1、简介
1.1 ASR的工作流程
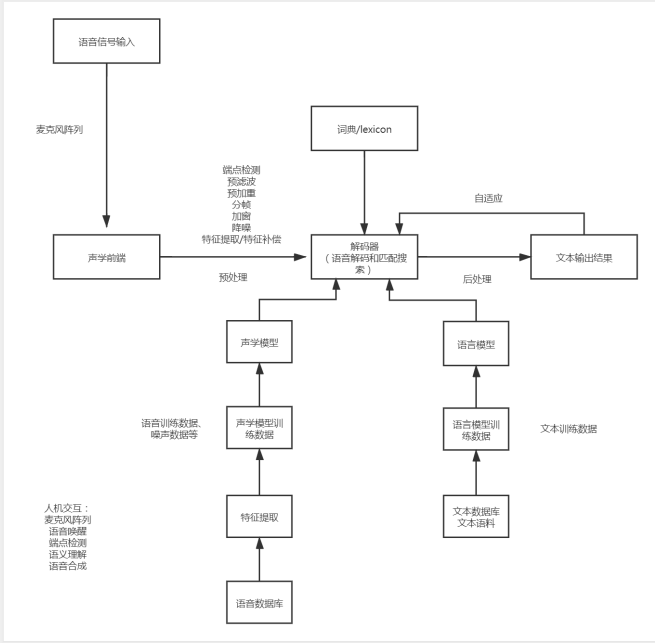
1.2 语音识别数据处理技术
1.2.1 信号预处理
信号预处理包括:采样与滤波、预加重、端点检测、分帧、加窗、降噪
采样与滤波:将模拟信号离散化成数字信号
预加重:加重语音的高频部分,去除口唇辐射的影响,增加语音的高频分辨率
端点检测:从音频流里识别和消除长时间的静音段,减少环境对信号的干扰
分帧:
1.2.2 特征提取与特征补偿
(1)特征提取
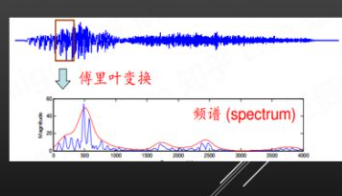
常用特征:MFCC、Fbank、pitch
时频转换
共振峰/包络-MFCC:语音信号中能量集中的区域;反映音色
基音周期/精细结构-pitch:声带振动频率(基频)的振动周期;反映音高
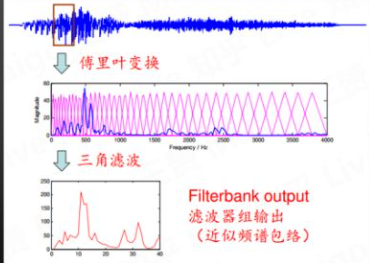
FBank特征 :
三角滤波:模仿人耳特性;(低频分辨率高,高频分辨率低);一般取40个
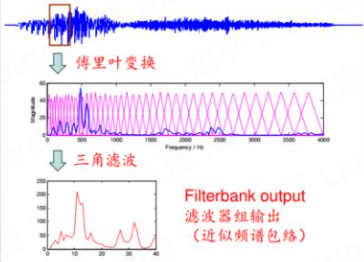
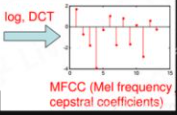
特征压缩
离散余弦变换:13维的特征向量
MFCC特征:一阶、二阶差分;CMVN归一化
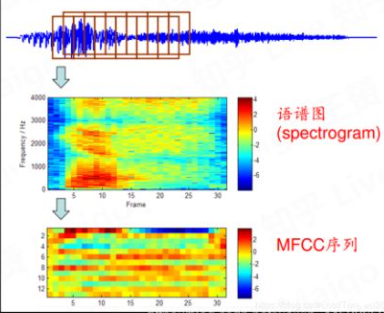
一段语音信号
滑动窗口
语谱图
1.2.3 解码
声学模型(AM)
给定音素、词语,它的发音会是什么样
语言模型(LM)
验证该文本是否是自然流畅的文本
词典(Lexicon)
规定字词的发音规则
解码器(Decoder)
通过训练好的模型对给定语音进行解码
常用的解码器:维特比算法(Veterbi)
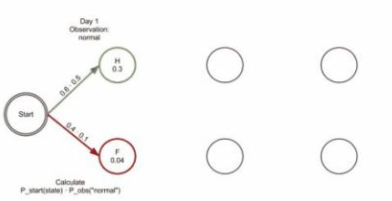
维特比算法:
(1)寻找最优路径
(2)动态规划算法(每一步都选择到达该状态的所有路径中的概率最大值)
词图(lattice)
(1)得分最靠前的前N条候选路径
(2)用更好的语言模型对这些句子重新打分,选出最优解
1.3 语音识别技术的应用
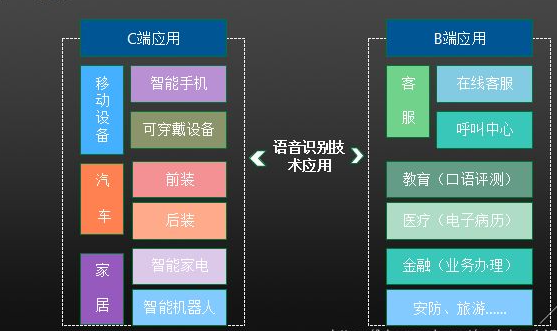
语音识别作为一种基础层感知类技术,既可以作为核心技术直接应用于终端产品,也可以仅作为一种感知类辅助技术集成于语音助手、车载系统、智慧医疗、智慧法院等场景的产品中。
2、Kaldi工具
2.1 Kaldi的简介
Kaldi是当前最流行的开源语音识别工具(Toolkit),它使用WFST来实现解码算法。Kaldi的主要代码是C++编写,在此之上使用bash和python脚本做了一些工具。
语音识别,大体可分为“传统”识别方式与“端到端”识别方式,其主要差异就体现在声学模型上。
“传统”方式的声学模型一般采用隐马尔可夫模型(HMM),而“端到端”方式一般采用深度神经网络(DNN)
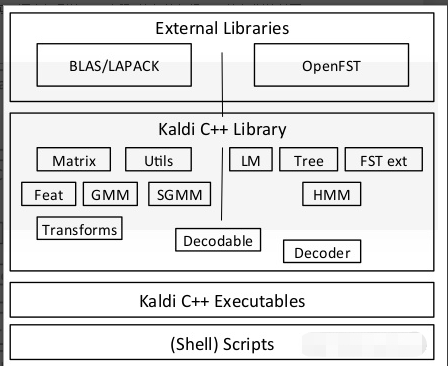
Kaldi架构如所示,最上面是外部的工具,包括用于线性代数库BLAS/LAPACK和我们前面介绍过的OpenFst。中间是Kaldi的库,包括HMM和GMM等代码,下面是编译出来的可执行程序,最下面则是一下脚本,用于实现语音识别的不同步骤(比如特征提取,比如训练单因子模型等等)。
对应大部分Kaldi的用户来说,我们只需要使用脚本和配置文件就可以完成语音识别系统的训练和预测了。
源码:https://github.com/kaldi-asr/kaldi
kaldi - main Kaldi directory which contains:
egs – example scripts allowing you to quickly build ASR systems for over 30 popular speech corpora (documentation is attached for each project)
以使用的数据库的名字命名。在下一级目录中以s开头的文件是语音识别,以v开头的是声纹识别,一般v1就是使用i-vector的方法来进行声纹识别
misc – additional tools and supplies, not needed for proper Kaldi functionality,
src – Kaldi source code,
tools – useful components and external tools,
windows – tools for running Kaldi using Windows.
The most important directory for you is obviously egs. Here you will create your own ASR system
kaldi主要用脚本来驱动,每个recipe下会有很多脚本。local目录下的脚本通常是与这个example相关,不能移植到别的例子,通常是数据处理等“一次性”的脚本。而util下的脚本是通用的一些工具。steps是训练的步骤,最重要的脚本。
3、ASR 模型测试过程
3.1 准备测试集
测试集:测试数据集,由录音和录音对应的正确文本组成。为了知道模型在生产上的实际应用效果,从生产中抽取具有代表性的样本数据,作为考试题,事先标注正确答案,用模型转写后的结果与正确答案做对比。
举个例子:需知道小明的数学成绩,需先要抽取部分考点作为试卷,并事先准备参考答案,用小明计算出来的结果与参考答案对比,可知道小明在数学方面的得分。
测试集一般不会变化,因为要比较把模型训练前后的效果,需要控制变量。可见,正确答案的标注直接决定了小明的得分,因此需要遵循严格,固定的规范。
训练集:为了提升模型能力,需要将标注的文本和录音给到模型进行训练,这批答案文本和录音就是训练数据集,简称训练集。还是小明为例,需要提前将大量五三考卷的正确答案告知小明,小明进行学习找规律,从而提升下一次考测试集的能力。训练集的数据量比较大,才会有提升效果。
(1)音频格式的转换
(2)标注文件编码的转换
(3)混合数据集的拆分
双声道分离左右声道
立体声转换单声道
标注文件分离
3.2 测试集标注badcase
质量评估标准
3.2.1 常见错误与解决方案
|
常见错误 |
发生原因 |
解决方案 |
落实措施 |
|
发音不清 |
用户问题 |
依赖用户 |
用户 |
|
语速过快 |
用户问题 |
根据返回的语速检测值,提醒用户说话慢一点 |
流程控制 |
|
录音截断(头部截断/尾部截断) |
静音检测 |
|
1.算法优化 2.合作:业务收集数据,算法辅助 |
|
重口音 |
声学模型 |
收集不同类别重口音数据,进行标注和训练 |
合作:业务收集数据,算法训练 |
|
方言 |
声学模型 |
收集不同类别方言数据,进行标注和训练 |
合作:业务收集数据,算法训练 |
|
噪音 |
声学模型 |
1.根据返回的背景人声占比值和信噪比,提醒用户到安静的地方说话 2.收集噪音和静音数据,进行ASR抗噪训练 3.提升硬件设备的抗噪能力 |
1.流程控制 2.合作:业务收集数据,算法训练 3.硬件提供方 |
|
远场(回声/混响) |
声学模型 |
1.收集远场语音数据,进行ASR远场模型训练 2.提升硬件设备收声能力,减少回声混响等远场效果 |
1.合作:业务收集数据,算法训练 2.硬件提供方 |
|
专有名词(地名人名术语)识别错误 |
声学词典 |
1.收集专有词汇,添加到声学词典或热词 |
合作:业务收集词汇,算法训练 |
|
转写错误 |
语言模型 |
1.收集历史录音,进行语言模型优化训练 |
合作:业务收集数据,算法训练 |
3.2.2 ASR系统问题分类
录音尾部截断
由于与上游系统交互问题,ASR引擎只收到前半部分录音,就被截断。与文本中偶尔漏一两个字不同,是整个尾部片段缺失
录音头部截断
由于与下游系统交互问题,ASR引擎只收到后半部分录音,录音前半部分就被截断。是整个头部片段缺失
录音被TTS播报打断
由于与上游系统交互,ASR检测用户开始讲话存在一定延迟,导致MRCP接收超时,误认为用户不再说话,开始TTS播报,ASR返回结果MRCP未接收。
3.2.3 录音质量问题分类
无人声 既没有噪音,也没有人声 <!--安静没有说话,也没有噪音--> 系统可能超时(3秒),用户没有说话,导致拒识 有噪音,没有人声 1、没有说话,有含背景人声(含可辨识的第二人声) 2、没有说话,有含节奏噪音(类似含叮叮咚咚/喇叭声/或是音乐等干扰噪音) 3、没有说话,有含风噪(含人呼气声或是强风的喷麦噪音) 4、没有说话,有含其他噪音(含其他噪音) 标注:【纯噪音】 听的清楚/听的不清楚 有人声 1,发音不标准 (1)语速较快(说话较快影响标注内容)【说话快】 (2)纯方言【夹杂方言】 (3)方普口音(方言口音较重,方普,含吐词不清,说话听不清楚) 2、发音标准 (1)没有噪音 -- 语音清晰(转译正确) (语音清晰并可以正确标注客户内容(NLP)可能错误) -- 语音清晰(转译错误) (指语音清晰,因谐音或发音影响,导致转译字数或转译文本内容不同,且影响NLP语义理解) (2)有噪音 -- 有说话,且含背景人声 (含可辨识的第二人声) -- 有说话,且含节奏噪音(含叮叮咚咚/喇叭声/或是音乐等干扰噪音) -- 有说话,且含风噪(含人呼气声或是强风的喷麦噪音) -- 有说话,且含其他噪音(含其他噪音) 【含噪音】 x 听的清楚/听的不清楚
3.2.4 录音质量问题分类汇总
|
有无人声 |
发音是否标准 |
有无噪音 |
录音质量分类 |
|
无 |
N/A |
无 |
安静没说话 |
|
无 |
N/A |
有 |
没说话,有含背景人声 |
|
无 |
N/A |
有 |
没说话,有含节奏噪音 |
|
无 |
N/A |
有 |
没说话,有含风噪 |
|
无 |
N/A |
有 |
没说话,有含其他噪音 |
|
有 |
不标准 |
|
语速快 |
|
有 |
不标准 |
|
纯方言 |
|
有 |
不标准 |
|
方普口音 |
|
有 |
标准 |
无 |
语音清晰(转译正确) |
|
有 |
标准 |
无 |
语音清晰(转译错误) |
|
有 |
标准 |
有 |
有说话,且含背景人声 |
|
有 |
标准 |
有 |
有说话,且含节奏噪音 |
|
有 |
标准 |
有 |
有说话,且含风噪 |
|
有 |
标准 |
有 |
有说话,且含其他噪音 |
4、语音识别(ASR)评估指标
词错误率(Word Error Rate,WER)、字错误率(Character Error Rate,CER)、音素错误率(Phone Error Rate,PER)、句错误率(Sentence Error Rate,SER)
替换错误(substitutions)、删除错误(Deletions)、插入错误(Insertions)
(1)词错误率(Word Error Rate,WER)
-将标准答案与识别结果对齐
- 用插入、删除、替换错误的总数除以 标准答案的长度
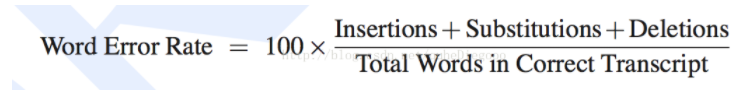
注意:因为有插入词,所以WER有可能大于100%!
例:如下图所示,REF为标准的词序列,第二行为识别出来的词序列
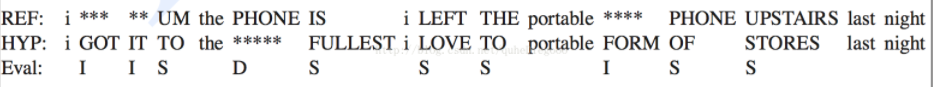
目标词序列中共有13个词,增加词3个,删除词1个,替换词6个,则WER:
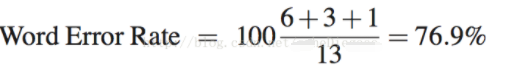
SER:句子中如果有一个词识别错误,那么这个句子被认为识别错误,句子识别错误的的个数,除以总的句子个数即为SER。计算公式:

|
正确答案 总字数 |
命中的字数 |
删除错误字数 |
插入错误字数 |
替换错误字数 |
总错字个数 |
|
|
N |
Mc |
D |
I |
S |
S+I+D |
|
|
准确率/字正确率 |
删除错误率 |
插入错误率 |
替换错误率 |
句错误率 |
词错误率 |
|
|
Corr=Mc/N |
Del=D/N |
Ins = I/N |
Sub = S/N |
SER 句子识别错误的个数/总的句子个数 |
WER =(S+I+D)/N |
5、测试结果的反馈
6、语音识别引擎框架
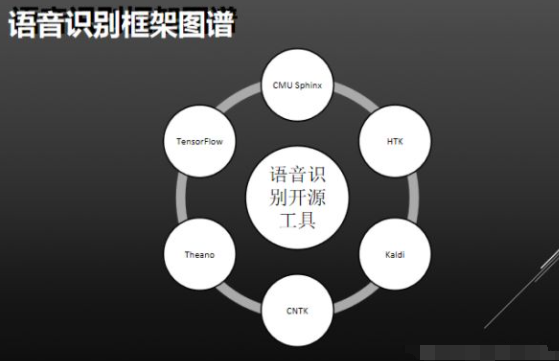
2.1 Hidden Markov Toolkit
Hidden Markov Toolkit由剑桥大学开发的早期经典的语音识别工具包,最早开发于1989年,使用C语言编写,代码和功能非常稳定,集成了最主流的语音识别技术,具有相对完善的文档手册HTK Book。
缺点:更新相对缓慢,缺乏易用的脚本系统,不方便上手
2.2 Microsoft Cognitive Toolkit
微软公司开发的工具箱,开源于2015年, 强大的神经网络功能,定位于多种问题的组合,比如机器翻译+语音识别,是工具包中对Windows平台支持最好的。
缺点:不是完全专业的语音识别工具,需要配合Kaldi等工具使用, 在持续的优化和更新中
2.3 CMU Sphinx
CMU Sphinx由卡内基梅隆大学开发,在Github和SourceForge平台同步更新,至今也有20多年的历史了, 有C和Java两个版本,文档简单易读,贴近实践操作,适合做开发。
缺点:在Github上只有一个管理员维护,其他杂项处理程序(如pitch提取)没有kaldi丰富。
2.4 KAIDI
有全套的语音识别工具,由Dan Povey博士和捷克的BUT大学联合开发,最早发布于2011年,底层代码使用C++编写,接口采用shell和python,覆盖了统计模型和深度学习方法,灵活代码,易于扩展,开发者更为活跃。
缺点:由于贡献者比较多,所以会有不稳定或有问题的代码更新。
7、人机交互的痛点
语音作为目前人机交互的主要方式,大家如果使用过,应该都能举出一些例子。比如说话要靠近,发音要标准,环境要安静,不能持续对话,不能打断等。

不只是语音,包括图像、障碍物检测等技术,都会遇到这样的问题,比如人脸的识别,对光线、角度、距离都有一定的要求。
归结为一点就是,当前人机交互在复杂环境的自适应性方面,还有很多问题需要解决。这还只是感知层面,另外还包括认知层面,AI目前还不如我们想象的这么聪明,目前不能完全自主学习,仍然需要人的介入,比如知识库的导入,机器行为的纠正等,都需要人的参与。
当前的人机交互产品,在真正面对用户时,在面对复杂环境时,鲁棒性还不够好。今天的分享,我们一起探讨如何解决这些问题,不管是通过算法,还是工程,抑或产品,都是我们可以选择的途径。
以前的语音交互产品,包括讯飞在内,大家提供的都是单点的能力,比如语音合成、语音唤醒、语音识别、语义理解,另外还有人脸识别、声纹识别等。大家拿到这么多产品和能力,需要花很大的工作量,去开发人机交互功能。
AIUI交互解决方案:
AIUI是把麦克风阵列、前端声学处理、语音唤醒、端点检测、语音识别、语义理解、语音合成等技术在整个交互链上进行深度融合的系统。
8、开源语音语料库
3.1 LibriSpeech
当前衡量语音识别技术的最权威主流的开源数据集
1000小时英语有声读物
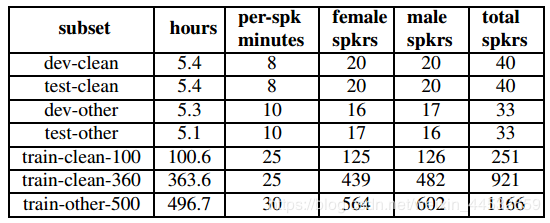
Librispeech: An ASR corpus based on public domain audio books
3.2 牛津大学:VoxCeleb
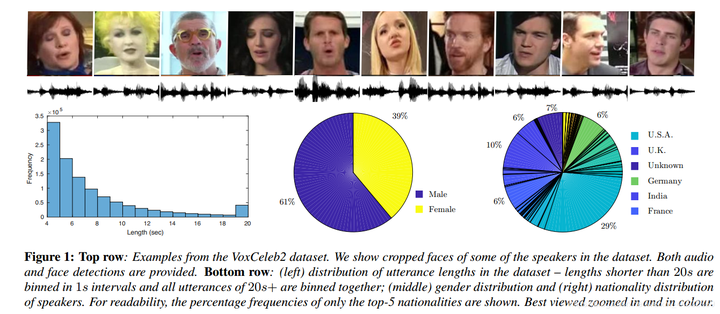
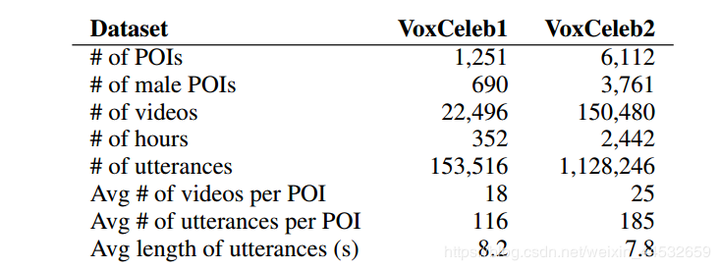
VoxCeleb2: Deep Speaker Recognition 2018 VoxCeleb
3.3 清华大学:Thchs-30
时长30多小时,16kHz,16bits;安静室内,单麦克风;
设计目的:
1 - 增广863数据集(2001年,TCMSD)
2
3 - 提供语音识别基准实验
THCHS-30 : A Free Chinese Speech Corpus 2015 THCHS-30
3.4 数据堂:aidatatang_1505zh
时长1505小时,16kHz,16bits
安静室内或低噪室外,手机设备
采集区域覆盖全国34个省级行政区域
参与录音人数达6408人
录音内容超30万条口语化句子
标注准确率超过98%
数据堂1505小时中文普通话数据集
3.5 数据堂:aidatatang_200zh
时长200小时,16kHz,16bits
安静室内或低噪室外,手机设备
600位来自不同地区的说话人
标注准确率超过98%
训练集:验证集:测试集 = 7:1:2
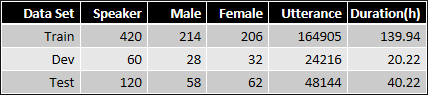


datatang-ailab/aidatatang_200zh

3.6 其他
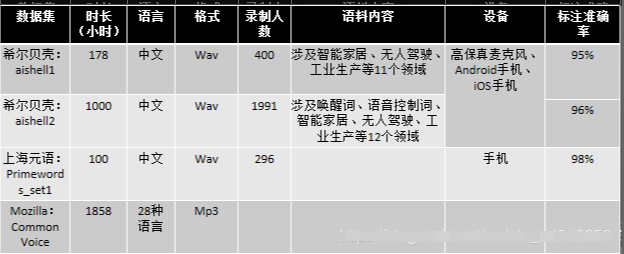
AISHELL-1: An Open-Source Mandarin Speech Corpus and A Speech Recognition Baseline
CommonVoice数据集 Primewords
9、参考文献
语音识别的痛点在哪,从交互到精准识别如何做? https://www.leiphone.com/news/201608/7KTolvJWwpuAWjOI.html