容器与虚拟机的区别?P8
虚拟机将宿主机的资源硬隔离,每个虚拟机都有一个独立的操作系统,这些操作系统的生成需要消耗宿主机额外的资源,一个服务一个虚拟机的方式浪费太多资源,所以只能多个服务公用一个虚拟机,就行权益平台1.0一样,当一个服务重启就会影响其他服务
多个容器可以共享宿主机的操作系统,容器消耗的资源只是容器内程序运行依赖的资源,没有操作系统资源的浪费,可以一个服务一个容器
使用K8S部署流程?P19
构建镜像-》提交镜像-》提交应用描述到K8S API-》API分配节点-》节点kubelets负责拉取镜像运行docker容器
k8s好处?P20
在集群中自动分配资源节点-也可指定节点启动相应服务、节点及容器健康监控-自动转移pod、自动扩缩容、发版时检测版本是否异常-自动停止滚动更新
--------------------------pod---------------------------------
pod中的服务容器是紧密相关的组件,pod是扩缩容的基本单位
pod描述文件yaml P59,创建pod:kubectl create -f createPod.yml


apiVersion: v1 kind: Pod metadata: name: kubia-manual spec: containers: - image: yfzhou528/kubia name: kubia ports: - containerPort: 8080 protocol: TCP
--------------------------标签---------------------------------
功能:筛选满足标签条件的资源,如pod、节点等
为节点增加标签,在pod描述文件中使用nodeSelector指定pod运行在添加特定标签的节点上
为高GPU的node节点添加标签: kubectl lable node $nodeName gpu=true apiVersion: v1 kind: Pod metadata: name: kubia-manual spec: nodeSelector: // 标签选择器 gpu: "true" containers: - image: yfzhou528/kubia name: kubia ports: - containerPort: 8080 protocol: TCP
-----------------------命名空间------------------------------------
资源隔离,创建pod时可指定命名空间
----------------------存活探针-------------------------------------
k8s通过存活探针检测容器是否正常运行,如果不正常,通过RC或Deployment重新创建容器
HTTP GET 探针,通过向容器ip发送get请求检测响应是否正常,可设置首次探针探测时间、响应超时时间、探测多久探一次、失败阈值即失败几次后要重启容器
apiVersion: v1 kind: Pod metadata: name: kubia-manual spec: nodeSelector: // 标签选择器 gpu: "true" containers: - image: yfzhou528/kubia name: kubia livenessProbe: //探针 httpGet: //httpGet存活探针 path: / //get请求路径 port: 8080 //get请求端口 initialDelaySeconds: 15 //第一次探针检测在容器启动15s后,防止误探 ports: - containerPort: 8080 protocol: TCP
探测容器、重启容器这项工作由k8s节点上的kubelet负责,如果节点挂了,kubelet无法完成这项工作,所以引入副本控制器ReplicationController
------------------ReplicationController-----------------------------------------
作用:通过标签选择器确保标签匹配的pod始终正常运行,通过检查pod副本数来新建/删除pod。
注意RC作用的最小单元是pod而不是容器,而kubelet的工作是检测pod内的容器状态和重启容器
三要素:标签选择器、副本数、pod模板
如果RC标签选择器selector中有多个标签,组成集合A,则pod的标签labels中的标签项集合B必须是A的父级才会被RC管理
apiVersion: v1 kind: ReplicationController metadata: name: kubia-rc spec: replicas: 3 // 副本数 selector: // 标签选择器 app: kubia // rc只作用于携带此标签的pod template: // pod模板 metadata: label: app: kubia // pod携带的标签,必须与上面相同 spec: containers: - image: yfzhou528/kubia name: kubia livenessProbe: //探针 httpGet: //httpGet存活探针 path: / //get请求路径 port: 8080 //get请求端口 initialDelaySeconds: 15 //第一次探针检测在容器启动15s后,防止误探 ports: - containerPort: 8080 protocol: TCP
如果更改pod标签,rc会发现副本数不足而新建pod。如果更改rc标签,之前的pod全部失效,rc会再创建replicas个pod
更改rc文件(kubectl edit rc $rcname)的pod模板只会影响之后创建的pod,对现有pod无影响
扩缩容:更改rc文件的replicas实现,或者通过命令kubectl scale rc $rcname --replicas=5
删除rc会将其管理的pod也一并删除,可通过--cascade=false保留pod
--------------------ReplicaSet---------------------------------------
与ReplicationController的区别?P104 标签匹配功能更强:匹配多标签、匹配缺少某个标签、匹配标签key
apiVersion: apps/v1beta2 kind: ReplicaSet metadata: name: kubia-rs spec: replicas: 3 // 副本数 selector: // 标签选择器 matchLables: // *****matchLables选择器**** app: kubia // rc只作用于携带此标签的pod template: // pod模板 metadata: labels: app: kubia // pod携带的标签,必须与上面相同 spec: containers: - image: yfzhou528/kubia name: kubia livenessProbe: //探针 httpGet: //httpGet存活探针 path: / //get请求路径 port: 8080 //get请求端口 initialDelaySeconds: 15 //第一次探针检测在容器启动15s后,防止误探 ports: - containerPort: 8080 protocol: TCP
apiVersion: apps/v1beta2 kind: ReplicaSet metadata: name: kubia-rs spec: replicas: 3 // 副本数 selector: // 标签选择器 matchExpressions: // *****matchExpressions选择器**** - key: app // pod标签的key必须是app operator: In // pod标签的值必须在下面values集合中 values: // pod标签的值的集合 - kubia template: // pod模板 metadata: labels: app: kubia // pod携带的标签,必须与上面相同 spec: containers: - image: yfzhou528/kubia name: kubia livenessProbe: //探针 httpGet: //httpGet存活探针 path: / //get请求路径 port: 8080 //get请求端口 initialDelaySeconds: 15 //第一次探针检测在容器启动15s后,防止误探 ports: - containerPort: 8080 protocol: TCP
---------------------DaemonSet--------------------------------------
通过标签选择器匹配节点,并在节点上创建并管理一个pod,当节点挂了之后不会在其他节点创建pod,当新加入一个节点时会在它上面新建一个pod。场景:集群日志收集系统
apiVersion: apps/v1 kind: DaemonSet metadata: name: kubia-ds spec: selector: // 标签选择器 matchLabels: app: ssd-ds template: // pod模板 metadata: labels: app: ssd-ds // 在创建pod时自动为pod打上此标签 spec: nodeSelector: // 节点选择器 disk: ssd // 只会在有此标签的节点上才会创建pod containers: - image: yfzhou528/kubia name: kubia
-------------------------Job----------------------------------
适用临时任务:运行完任务就终止
若pod内部进程成功结束,不重启容器;若pod异常退出会新建一个pod,直到完成任务
缺陷:资源创建后会立即运行任务,不能控制触发时间
apiVersion: batch/v1 kind: Job metadata: name: kubia-job spec: completions: 5 // *******顺序创建运行5个pod,用于任务需顺序执行5次的场景****** parallelism: 2 // *******并行度,最多同时运行2个pod****** backoffLlimit: 6 // *******job被标记为失败之前可重试的次数,默认6**** selector: // 标签选择器,管理此标签的pod matchLabels: app: batch-job template: // pod模板 metadata: labels: app: batch-job // 在创建pod时自动为pod打上此标签 spec: restartPolicy: OnFailure // *******pod重启策略****** activiDeadlineSeconds: 100 // ****pod运行超过100s则任务失败**** containers: - image: yfzhou528/kubia name: kubia
CronJob
优势:在指定的时间运行job,注意同时启动多个job时要保证幂等
apiVersion: batch/v1 kind: CronJob metadata: name: kubia-cron-job spec: schedule: "0,30 * * * *" // ********任务在每小时的0分、30分触发一次******** jobTemplate: // job模板 spec: template: // pod模板 metadata: labels: app: batch-job // 在创建pod时自动为pod打上此标签 spec: restartPolicy: OnFailure // pod重启策略 activiDeadlineSeconds: 100 // pod运行超过100s则任务失败 containers: - image: yfzhou528/kubia name: kubia
---------------------Service--EndPoint------------------------------------
功能:为辖内的pod提供外部访问入口,转发、负载均衡。
服务在整个生命周期内ip不变,辖内的pod不管怎么变动都无所谓,其他pod都可以通过访问service来间接访问pod
先创建service,再创建客户端pod,则客户端pod会自动在环境变量中添加service的ip及端口,通过这个就可以访问service
apiVersion: v1 kind: Service metadata: name: kubia-service spec: selector: // 为此标签的pod提供对外服务及请求重定向 app: kubia ports: // service对外暴露的端口集合 - name: http port: 80 // service对外暴露的端口 targetPort: 8080 // service内的pod对应的接收转发端口 - name: https port: 443 targetPort: 8443
service并不是直接和辖内的pod连接的,而是通过EndPoint资源,当service中指定selector选择器时会自动创建对应的EndPoint资源,如果不指定则需手动创建
service中的selector选择器将符合的pod的ip及port列表存储在EndPoint资源中,当service收到请求后会从EndPoint资源存储的列表中选择一个
apiVersion: v1 kind: Service metadata: name: kubia-service-no-selector spec: #selector: // 不提供选择器 #app: kubia ports: // service对外暴露的端口集合 - name: http port: 80 // service对外暴露的端口 targetPort: 8080 // service内的pod对应的接收转发端口 - name: https port: 443 targetPort: 8443 ------------ apiVersion: v1 kind: EndPoints metadata: name: kubia-service-no-selector// 必须与Service名字相同 subsets: // 手动提供pod的ip及端口 - addresses: - ip: 11.11.11.11 - ip: 22.22.22.22 ports: - port: 80
向集群外部的客户端暴露服务的几种方式
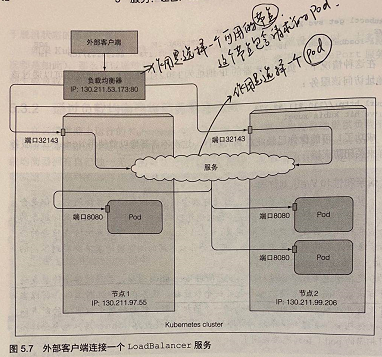
1.通过节点负载均衡器暴露service:
apiVersion: v1 kind: Service metadata: name: kubia-loadbalancer spec: type: LoadBalancer // *******该服务从k8s基础架构获取针对节点的负载平衡器******* selector: // 为此标签的pod提供对外服务及请求重定向 app: kubia ports: // service对外暴露的端口集合 - name: http port: 80 // service对外暴露的端口 targetPort: 8080 // service内的pod对应的接收转发端口 - name: https port: 443 targetPort: 8443
-------------------------Ingress----------------------------------
2.通过Ingress暴露服务
通过LoadBalancer暴露服务的缺点:服务过多时,每个服务都需要独有的负载均衡器及公网ip
Ingress类似nginx,只需一个公网ip提供入口,然后根据请求域名找到对应的转发规则,将请求转发给对应的服务 P144
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: kubia-ingress spec: rules: - host: kubia.example.com // 对外域名,访问时映射到此服务 http: paths: - path: /aa // 将kubia.example.com/aa请求发送到kubia-nodeport服务的80端口(nginx转发功能) backend: serviceName: kubia-nodeport // kubia-nodeport是一个NodePort类型的服务 servicePort:80 - host: kubia.example.com2 http: paths: - path: /bb // 将kubia.example.com2/bb请求发送到kubia-nodeport2服务的80端口(nginx转发功能) backend: serviceName: kubia-nodeport2 servicePort:80
----------------------就绪探针-------------------------------------
service和其后端pod组成服务集群,当pod启动时,就绪探针会检查是否就绪,如果没就绪就不将pod添加到后端集群中,即不添加到Endpoint维护的ip:port列表,当探查到它就绪时再添加进去
就绪探针只会根据探查结果操作endpoint列表,不设计pod的删除、新建、重启。而存活探针会在容器不存活时重启容器,它针对的是容器不是pod。
apiVersion: v1 kind: ReplicationController metadata: name: kubia-rc spec: replicas: 3 // 副本数 selector: // 标签选择器 app: kubia // rc只作用于携带此标签的pod template: // pod模板 metadata: label: app: kubia // pod携带的标签,必须与上面相同 spec: containers: - image: yfzhou528/kubia name: kubia readinessProbe: //*******就绪探针,默认10s检查一次******* exec: command: - ls - /var/ready livenessProbe: //存活探针 httpGet: //httpGet存活探针 path: / //get请求路径 port: 8080 //get请求端口 initialDelaySeconds: 15 //第一次探针检测在容器启动15s后,防止误探 ports: - containerPort: 8080 protocol: TCP
----------------------持久卷PV、持久卷声明PVC-------------------------------------
PV是集群层面的资源,不属于任何一个命名空间;PVC是命名空间层面的资源
集群管理员创建PV资源,开发通过创建PVC资源,然后在pod的容器中挂载卷,并在pod资源的volumes属性的卷中指定PVC,来获取匹配的PV
一个PVC创建之后会自动与现有的PV匹配,匹配成功后PVC就和PV绑定了,这是在PVC创建时就完成的。一个PV只能同时被一个PVC绑定
#####创建持久卷PV##### apiVersion: v1 kind: PersistentVolume metadata: name: kubia-pv spec: capacity: |->PV容量 storage: 1Gi | accessModes: |->PV支持的访问模式 - ReadWriteOnce |ReadWriteOnce:允许单客户端读写 - ReadOnlyMany |ReadOnlyMany:允许多客户端读 |ReadWriteMany:允许多客户端读写 |->PV被PVC释放后,处理PV的策略 persistentVolumeReclaimPolicy: Retain |Retain:保留不作处理 |Recycle:删除卷的存储内容,可被其他PVC再次绑定循环使用 |Delete:删除卷的存储内容,不可被其他PVC再次绑定 nfs: path: "/data/k8s/volumes" | server: 192.168.1.101 |->持久卷存储在哪,这里指定nfs服务器地址及存储目录 readOnly: false | #####创建持久卷声明PVC##### apiVersion: v1 kind: PersistentVolumeClaim metadata: name: kubia-pvc <--------------------------------------------------- spec: | resources: | | requests: |->声明需要的系统资源 | storage: 1Gi | | | accessModes: |->声明持久卷的访问模式 | - ReadWriteOnce | | | storageClassName: "" |确保PVC绑定到预先配置的PV,而不是自动生成的PV上| | | #####创建Pod指定PVC##### | apiVersion: v1 | kind: Pod | metadata: | name: kubia-pod | spec: | containers: | - image: yfzhou528/kubia | name: kubia | ports: | - containerPort: 27017 | protocal: TCP | volumeMounts: | - name: kubia-data |指定容器使用的卷名 <------------- | mountPath: /data/db | | volumes: |自定义容器使用的卷名及卷对应的PVC | | - name: kubia-data ---------------------------------------- | persistentVolumeClaim: | | claimName: kubia-pvc |--------------------------------------------
----------------------ConfigMap-------------------------------------
创建configmap一般使用命令行模式而不是yaml模式
apiVersion: v1 kind: Pod metadata: name: kubia-configmap spec: containers: - image: yfzhou528/kubia name: kubia env: #指定环境变量 - name: INTERVAL #环境变量名<---------------------------- valueFrom: | | configMapKeyRef: |->环境变量源自ConfigMap | name: my-configmap #源自哪个ConfigMap,指定它的名字 | key: sleep-interval #将ConfigMap中哪个key的值赋给INTERVAL---
若Pod中某个container引用的ConfigMap不存在,则这个容器启动失败,pod中的其他容器无影响,当这个不存在的ConfigMap创建后,失败容器会自动重启
configMap卷:pod中的某个容器挂在一个卷,在这个卷中将configMap中的条目放进去,这样容器需要的卷内容就与卷声明解耦,依赖的条目内容改变后无需更改卷声明
配置热更新:kubectl edit修改ConfigMap的内容后,引用ConfigMap卷的容器和pod无需重启即可实现配置热更新,但是会有一定的延迟
apiVersion: v1 kind: Pod metadata: name: kubia-configmap spec: containers: - image: yfzhou528/kubia name: kubia volumeMounts: - name: config mountPath: /etc/zhou #将ConfigMap的条目挂载到容器的哪个目录 volumes: - name: config configMap: #configMap类型的卷 name: myConfigMap #哪个ConfigMap
Secret资源:类似ConfigMap,支持HTTPS
----------------------DownwardAPI卷-------------------------------------
apiVersion: v1 kind: Pod metadata: name: kubia-downward labels: foo: bar annotations: key1: value1 spec: containers: - image: yfzhou528/kubia name: kubia volumeMounts: - name: downVolume mountPath: /etc/zhou volumes: - name: downVolume downwardAPI: items: - path: "podName" fieldRef: fieldPath: metadata.name # kubia-downward - path: "labels" fieldRef: fieldPath: metadata.labels # foo: bar - path: "annotations" fieldRef: fieldPath: metadata.annotations # key1: value1
自动更新:可以在pod运行时修改标签和注解,容器挂载的DownwardAPI卷中相关的pod元数据项将自动更新
DownwardAPI卷局限性:只能将本pod及容器的元数据传递给进程,对本pod之外的数据无能为力
容器可通过与K8S API服务器交互获取其他pod的元数据,但是需要认证和授权才行
在pod内专门创建一个代理容器负责与K8S API服务器交互,pod内的其他容器只需与代理容器交互即可,免去每个容器都有认证授权
----------------------***Deployment***----------------------------------
用于版本发布-滚动升级
通过Deployment资源触发滚动升级时,会自动创建一个新的ReplicaSet,新旧两个RS通过label来区分管理新旧版本的pod: P263
1.新RS创建后,在RS的selector中除了pod的标签,新增了一个deploment标签,它的值是当前版本pod模板的hash值,用于区分RS版本。由于旧pod中没有新增的deployment标签,所以旧pod不归新RS管理
2.旧pod也都会增加一个另外的deploment标签,这时旧RS仍然能管理旧pod
3.旧RS再增加这个相同的deploment标签,这时旧RS仍然能管理旧pod
Deployment滚动升级完成后,不会删除旧RS,此旧RS用于版本回滚
maxSurge+maxUnavailable控制滚动升级速率、minReadySeconds+就绪探针 阻止异常pod滚动升级:
apiVersion: apps/v1beta1 kind: Deployment metadata: name: kubia-deployment spec: replicas: 3 #升级后期望运行多少个pod minReadySeconds: 10 #新创建的pod成功运行多久后才视为可用 strategy: #升级策略: type: RollingUpdate #RollingUpdate(默认):渐进删除旧pod,同时创建新pod #Recreate:在删除全部旧pod后,再创建新pod rollingUpdate: #控制滚动升级速率: maxSurge: 1 #在滚动升级期间,允许超出期望副本replicas的pod数。 #即允许最多同时存在pod数=replicas+maxSurge maxUnavailable: 0 #在滚动升级期间,相对于期望副本数,允许存在不可用状态pod的数量。 #即同时正常运行的最少pod数=replicas-maxUnavailable template: #定义pod模板 metadata: name: kubia labels: app: kubia spec: containers: - image: yfzhou528/kubia:v2 #版本tag v2非常重要,代表本次要更新的版本号 name: kubia readinessProbe: #就绪探针,配合minReadySeconds可阻止异常版本继续滚动升级 periodSeconds: 1 #探测频率 httpGet: path: / port: 8080
如何阻止异常pod滚动升级(maxUnavailable + minReadySeconds + 就绪探针)?
就绪探针在未超过minReadySeconds的时间内,探测到pod未就绪,而如果maxUnavailable设置为0,即表示不允许有不存活的pod存在,这就不能满足继续滚动升级的条件,导致滚动停止,若10分钟内没完成滚动升级则视为升级失败
---StatefulSet--------------------------------------------------------
可以用于解决RS的什么问题:RS的声明文件中,如果一个pod的某个容器挂载了一个卷,这个卷会制定一个PVC,这个PVC会绑定一个PV。如果RS的期望副本数>1,则多个pod中的这个容器都是用同一个PV,数据都往一处写,无法做到分开写。
StatefulSet不像RS那样指定PVC,而是通过指定一个PVC模板,同时先创建好多个PV,等SS创建pod时会通过PVC模板创建属于此pod的PVC实例,此PVC再绑定到创建好的PV中的一个,这样就做到了不同pod中的容器挂载不同的PV就行数据存储;
同时如果SS创建的pod挂了,SS进行恢复创建pod时,会和挂掉的pod保持相同的pod名、ip地址、pv,新pod仍可以使用挂掉的pod之前存储在pv中的数据
SS修改资源文件的副本数进行缩容时,会先删最高索引值的pod,删pod不会删它的PVC实例(如果需要释放PVC绑定的PV,需要手动删除PVC,这时数据就没了),这时如果再进行扩容,会使用没删的PVC实例及它绑定的PV中的数据,这中机制是为了保证误删pod时可以恢复数据。
SS资源创建步骤:
apiVersion: v1 kind: PersistentVolume metadata: name: kubia-pv-a spec: capacity: storage: 1Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain nfs: path: "/data/k8s/volumes/kubia-pv-a" server: 192.168.1.101 readOnly: false --- apiVersion: v1 kind: PersistentVolume metadata: name: kubia-pv-b spec: capacity: storage: 1Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain nfs: path: "/data/k8s/volumes/kubia-pv-b" server: 192.168.1.101 readOnly: false --- apiVersion: v1 kind: PersistentVolume metadata: name: kubia-pv-c spec: capacity: storage: 1Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain nfs: path: "/data/k8s/volumes/kubia-pv-c" server: 192.168.1.101 readOnly: false
apiVersion: v1 kind: Service metadata: name: kubia-service spec: clusterIP: None #headless模式让客户端pod直接访问此service辖内的pod,而不是通过service来访问 selector: app: kubia ports: - name: http port:80
apiVersion: apps/v1beta1 kind: StatefulSet metadata: name: kubia-ss spec: serviceName: kubia-service #与上面创建的service对应 replicas: 2 template: metadata: labels: app: kubia spec: containers: - image: yfzhou528/kubia name: kubia ports: - name: http containerPort: 8080 volumeMounts: - name: kubia-data mountPath: /data/db volumeClaimTemplates: | - metadata: | name: kubia-data | spec: | resources: |->创建久卷声明模板 requests: | storage: 1Gi | accessModes: | - ReadWriteOnce |
-----------------------------------------------------------