记录多语言机器翻译论文的笔记.....防止遗忘,会持续更新!
Three Strategies to Improve One-to-Many Multilingual Translation ACL2018
探索one-to-many 多语翻译中,在统一enc-dec结构下,decoder中共享部分和独立部分的平衡点:
- 不同tgt有不同的初始状态/标签:给src、tgt都添加语言指示;
- 语言相关的位置编码:we introduce trigonometric functions with different orders or offsets on the decoder to distinguish different target languages.或者用dynamic embedding,给不同目标端的输入绝对位置编码;
- (训练,解码时)把decoder的隐藏层状态分为共享/语言相关的:

试验中:把1,2,3结合在zh-en上效果最好
利用富资源来提升低资源的翻译质量。当富资源与低资源共享单词或者句法上相似时,帮助效果更好。
Generalized Data Augmentation for Low-Resource Translation ACL2019
在低资源机翻中提出通用框架,利用:目标端单语,相关的富资源语言作为中枢
- 假设有富资源-目标,富资源-低资源之间的pair足量;
- 富、低、目标语言单语足量
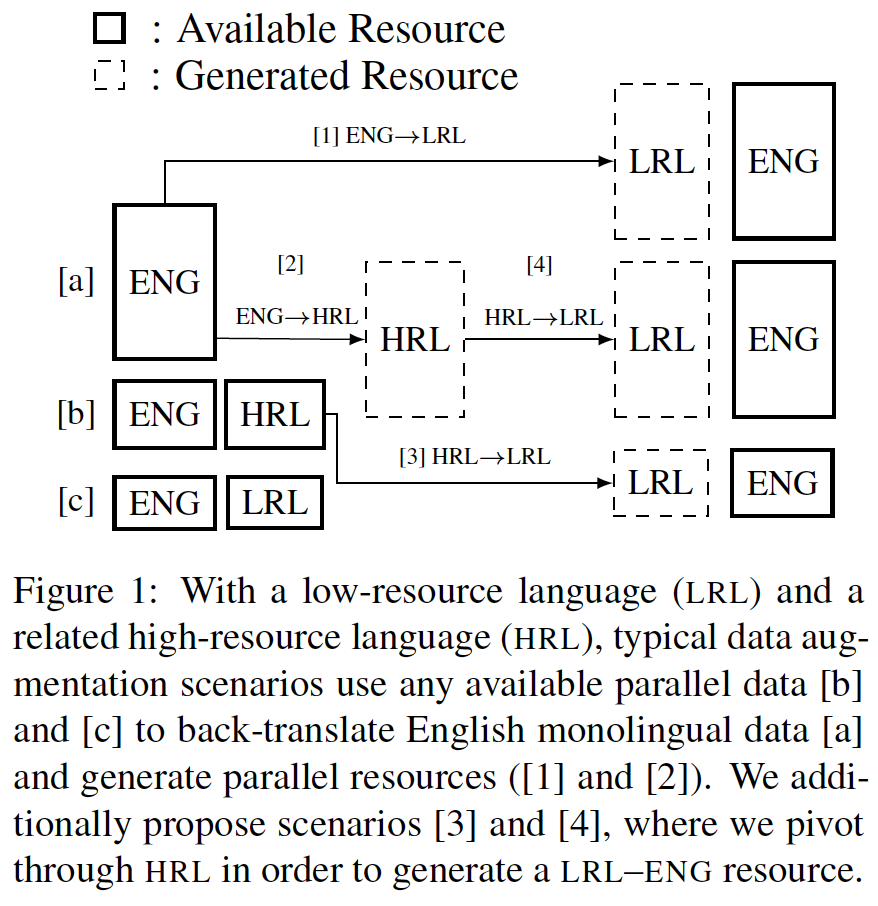
两种增强平行数据的方法:
- Augmentation via Pivoting,利用TGT单语,假设为ENG,反向翻译为LRL(低资源)/HRL(富资源);
-
- TGT->HRL->LRL (有用:加入了额外的TGT语言提升目标端语言;可能在语言之间共享词汇/子词;HRL和LRL句法相似,可以联合学习encoder的参数 )
- TGT->LRL
-
- 把HRL-TGT(ENG)的源端(HRL)翻译为LRL. -> pseudo LRL-TGT数据集:该方法可能会存在HRL-LRL资源不足,但因为HRL,LRL语言相似,方法倒是简单
两种LRL -> HRL Translation Methods:
1.通过一个归纳双语词典,把低资源的词inject到富资源的句子中
- 把HRL-TGT 、 TGT单语BT得到的 HRL'-TGT 中的HRL词替换为LRL词,不在词典中的词就不管
word embedding spaces share similar innate structure over different languages; it’s more likely to create a high-quality bilingual dictionary for two highly-related languages
-
- 通过有监督的方法获得双语词典
2.用一个修改过的无监督机器翻译框架来进一步edit 上述 modified pseudo-LRL 的句子
初始化模型:
- 上述的词汇替换方法
- 用替换HRL得来的假LRL和真实LRL一起学习联合分词模型
- 用假的LRL和真实LRL进行训练,目标函数:DAE和迭代BT的加权和(IBT用greedy search)
再用替换HRL得到的伪平行语料训练无监督机器翻译模型,最后用UMT翻译伪平行语料中的伪LRL。
Multilingual Neural Machine Translation with Language Clustering 2019
Adapting High-resource NMT Models to Translate Low-resource Related Languages without Parallel Data ACL2021
---------利用单语进行帮助----------
Multi-task Learning for Multilingual Neural Machine Translation EMNLP2020
一句话总结:多任务学习的损失= 在bilingual上的MT loss+目标端单语DAE的loss+源端单语MLM的loss
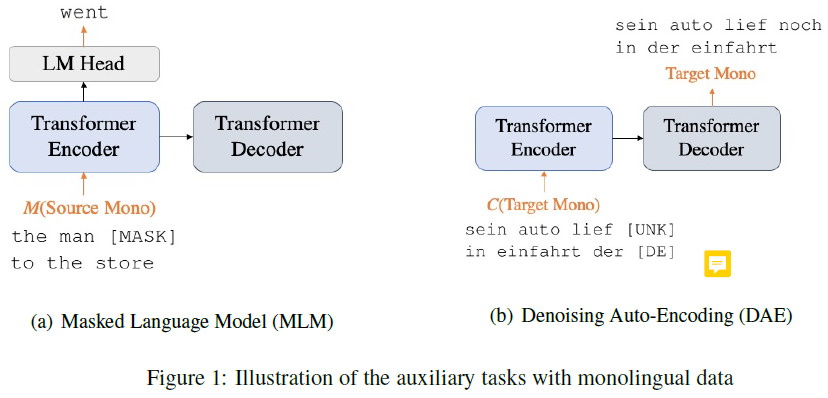
对翻译和DAE任务,要在输入句添加tgt语言标签。
(DAE和MLM都属于denoising language model,DAE的三种噪音:text filling、Word Drop & Word Blank、Word Swapping)
还有两个trick:
- 动态温度采样(linear)——解决低、富资源数据不平衡导致富资源翻译质量下降的问题,让训练数据先是真实的数据分布->逐步shift到均匀的数据分布
 ,N为warmup epoch,Tm和To对应最大温度和最小温度。温度采样可以参照xlm论文中的讲解。To = 1; Tm = 5;N =5.
,N为warmup epoch,Tm和To对应最大温度和最小温度。温度采样可以参照xlm论文中的讲解。To = 1; Tm = 5;N =5. - 动态噪音比例(类上)——课程学习的思想,由简单到难,对应噪音数据的ratio由小到大
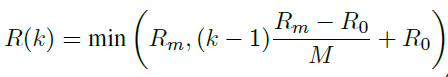 ,M为warmup epoch
,M为warmup epoch
结果:
BT和MTL用的单语是一样的,BT和MTL都有效果,把BT和MTL结合起来效果最好.
zero-shot实验(many-many模型),富资源:有可能是BT的质量不高,MTL+BT比BT效果好很多,而pivot比MTL+BT效果更好;低资源:BT+MTL效果最好
MTL对比mBART,EN-X语言对上,MTL效果都好与mBART,何况mBART用的单语规模更大
消融实验比较目标函数:DAE的影响更大,DAE+MLM效果最好,MLM对低资源源端语言建模和encoder有帮助
动态温度采样:对比固定温度T=5,动态策略在富资源和低资源上都有提升,尤其是低资源,对中资源影响小
噪音策略:MLM:token、word level;DAE:word、span level。三种组合如下,黄色指示的组合是效果最好的
![]()
动态噪音比率:MLM mask比率10%、20%;DAE 噪音比率20%、40%,动态噪音策略对中资源语对由有提示,对其他语言影响不大
---------大规模MNMT---------
Massively Multilingual Neural Machine Translation 2019
关注以英语为中心的语言对:EN-X,X-EN。建立一个universal的many to many NMT,支持102种语言
低资源实验数据集是TED,支持 to-and-from English的58+EN=59种语言,验证了大规模多到多的模型在low resource的有效性,能在使用大模型的同时防止过拟合,在X-EN方向上达到SOTA结果。
富资源实验是在102+EN=103种语言上训练的,共204个方向,平均每个句对100w行,实验结果表明在10个不同方向语对上比bilingual的基线要好2个bleu。
最后分析了在翻译所支持语对的数量上和翻译准确率之间有tradeoff,表示了大规模多语模型在zero-shot场景下generalize better
训练时提升语言的数量可能会有迁移学习,导致不同翻译任务之间能共享信息会增加,模型也能嘘唏共享哪些信息;但是一方面增加语言的数量会让翻译任务增加,如果在所有语言之间共享参数,可能导致模型有性能瓶颈,这样不同语言的性能可能达不到最好
实验设置:
TED,语对数据极其不平衡,学习联合BPE 32k。给src句加上tgt的语言标签
验证集是所有单独语对dev concat后的均匀采样;
异质batching:训练集是把所有训练数据conca后均匀采样作为batch,长句16句,短句64句为一个batch,未用过采样。
低资源结果
- many-many在 X-> EN 优于many-one的模型,可能原因是(multiple target language pairs which may act as regularizers).
- 在one-many中,低高资源 EN-> X 的场景下,都比many-many的要好( English being over-represented in the English-centric many-to-many setting)
- increasing the number of source languages also causes additional degradation in a many-to-many model. This degradation may be due to the English-centric setting
富资源结果
- 与低资源相反,many-one在 X-> EN 优于many-many的模型,
when the training data is large enough and not multi way- parallel there is no overfitting in the many-to one model
- 与低资源结果一致,one-many比many-many好
作者还进行了 模型参数和capacity不变时,变化语言数量的实验,结果表明增加语言数量由 5-> 103种时,BLEU(收敛)下降了2个点,需要在模型capacity和语言的数量上找到trade off
Massively Multilingual Neural Machine Translation in the Wild: Findings and Challenges 2019
数据与上文章类似,都是102种语言,文章有很多经验性的结论:
MNMT上的提升可能是相关领域和可迁移任务带来的正向迁移。
探索了
单模型:数据集大小和语言数量对其的影响(语言数目由10增加到102,几乎所有语对的翻译质量都会下降,尤其是富/中资源)
数据集中语言不均衡的问题(温度采样T=5/100,过采样后在富资源会下降一点,低资源上会有提升)
transfer和interference之间的影响(如何最大程度的正向迁移到低资源,最小程度的减少最富资源语言的影响)
探索了词表大小对模型的影响,64k比32k普遍好一点,但是影响不是很大,在en-X的低资源则是小词表更好。
zero-shot的性能在增加语言数量时会上升
对比了big、wide、deep模型,deep在模型参数量和wide相等时效果更优,在en-X上差距不大,在X-en上差距较大,deep效果比其他两个都好,deep除了层数增加其他参数与big一致,wide在低资源上过拟合很厉害。