https://www.bilibili.com/video/BV1PW411F7js?p=4&spm_id_from=pageDriver
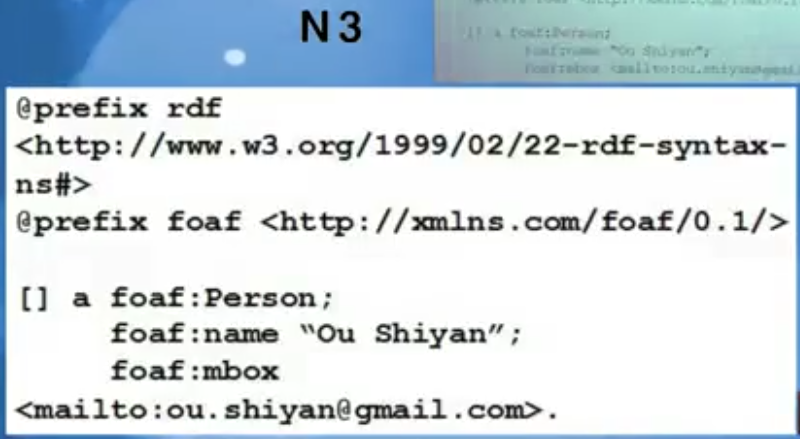
这里是一个文本文档。
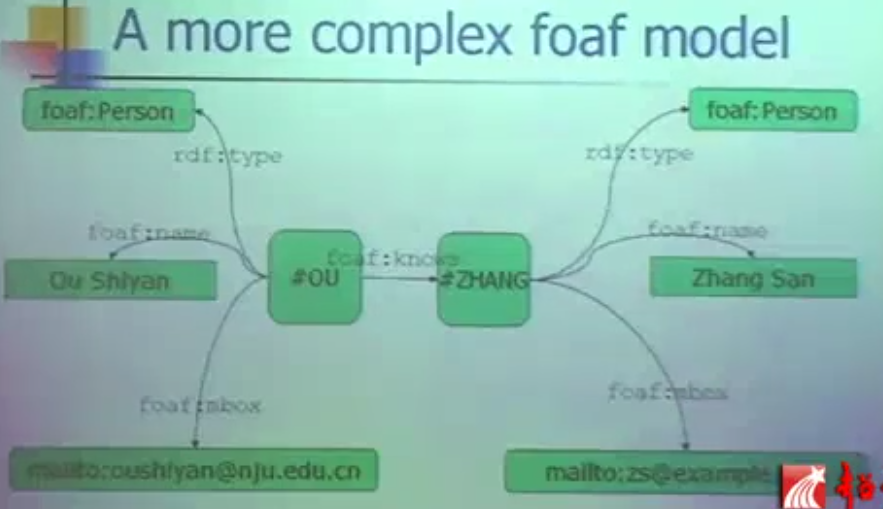
揭示了:我(OU)的信息和张三的信息。
type:类型是人
name:Zhang San
mailbox:邮箱

我认识张三,这是一个有意义的链接。
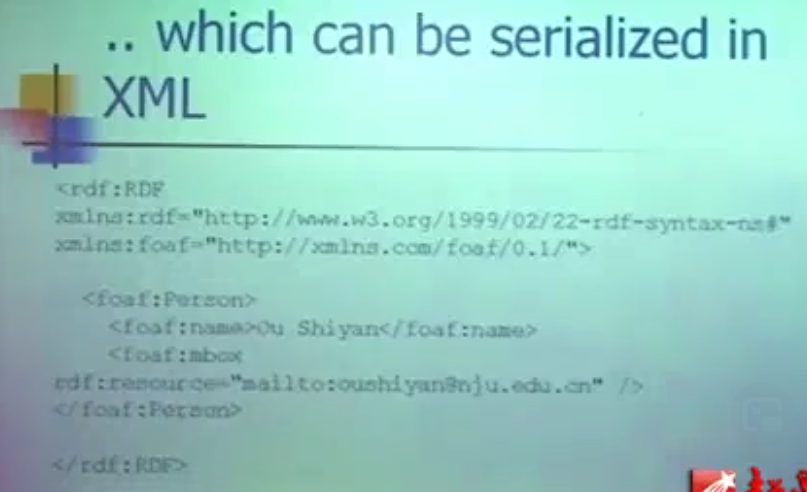
这张图也可以用xml文档来表示:


什么叫元数据?一本书为例,书的书名,作者,出版商这些都是这本书的元数据,所谓元数据,就是描述数据的数据。一个人的话,名字,年龄,籍贯,出生地,性别这些都是这个人的元数据。
其实一个网页也有元数据,比如这个网页的title是什么,uri是什么,创建日期是哪天?创建人是谁?
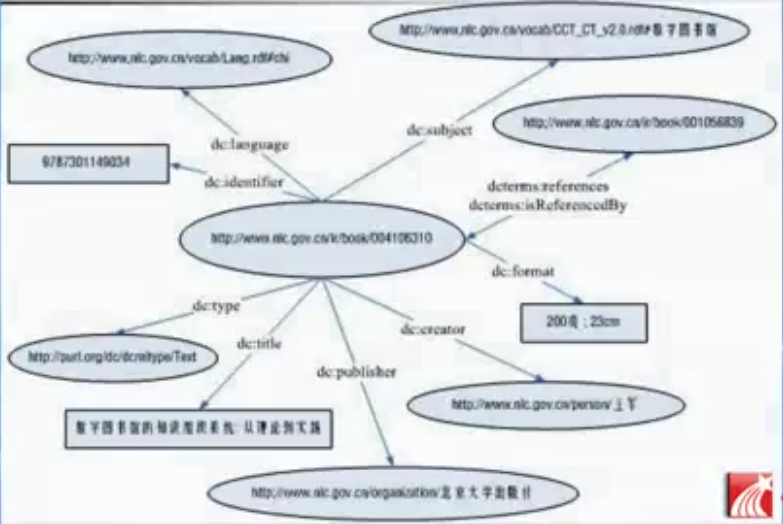
这是关于一本书的描述,下面把它写成RDF的格式:
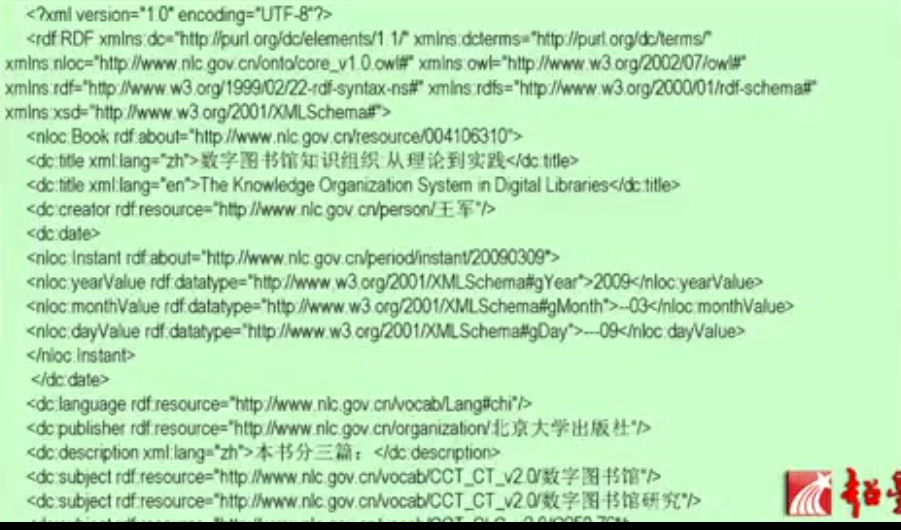
中文标题(title):数字图书馆知识组织 从理论到实践。
英文标题是:
这本书的日期是:2009年3月9号
语言是中文,
出版社是北大
计算机可以自动的去理解和处理这样一个文档。
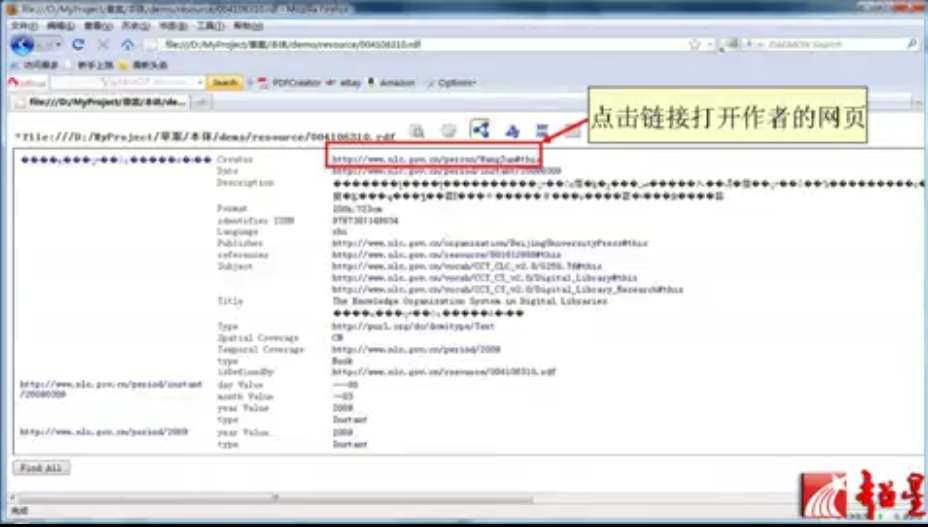
这里显示的就是rdf文档:
火狐浏览器里面已经有插件可以支持显示rdf文档。其他浏览器只能显示html文档。
这个链接显示了两个资源之间的关系。打开这个链接可以显示出创建这个网页的作者,
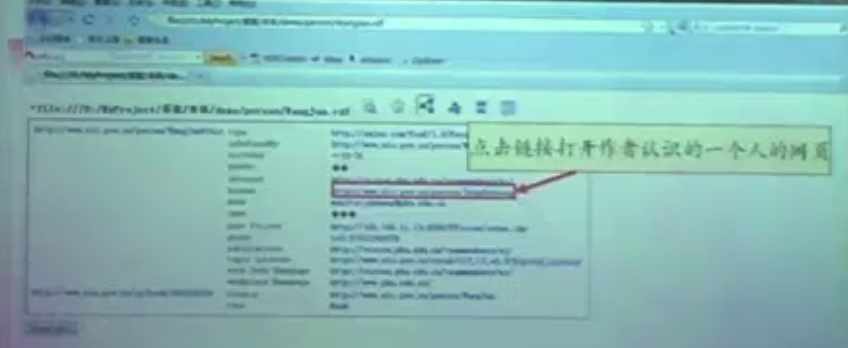
通过这种方式,我可以从一个资源跳转到另一个资源。从一种数据跳转到另一种数据。但是当前的Web网也是不能实现的。因为当前的网页。他的数据集钓的是后端的数据。这些数据库有的存的是人的数据库。有的存的是书的数据库。这些数据库之间是相互独立的。不能相互调用。这个信息之间是不互通的。
语义网不是这样的。假如一个人的籍贯北京,那么点击北京就会跳转到北京这个城。而北京这个城市,上面有一个链接叫长城,那点击这个就会跳转到长城景点。长城是在清朝的时候修建的。可以再点景点上面的一个链接回到秦朝。秦朝这个链接里面有一个秦始皇的链接。点击可以跳转到秦始皇这个人。所有这些异质的数据可以构成一个数据之网。通过这种意义明确的链接,把各种数据整合在了一起。



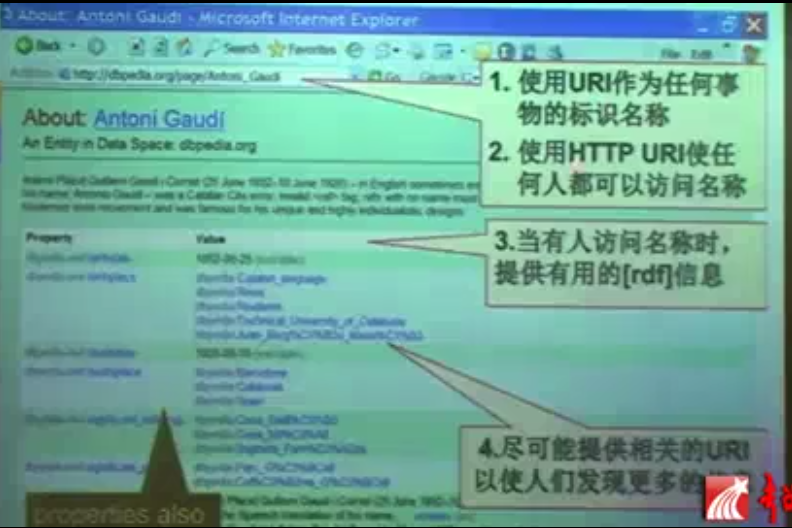
通过这种关联方式,Web上的各种数据都可以关联在一起。

维基百科已经支持这种语义关联的方式,而不是只能访问信息孤岛。
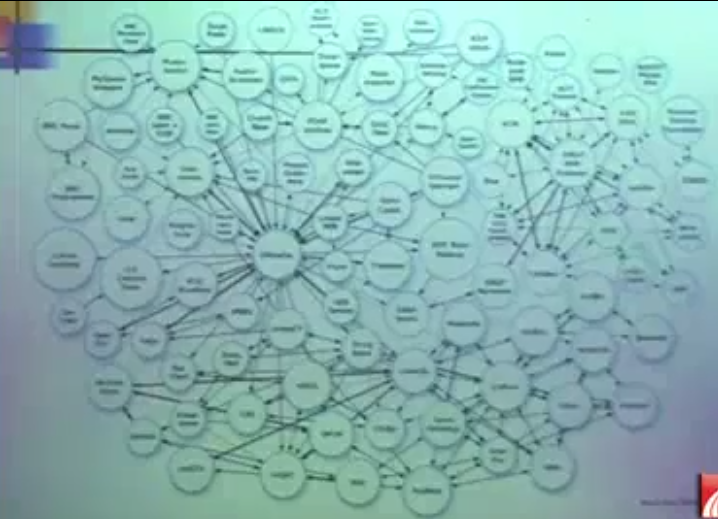

SKOS也是标记语言的一种,是rdf的一种。
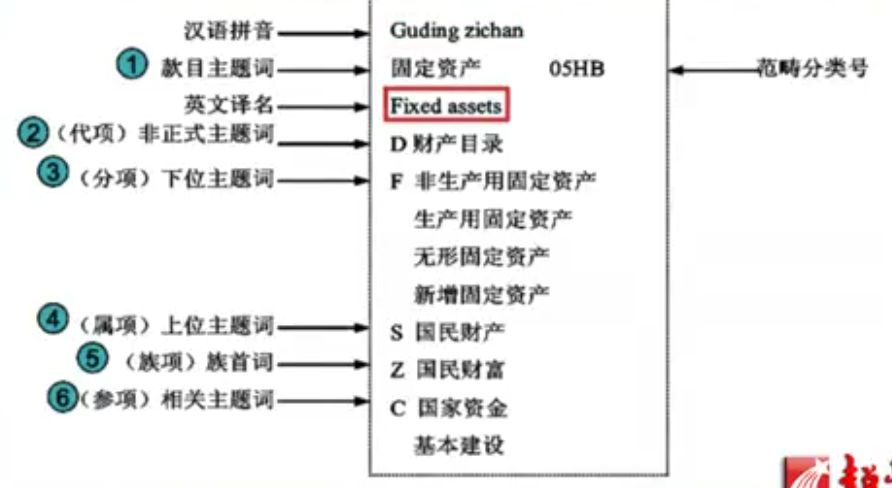
把上面这张图通过语义化的方式来表示出来(rdf格式):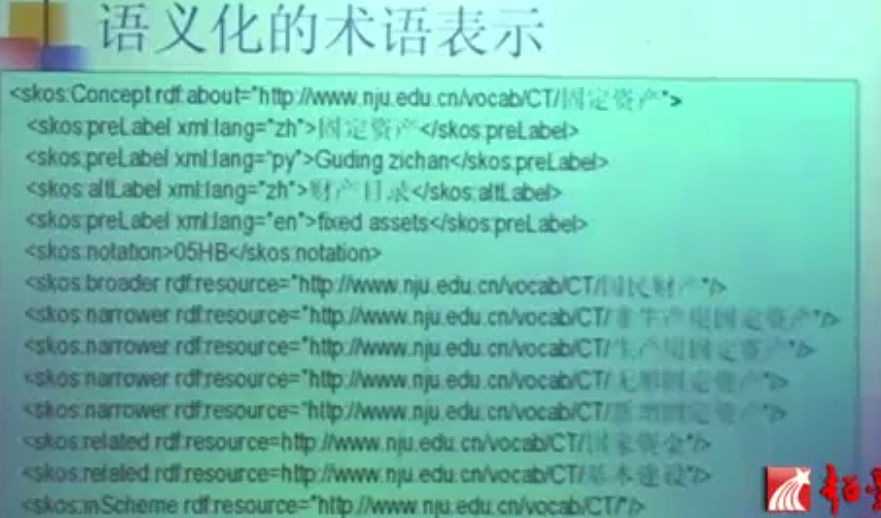
把词表放进去,以Web服务的方式发布出来: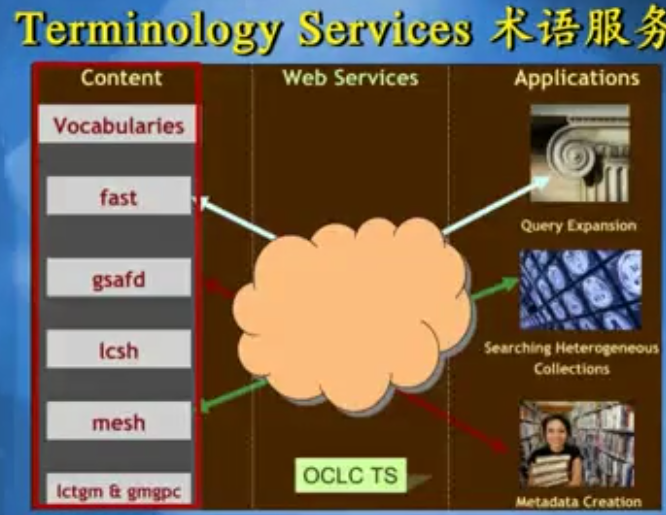

固定资产是他的标签,同时提供给Web的时候。给出他的非正式的标签,叫做财产目录,他们是同义词。
马铃薯是一种植物。同时,在提供给Web服务的时候,还要给他的另一个标签叫做土豆。正式标签叫做马铃薯,非正式标签叫土豆。在搜索引擎中查马铃薯的时候,搜索引擎应同时给出它的同义词叫土豆。这样查的信息才比较全。既查找了马铃薯又查了土豆。这样就不会遗漏掉某些信息。

当前的Web它会怎么做呢?它会这样做:
搜索引擎的后台(这就是目前利用Web的一种方式):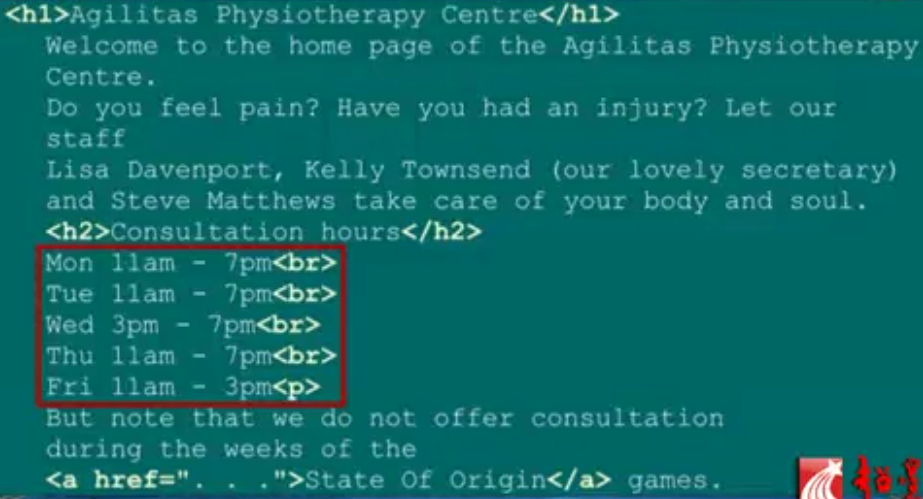
红框中是可以选择的时间。
在(将来)语义网的情况下,看医生的情况又是如何呢?这些事情统统不需要你亲自来做。从智能代理那做。从医生智能代理那做。利用智能代理确定医生的距离。选一个最近距离的医生。然后再结合他们的信誉。然后再看他们能提供的时间。结合这些信息。返回几个推荐的医生。假如找到的时间是上下班的高峰。比较浪费时间。那么就告诉智能代理,让智能代理在网上重新搜索。再调整一个时间。重新推荐。
为什么智能代理能帮他做这些事情呢?是因为这个网站是以一种语义化的格式来表示了。就是rdf的格式来表示了。


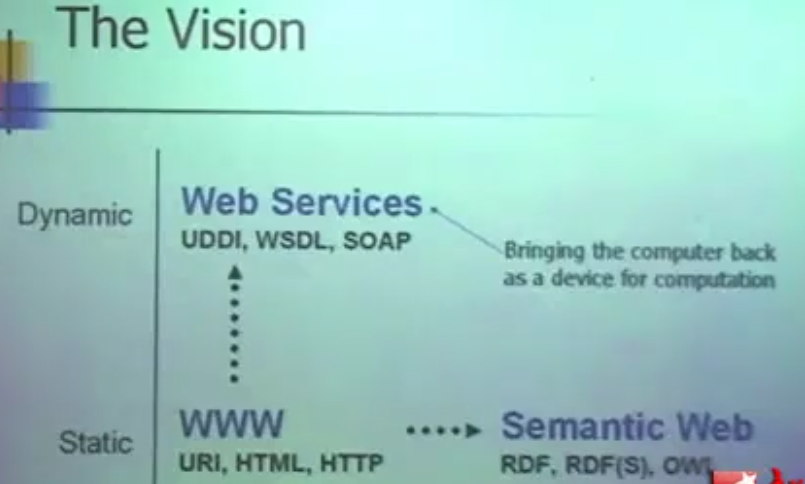
The vision:愿景
