GIL
1 GIL:全局解释器锁
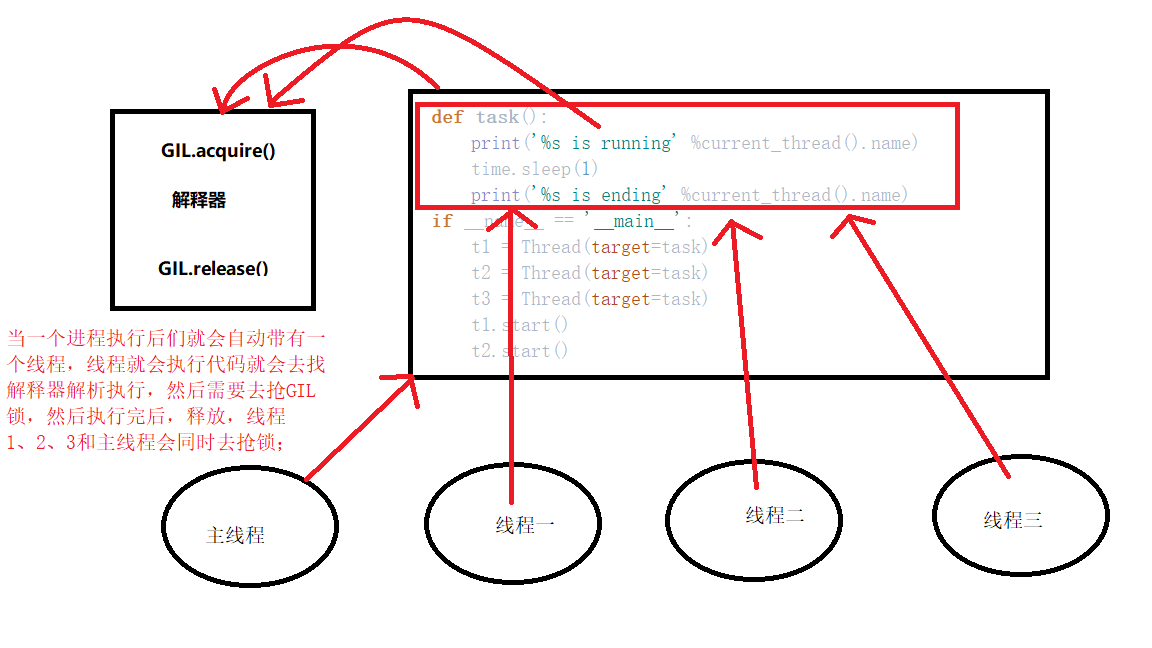
GIL本质就是一把互斥锁,是夹在解释器身上的,
同一个进程内的所有线程都需要先抢到GIL锁,才能执行解释器代码
2、GIL的优缺点:
优点:
保证Cpython解释器内存管理的线程安全
缺点:
同一进程内所有的线程同一时刻只能有一个执行,
也就说Cpython解释器的多线程无法实现并行
Cpython解释器并发效率验证:
from multiprocessing import Process import time def task1(): res=0 for res in range(1,100000000): res+=1 def task2(): res=0 for res in range(1,100000000): res+=1 def task3(): res=0 for res in range(1,100000000): res+=1 def task4(): res=0 for res in range(1,100000000): res+=1 if __name__ == '__main__': p1=Process(target=task1) p2 = Process(target=task2) p3 = Process(target=task3) p4 = Process(target=task4) start_time=time.time() p1.start() p2.start() p3.start() p4.start() p1.join() p2.join() p3.join() p4.join() print(time.time()-start_time)#5.1822803020477295 from threading import Thread import time def task1(): res=0 for res in range(1,100000000): res+=1 def task2(): res=0 for res in range(1,100000000): res+=1 def task3(): res=0 for res in range(1,100000000): res+=1 def task4(): res=0 for res in range(1,100000000): res+=1 if __name__ == '__main__': t1=Thread(target=task1) t2 = Thread(target=task2) t3 = Thread(target=task3) t4 = Thread(target=task4) start_time=time.time() t1.start() t2.start() t3.start() t4.start() t1.join() t2.join() t3.join() t4.join() print(time.time()-start_time)#20.5066978931427
纯计算的情况下,Cpython解释器的线程,不如四核一起运行的进程快,因为给它的四个任务都是纯计算的,所以四个任务都是全部占用cpu 所以基本上是进程的四倍
from multiprocessing import Process import time def task1(): time.sleep(3) def task2(): time.sleep(3) def task3(): time.sleep(3) def task4(): time.sleep(3) if __name__ == '__main__': p1=Process(target=task1) p2 = Process(target=task2) p3 = Process(target=task3) p4 = Process(target=task4) start_time=time.time() p1.start() p2.start() p3.start() p4.start() p1.join() p2.join() p3.join() p4.join() print(time.time()-start_time)#3.1452929973602295 from threading import Thread import time def task1(): time.sleep(3) def task2(): time.sleep(3) def task3(): time.sleep(3) def task4(): time.sleep(3) if __name__ == '__main__': t1=Thread(target=task1) t2 = Thread(target=task2) t3 = Thread(target=task3) t4 = Thread(target=task4) start_time=time.time() t1.start() t2.start() t3.start() t4.start() t1.join() t2.join() t3.join() t4.join() print(time.time()-start_time)#3.0024893283843994
纯lo的情况下,因为进程创建内存空间,复制父进程,需要消耗大量资源,所以远不如,线程的速度快(线程的速度是进程的100多倍)
GIL与互斥锁对比;
from threading import Thread,Lock import time mutex=Lock() count=0 def task(): global count temp=count time.sleep(0.1) count=temp+1 if __name__ == '__main__': t_l=[] for i in range(2): t=Thread(target=task) t_l.append(t) t.start() for t in t_l: t.join() print('主',count)#主 1 from threading import Thread,Lock import time mutex=Lock() count=0 def task(): global count mutex.acquire() temp=count time.sleep(0.1) count=temp+1 mutex.release() if __name__ == '__main__': t_l=[] for i in range(2): t=Thread(target=task) t_l.append(t) t.start() for t in t_l: t.join() print('主',count)#主 2
GIL全局解释器锁只是作用在 解释器上清理垃圾的机制,要去清理数据时,拿到这把锁,其他人都没法来干扰它
而互斥锁,是我们自定义的锁,它才是作用于我们写的代码上,保护数据安全,
运行过程,先去抢GIL锁,抢到GIL,拿到cpu执行体内代码,又抢到互斥锁,拿到个初始数0,然后遇到IO了释放掉了GIL,cpu也被别的线程抢走了,
但是互斥锁在我手里,所以他们做的争抢都是无意义的,直到我IO操作结束后,重新拿到GIL,然后执行完我所有的代码,改初始值为1,并将互斥锁释放。
进程池vs线程池
为什么要用“池”:
池子使用来限制并发的任务数目,限制我们的计算机在一个自己可承受的范围内去并发地执行任务
池子内什么时候装进程:并发的任务属于计算密集型
池子内什么时候装线程:并发的任务属于IO密集型
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor import time,os,random def task(x): print('%s 接客' %os.getpid()) time.sleep(random.randint(2,5)) return x**2 if __name__ == '__main__': p=ProcessPoolExecutor() # 默认开启的进程数是cpu的核数 for i in range(20): p.submit(task,i) from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor import time,os,random def task(x): print('%s 接客' %x) time.sleep(random.randint(2,5)) return x**2 if __name__ == '__main__': p=ThreadPoolExecutor(4) # 默认开启的线程数是cpu的核数*5 for i in range(20): p.submit(task,i)
阻塞,非阻塞,同步,异步
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
import time,os,random
def task(x):
print('%s 接客' %x)
time.sleep(random.randint(1,3))
return x**2
if __name__ == '__main__':
# 异步调用
p=ThreadPoolExecutor(4) # 默认开启的线程数是cpu的核数*5
# alex,武佩奇,杨里,吴晨芋,张三
obj_l=[]
for i in range(10):
obj=p.submit(task,i)
obj_l.append(obj)
# p.close()
# p.join()
p.shutdown(wait=True)
print(obj_l[3].result())
print('主')
1、阻塞与非阻塞指的是程序的两种运行状态
阻塞:遇到IO就发生阻塞,程序一旦遇到阻塞操作就会停在原地,并且立刻释放CPU资源
非阻塞(就绪态或运行态):没有遇到IO操作,或者通过某种手段让程序即便是遇到IO操作也不会停在原地,执行其他操作,力求尽可能多的占有CPU
2、同步与异步指的是提交任务的两种方式:
同步调用:提交完任务后,就在原地等待,直到任务运行完毕后,拿到任务的返回值,才继续执行下一行代码
异步调用:提交完任务后,不在原地等待,直接执行下一行代码,结果?