避免过拟合的方法:
early stopping:在发生过拟合之前提前结束训练。理论上可行,但难以把握。
数据集扩增:
正则化:通过引入范数的概念,增强模型的泛化能力,包括L1,L2(L2 regularization也叫weight decay)
dropout:是网络模型中的一种方法,每次训练时舍去一些节点来增强泛化能力。
正则化
- 何为正则化:所谓正则化,其实是在神经网络计算损失值的过程中,在损失后面再加一项。
- 干扰项的特性:当欠拟合时,希望它对模型误差的影响越大越好,以便让模型快速拟合实际。
当过拟合时,希望它对模型误差的影响越大越好,以便让模型不要产生过拟合的情况。
- 解决:引入两个范数L1和L2
- L1:所有学习参数W的绝对值的和
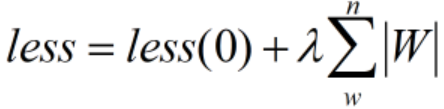
-
- L2:所有学习参数W的平方和然后求平方根
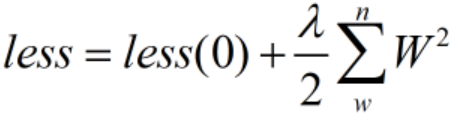
- λ为一个可调节的参数,用来控制正则化对Loss的影响。L2将其乘1/2是为了反向传播时对其求导正好将数据规整。
- TensorFlow中的正则化:L2正则化函数 tf.nn.l2_loss(t, name=None); L1正则化函数,自己组合实现tf.reduce_sum(tf.abs(w))
dropout——训练过程中,将部分神经单元暂时丢弃
- 原理:在训练过程中,每次随机选择一部分节点不要去“学习”
- 异常数据的特点:与主流样本的规律不同,但是量非常少,相当于在一个样本中出现的概率比主流数据出现的概率低很多。
- tip:dropout让一部分节点不去“学习”,在增加模型泛化能力的同时,学习速度降低,使模型不太容易“学成”,所以在使用的过程中需要合理地调节到底丢弃多少节点,并不是丢弃的节点越多越好。
- TensorFlow中的dropout:def dropout(x, keep_prob, noise_shape=None, seed=None, name=
- x:输入的模型节点
- keep_prob:保持率。如果为1,则代表全部进行学习;如果为0.8,则代表丢弃20%的节点,只让80%的节点参与学习
- noise_shape:代表指定x中,哪些维度可以使用dropout技术。为None时,表示所有维度都使用dropout;也可将某个维度标志为1,来代表该维度使用dropout技术。
- seed:随机选取节点的过程中随机数的种子值
- tip:dropout改变了神经网络的网络结构,它仅仅是属于训练时的方法,所以一般在进行测试时要将dropout的keep_prob变为1,代表不需要丢弃,否则影响模型的正常输出。