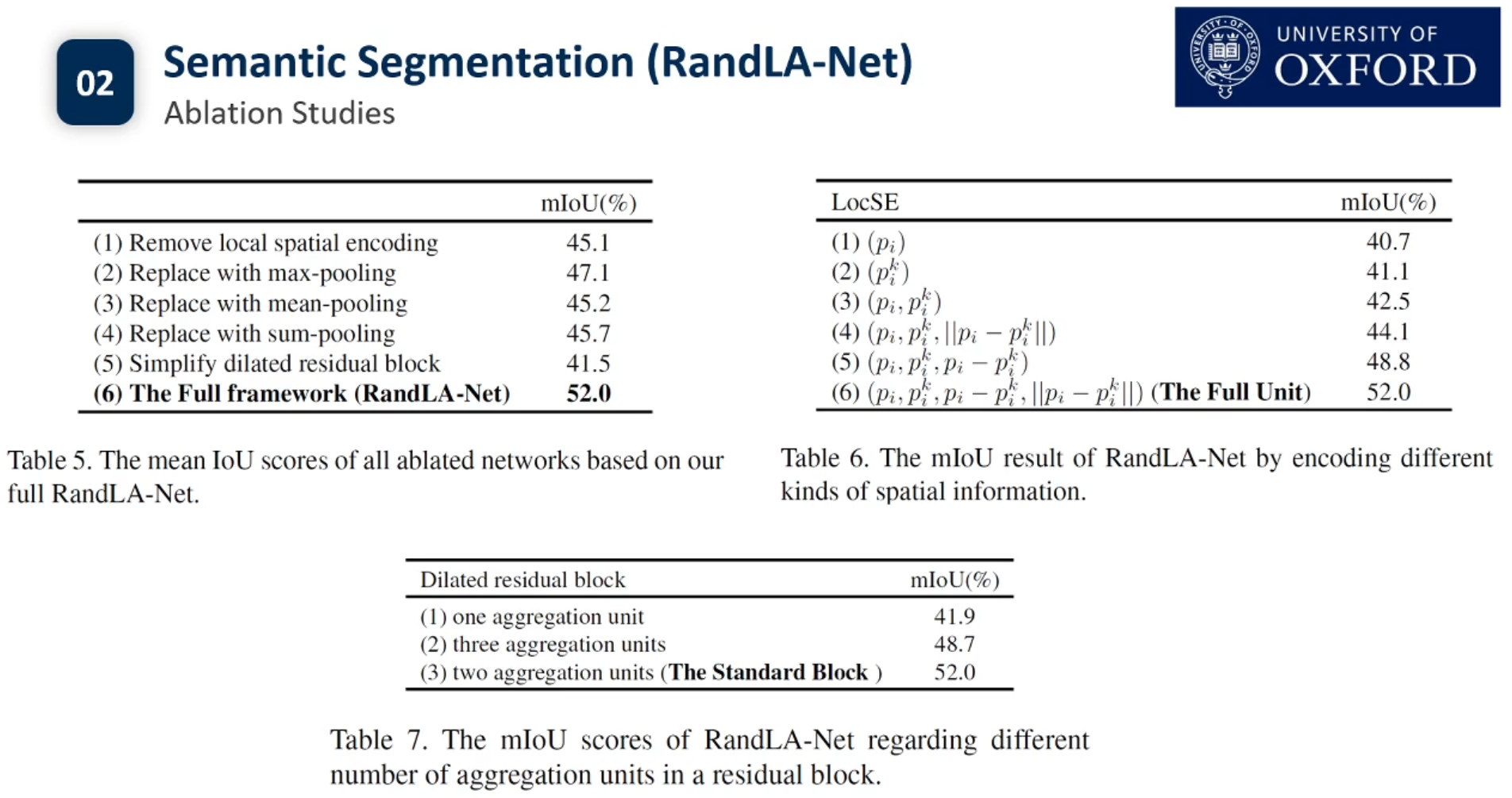



目前3d点云的实例分割还没有Pipeline.