本文hadoop的安装版本为hadoop-2.6.5
关闭防火墙
systemctl stop firewalld
一、安装JDK
1、下载java jdk1.8版本,放在/mnt/sata1目录下,
2、解压:tar -zxvf dk-8u111-linux-x64.tar.gz
3、vim /etc/profile
#在文件最后添加 export JAVA_HOME=/mnt/sata1/jdk1.8.0_111 export PATH=$PATH:$JAVA_HOME/bin
4、刷新配置
source /etc/profile
5、检测是否成功安装:java -version
二、安装Hadoop(单机版)
1、下载hadoop-2.6.5.tar.gz放在/mnt/sata1目录下
2、解压:tar -zxvf hadoop-2.6.5.tar.gz
三、修改配置文件
1、修改hadoop-env.sh,配置java jdk路径
echo $JAVA_HOME /mnt/sata1/jdk1.8.0_111 #将默认的export JAVA_HOME=${JAVA_HOME}修改为: export JAVA_HOME=/mnt/sata1/jdk1.8.0_111
2、修改core-site.xml,配置内容如下
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<!-- yang为主机名 -->
<name>fs.defaultFS</name>
<value>hdfs://yang:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/mnt/sata1/hadoop_data</value>
</property>
</configuration>
3、修改hdfs-site.xml,修改配置如下
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
4、将hadoop添加到环境变量,然后更新一下环境变量:source /etc/profile
export HADOOP_HOME=/mnt/sata1/hadoop-2.6.5 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
5、刷新配置
source /etc/profile
6、配置免密(这里以单节点自己对自己免密)
1、创建dsa免密代码:ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
2、将生成的公钥发送给需要做免密的主机:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
7、进入/mnt/sata1/hadoop-2.6.5/bin进行格式化
./hdfs nameode -format
8、启动服务
start-dfs.sh
注:
如果没有配置环境变量,到目录/mnt/sata1/hadoop-2.6.5/bin启动(./
start-dfs.sh
)
9、

三、yarn(单机版)
1、修改mapred-site.xml 由于在配置文件目录(/mnt/sata1/hadoop-2.6.5/etc/hadoop)下没有,需要修改名称:mv mapred-site.xml.template mapred-site.xml
<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2、修改yarn-site.xml,修改内容如下
<configuration>
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
</configuration>
localhost:主机名
3、启动yarn
cd /mnt/sata1/hadoop-2.6.5/
./start-yarn.sh
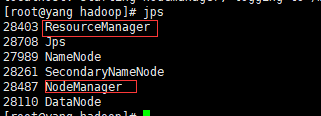
四、Hadoop(集群版)yarn集群版
1、修改hadoop-env.sh,配置java jdk路径
echo $JAVA_HOME
/mnt/sata1/jdk1.8.0_111
#将默认的export JAVA_HOME=${JAVA_HOME}修改为:
export JAVA_HOME=/mnt/sata1/jdk1.8.0_111
2、修改core-site.xml,配置内容如下
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<!-- yang为主机名 -->
<name>fs.defaultFS</name>
<value>hdfs://yang:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/mnt/sata1/hadoop_data</value>
</property>
</configuration>
3、修改hdfs-site.xml,修改配置如下
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave01:50090</value>
</property>
4、SecondaryNameNode与namenode的分开配置,新建一个masters文件,内容为secondnamenode所在节点
/mnt/hadoop/etc/hadoop
[root@master hadoop]# cat masters
slave01
同时在hdfs-site.xml文件加入:
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave01:50090</value>
</property>
4、配置yarn
1.修改hadoop配置目录: 复制文件: cp mapred-site.xml.templta mapred-site.xml mapred-site.xm加入以下配置: <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> 2.yarn-site.xml加入以下配置: <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property>
5、将hadoop的目录文件分发到其他主机
scp -r hadoop root@slave01:/mnt
scp -r hadoop root@slave02:/mnt
6、配置环境变量
export HADOOP_HOME=/mnt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
7、进入/mnt/hadoop/bin进行格式化(在master所在节点执行)
./hdfs namenode -format
6、启动服务hdfs、yarn
start-dfs.sh start-yarn.sh
注:
如果没有配置环境变量,到目录/mnt/hadoop/bin启动(./
start-dfs.sh
)