Memcached无底洞现象
什么是缓存无底洞问题
无底洞现象是facebook的工作人员反应的,facebook在2010年左右,memcached已经达到3000个,存储着数千G的缓存。
他们发现一个问题:memcached连接频繁,效率下降了,于是加memcached服务器节点,添加后发现因为连接频率导致的问题仍然存在,并没有好转 ===> 称之为“无底洞效应”。
缓存无底洞产生的原因
键值数据库或者缓存系统,由于通常采用hash函数将key映射到对应的实例,造成key的分布与业务无关,但是由于数据量、访问量的需求,需要使用分布式后(无论是客户端一致性哈性、redis-cluster、codis),批量操作比如批量获取多个key(例如redis的mget操作),通常需要从不同实例获取key值,相比于单机批量操作只涉及到一次网络操作,分布式批量操作会涉及到多次网络io。
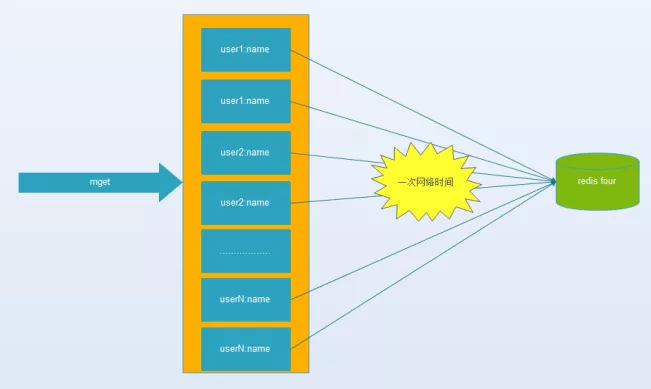

当服务器增多,用户的信息也被散落在更多的服务器节点,所以,由于同一个人的信息散落到不同的服务器节点,虽然是访问同一个人的信息,也需要连接更多的服务器节点,因此性能并没有随着服务器节点的增多而降低。
无底洞问题带来的危害
(1) 客户端一次批量操作会涉及多次网络操作,也就意味着批量操作会随着实例的增多,耗时会不断增大。
(2) 服务端网络连接次数变多,对实例的性能也有一定影响。
用一句通俗的话总结:更多的机器不代表更多的性能,所谓“无底洞”就是说投入越多不一定产出越多。
分布式又是不可以避免的,因为我们的网站访问量和数据量越来越大,一个实例根本坑不住,所以如何高效的在分布式缓存和存储批量获取数据是一个难点。
解决方案
把某一组key,按照共同的前缀,来分布,比如 user-133-age,user-133-name,user-133-height这个3个key,在用分布式算法求节点时,应该可以用user-133来计算而不是以 user-133-age来计算,这样3个关于个人的信息的key都落到了同一个节点上,点击的访问个人主页的时,只需要连接1个节点。
原文地址:https://www.cnblogs.com/yhq-qhh/p/10116053.html