41 快速的复制一张表
create database db1; use db1; create table t(id int primary key, a int, b int, index(a))engine=innodb; delimiter ;; create procedure idata() begin declare i int; set i=1; while(i<=1000)do insert into t values(i,i,i); set i=i+1; end while; end;; delimiter ; call idata(); create database db2; create table db2.t like db1.t
现在把db1.t的数据a>800的数据行导入db2.t
Mysqldump方法
mysqldump -h127.0.0.1 -P3306 -usystem -p --default-character-set=utf8 --no-create-info --single-transaction --set-gtid-purged=OFF db1 t --where="a>800" --result-file=/tmp/t.sql
把结果输出到临时文件
-rw-rw-r-- 1 mysql mysql 4261 Mar 27 08:32 t.sql
生成一个insert语句里面包含多个values对,用这个文件来写入的时候,执行速度可以更快。
--skip-extended-insert 生成多个insert语句。
导入db2
mysql -h127.0.0.1 -P3306 -usystem -p db2 -e "source /tmp/t.sql" (system@127.0.0.1:3306) [test]> select count(*) from db2.t; +----------+ | count(*) | +----------+ | 200 | +----------+
说明,source并不是一条sql语句,而是一个客户端命令,mysql客户端执行命令的流程
--1 打开文件,默认以分好为结尾读取一条条的sql语句
--2 将sql语句发送到服务端执行
在slow log,binlog中,并不会有source出现。
导出csv文件
select * from db1.t where a>800 into outfile '/data/mysqldata/loadfile/t.csv';
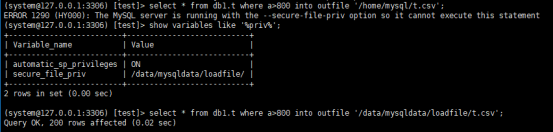
导出的文件路径,参数限制secure_file_priv
--如果设置为empty,表示不限制生成文件的位置,不安全的配置
--设置为一个表示路径的字符串,要求生成的文件只能放在该路径的目录或者子目录
--设置为null,表示禁止这个mysql实例上执行select 。。Into outfile操作。
导入db2
load data infile '/data/mysqldata/loadfile/t.csv' into table db2.t;
执行流程
--1 打开文件csv,以制表符( )作为字段间的分隔符,以换行符( )作为记录之间的分隔符,进行数据读取
--2 启动事务
--3 判断每一行的字段数与表db2.t是否相同
---若不相同,直接报错,事务回滚
---若相同,则构造成一行,调用innodb engine接口,写入到表中
--4 重复步骤3,知道csv整个文件读入完成,提交事务。
如果binlog_format=statement,这个load语句记录到binlog以后,备库怎么重放?
由于csv文件只保存在主库所在的主机上,如果只把这个语句原文写到binlog中,备库在执行的时候,备库的服务器上没有这个文件,就会导致备库报错停止。
所以,这条语句执行的完成流程
--1 主库执行完成后,将csv文件的内容直接写到binlog文件中
--2 往binlog文件中写入语句load data local infile xx into table db2.t
--3 把这个binlog日志传到备库
--4 备库的apply线程在执行这个事务日志时
--a 先将binlog中的t.csv文件的内容读出来,写到本地临时目录中
--b 再执行load data语句,往备库的db2.t表中插入跟主库相同的数据。
-load data中多了local,”将执行这条命令的客户端所在机器的本地文件/tmp/xx的内容,加载到目标表的db2.t中”。
也就是说,load data命令有两种用法
--不加local,是读取服务端的文件,这个文件必须是secure_file_priv指定的路径下
--加local,读取的是客户端文件,只要mysql客户端有访问这个文件的权限,这时候,mysql客户端会先把本地文件传给服务端,然后执行load data
另外注意,select 。。。Into outfile方法不会生成表结构文件,所以在导出数据的时候要另外导出表结构,mysqldump提供 了-tab参数,可以同时导出csv数据文件和表结构定义文件。
mysqldump -h$host -P$port -u$user ---single-transaction --set-gtid-purged=OFF db1 t --where="a>900" --tab=$secure_file_priv
物理拷贝方法
直接把db1.t的frm和idb文件拷贝到db2目录下,是不行的。
Innodb表,除了物理文件外,还需要在数据字典中注册,直接拷贝的话,数据字典是不会识别的。
在mysql5.6引入了可传输表空间(transportable tablespace)方法,具体步骤
--1 执行create table r like t;创建一个相同的表结构的表
--2 执行alter table r discard tablespace 这是r.ibd文件会被删除
--3 执行flush table t export,在db1目录下会生成一个t.cfg文件
--4 在db目录下执行cp t.cfg r.cfg;cp t.ibd r.idb(注意权限)
--5 执行unlock tables,t.cfg文件会删除
--6 执行alter table r import tablespace,将这个r.idb文件作为表r的新的表空间
(system@127.0.0.1:3306) [db1]> use db1 Database changed (system@127.0.0.1:3306) [db1]> create table r like t; Query OK, 0 rows affected (0.06 sec) (system@127.0.0.1:3306) [db1]> system ls -l /data/mysqldata/3306/data/db1/r.* -rw-r----- 1 mysql mysql 8604 Mar 27 09:30 /data/mysqldata/3306/data/db1/r.frm -rw-r----- 1 mysql mysql 114688 Mar 27 09:30 /data/mysqldata/3306/data/db1/r.ibd (system@127.0.0.1:3306) [db1]> alter table r discard tablespace; Query OK, 0 rows affected (0.02 sec) (system@127.0.0.1:3306) [db1]> system ls -l /data/mysqldata/3306/data/db1/r.* -rw-r----- 1 mysql mysql 8604 Mar 27 09:30 /data/mysqldata/3306/data/db1/r.frm (system@127.0.0.1:3306) [db1]> flush table t for export -> ; Query OK, 0 rows affected (0.00 sec) (system@127.0.0.1:3306) [db1]> system ls -l /data/mysqldata/3306/data/db1/t.* -rw-r----- 1 mysql mysql 497 Mar 27 09:31 /data/mysqldata/3306/data/db1/t.cfg -rw-r----- 1 mysql mysql 8604 Mar 27 08:27 /data/mysqldata/3306/data/db1/t.frm -rw-r----- 1 mysql mysql 147456 Mar 27 08:27 /data/mysqldata/3306/data/db1/t.ibd (system@127.0.0.1:3306) [db1]> system cp /data/mysqldata/3306/data/db1/t.ibd /data/mysqldata/3306/data/db1/r.ibd (system@127.0.0.1:3306) [db1]> system cp /data/mysqldata/3306/data/db1/t.cfg /data/mysqldata/3306/data/db1/r.cfg (system@127.0.0.1:3306) [db1]> system ls -l /data/mysqldata/3306/data/db1/r.* -rw-r----- 1 mysql mysql 147456 Mar 27 09:34 /data/mysqldata/3306/data/db1/r.cfg -rw-r----- 1 mysql mysql 8604 Mar 27 09:30 /data/mysqldata/3306/data/db1/r.frm -rw-r----- 1 mysql mysql 147456 Mar 27 09:34 /data/mysqldata/3306/data/db1/r.ibd (system@127.0.0.1:3306) [db1]> unlock tables; Query OK, 0 rows affected (0.00 sec) (system@127.0.0.1:3306) [db1]> alter table r import tablespace; Query OK, 0 rows affected (0.02 sec) (system@127.0.0.1:3306) [db1]> select count(*) from r; +----------+ | count(*) | +----------+ | 1000 | +----------+ 1 row in set (0.00 sec)
注意,如果出现
(system@127.0.0.1:3306) [db1]> alter table r import tablespace;
ERROR 1810 (HY000): IO Read error: (139863127226208, (null)) (null)
要查看文件以及文件的权限是否都正确。
流程的注意点
--1 执行完flush table之后,db1.t整个表处于只读状态,直到执行unlock tables命令后才释放
--2 在执行import tablespace的时候,为了让文件里的表空间id和数据字典一致,会修改r.ibd的表空间id,而这个表空间id存在于每个页中,
因此,如果一个很大的文件,每个数据页都需要修改,可能会花很长时间,但是相比于mysqldump,还是比较快的。
最后,可以使用pt的工具
pt-archiver--将表数据归档到另一个表或文件中
删除或归档一张大表,导出文件等,可以进行主从同步数据 [mysql@mysqlt1 bin]$ ./pt-archiver --help Archive all rows from oltp_server to olap_server and to a file: pt-archiver --source h=oltp_server,D=test,t=tbl --dest h=olap_server --file '/var/log/archive/%Y-%m-%d-%D.%t' --where "1=1" --limit 1000 --commit-each Purge (delete) orphan rows from child table: pt-archiver --source h=host,D=db,t=child --purge --where 'NOT EXISTS(SELECT * FROM parent WHERE col=child.col)'