1. 近期目标,实现随机森林进行点云分类
1)学习阶段:
Kaggle Machine Learning Competition: Predicting Titanic Survivors
Kaggle Titanic 生存预测 -- 详细流程吐血梳理
https://www.codeproject.com/Articles/1197167/Random-Forest-Python
https://blog.csdn.net/hexingwei/article/details/50740404
2)实践阶段:
(1)原始点云字段(X,Y,Z,density,curvature,Classification),利用点云的高程Z,密度和曲率进行train和分类。分类结果很差就是了。
需要考虑哪些特征对分类结果的影响比较大?用什么样的点云特征更好,特征工程问题?


1 # -*- coding: utf-8 -*- 2 """ 3 Created on Sat Nov 10 10:12:02 2018 4 @author: yhexie 5 """ 6 import numpy as np 7 import pandas as pd 8 from sklearn import model_selection 9 from sklearn.ensemble import RandomForestClassifier 10 11 df = pd.read_csv('C:/Users/yhexie/.spyder-py3/pointcloudcls/train_pcloud2.csv', header=0) 12 x_train = df[['Z','Volume','Ncr']] 13 y_train = df.Classification 14 15 df2 = pd.read_csv('C:/Users/yhexie/.spyder-py3/pointcloudcls/test_pcloud2.csv', header=0) 16 x_test = df2[['Z','Volume','Ncr']] 17 18 clf = RandomForestClassifier(n_estimators=10) 19 clf.fit(x_train, y_train) 20 clf_y_predict = clf.predict(x_test) 21 22 data_arry=[] 23 data_arry.append(df2.X) 24 data_arry.append(df2.Y) 25 data_arry.append(df2.Z) 26 data_arry.append(clf_y_predict) 27 28 np_data = np.array(data_arry) 29 np_data = np_data.T 30 np.array(np_data) 31 save = pd.DataFrame(np_data, columns = ['X','Y','Z','Classification']) 32 save.to_csv('C:/Users/yhexie/.spyder-py3/pointcloudcls/predict_pcloud2.csv',index=False,header=True) #index=False,header=False表示不保存行索引和列标题
(2)对训练集进行split,用75%的数据训练,25%的数据验证模型的拟合精度和泛化能力。
a. 增加定性特征,进行dummy处理。
目前采用Z值和8个特征相关的点云特征进行分类,点云近邻搜索半径2.5m
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Wed Nov 28 10:54:48 2018 4 5 @author: yhexie 6 """ 7 8 import numpy as np 9 import pandas as pd 10 import matplotlib.pyplot as plt 11 from sklearn import model_selection 12 from sklearn.ensemble import RandomForestClassifier 13 14 df = pd.read_csv('C:/Users/yhexie/.spyder-py3/pointcloudcls/train_pc.csv', header=0) 15 x_train = df[['Z','Linearity', 'Planarity','Scattering','Omnivariance', 'Anisotropy', 16 'EigenEntropy','eig_sum' ,'changeOfcurvature']] 17 y_train = df.Classification 18 19 from sklearn.cross_validation import train_test_split 20 train_data_X,test_data_X,train_data_Y,test_data_Y = train_test_split(x_train, y_train, test_size=0.25, random_state=33) 21 22 df2 = pd.read_csv('C:/Users/yhexie/.spyder-py3/pointcloudcls/test_pc.csv', header=0) 23 x_test = df2[['Z','Linearity', 'Planarity','Scattering','Omnivariance', 'Anisotropy', 24 'EigenEntropy','eig_sum' ,'changeOfcurvature']] 25 26 clf = RandomForestClassifier(n_estimators=10) 27 clf.fit(train_data_X, train_data_Y) 28 29 print('Accuracy on training set:{:.3f}:'.format(clf.score(train_data_X,train_data_Y))) 30 print('Accuracy on training set:{:.3f}:'.format(clf.score(test_data_X,test_data_Y))) 31 print('Feature inportances:{}'.format(clf.feature_importances_)) 32 n_features=9 33 plt.barh(range(n_features),clf.feature_importances_,align='center') 34 plt.yticks(np.arange(n_features),['Z','Linearity', 'Planarity','Scattering','Omnivariance', 'Anisotropy', 35 'EigenEntropy','eig_sum' ,'changeOfcurvature']) 36 plt.xlabel('Feature importance') 37 plt.ylabel('Feature') 38 39 clf_y_predict = clf.predict(x_test) 40 41 data_arry=[] 42 data_arry.append(df2.X) 43 data_arry.append(df2.Y) 44 data_arry.append(df2.Z) 45 data_arry.append(clf_y_predict) 46 47 np_data = np.array(data_arry) 48 np_data = np_data.T 49 np.array(np_data) 50 save = pd.DataFrame(np_data, columns = ['X','Y','Z','Classification']) 51 save.to_csv('C:/Users/yhexie/.spyder-py3/pointcloudcls/predict_pcloud2.csv',index=False,header=True) #index=False,header=False表示不保存行索引和列标题
计算结果:可以看到在测试集上的结果还是很差
1 Accuracy on training set:0.984: 2 Accuracy on test set:0.776:
特征重要程度:
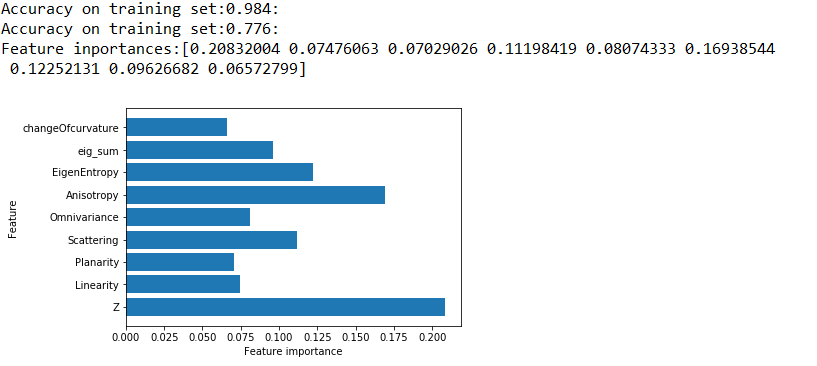
新的测试:
Accuracy on training set:0.994:
Accuracy on training set:0.891:
Feature inportances:[0.02188956 0.02742479 0.10124688 0.01996966 0.1253002 0.02563489
0.03265565 0.100919 0.15808224 0.01937961 0.02727676 0.05498342
0.0211147 0.02387439 0.01900164 0.023478 0.02833916 0.0302441
0.02249598 0.06629199 0.05039737]
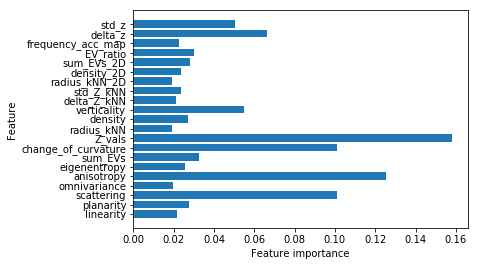

感觉Z值的重要程度太高了。房屋分类结果应该是很差,绿色的很多被错误分类了。
问题:目前训练集中的每个类别的样本数目并不相同,这个对训练结果有没有影响?