from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge, RidgeCV
from sklearn.metrics import mean_squared_error
def linear_model1():
"""
正规方程
:return: None
"""
# 1.获取数据
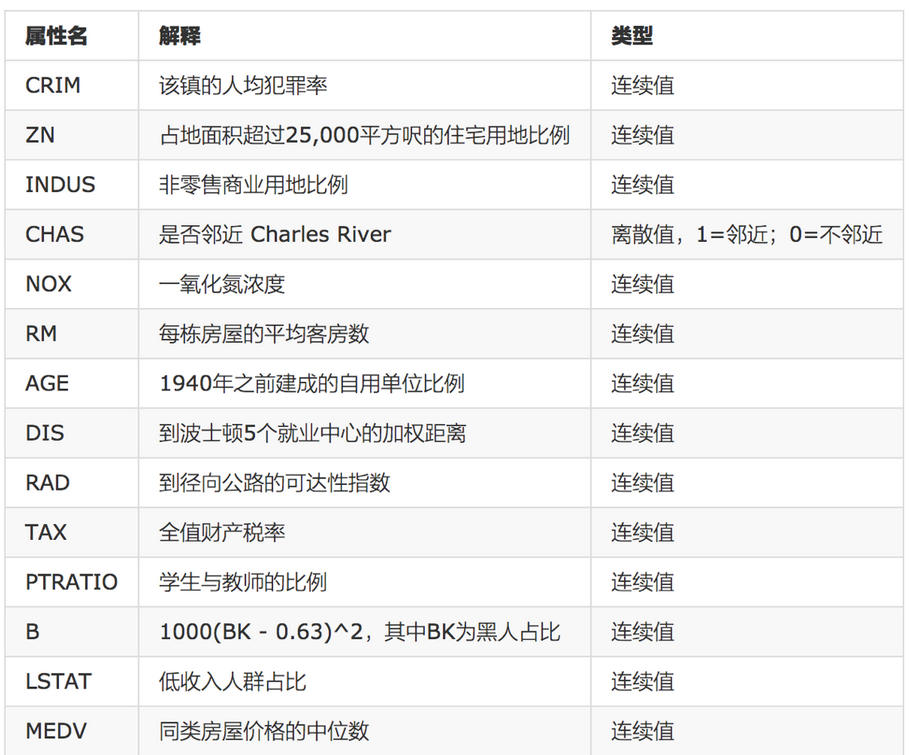
boston = load_boston()
# 2.数据基本处理
# 2.1 数据集划分
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, test_size=0.2)
# 3.特征工程 --标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
# 4.机器学习(线性回归)
estimator = LinearRegression()
estimator.fit(x_train, y_train)
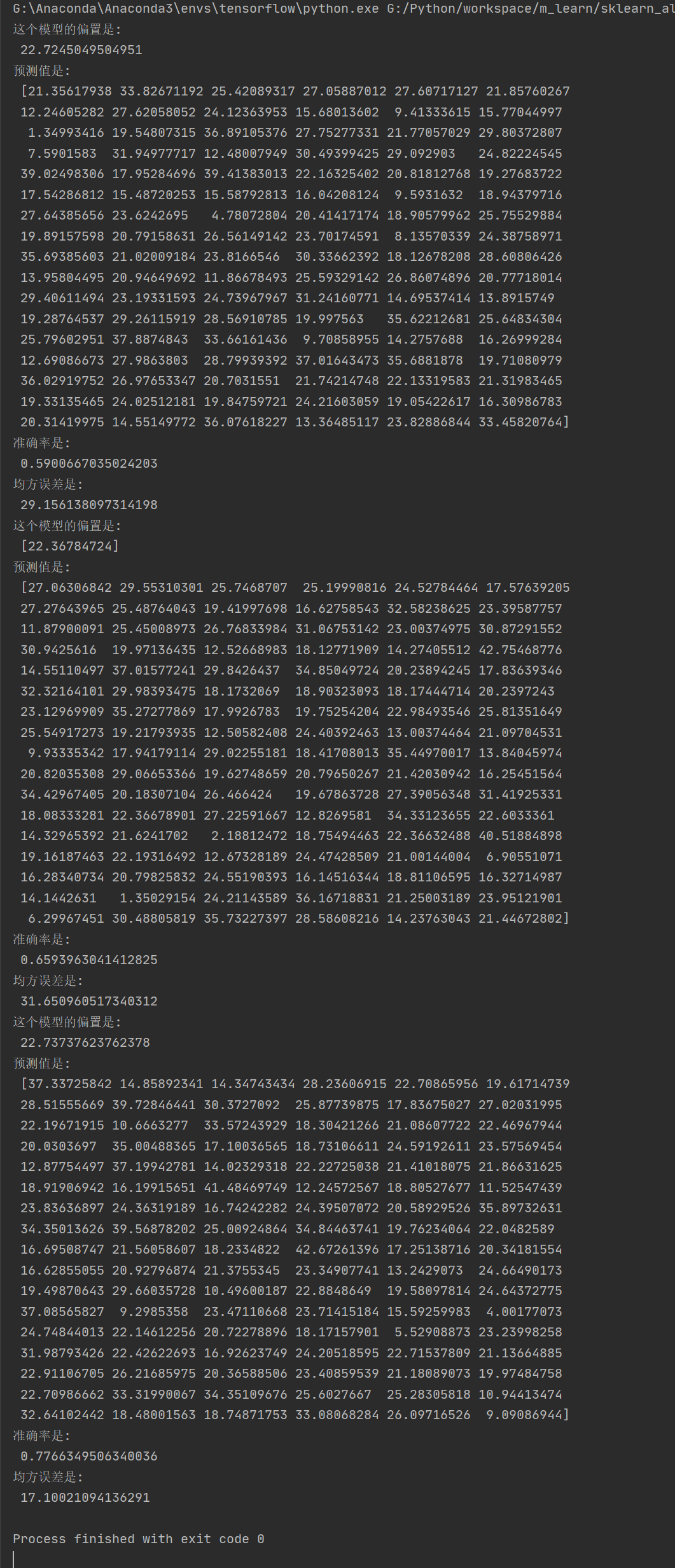
print("这个模型的偏置是:
", estimator.intercept_)
# 5.模型评估
# 5.1 预测值和准确率
y_pre = estimator.predict(x_test)
print("预测值是:
", y_pre)
score = estimator.score(x_test, y_test)
print("准确率是:
", score)
# 5.2 均方误差
ret = mean_squared_error(y_test, y_pre)
print("均方误差是:
", ret)
def linear_model2():
"""
梯度下降法
:return: None
"""
# 1.获取数据
boston = load_boston()
# 2.数据基本处理
# 2.1 数据集划分
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, test_size=0.2)
# 3.特征工程 --标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
# 4.机器学习(线性回归)
estimator = SGDRegressor(max_iter=1000, learning_rate="constant", eta0=0.001)
estimator.fit(x_train, y_train)
print("这个模型的偏置是:
", estimator.intercept_)
# 5.模型评估
# 5.1 预测值和准确率
y_pre = estimator.predict(x_test)
print("预测值是:
", y_pre)
score = estimator.score(x_test, y_test)
print("准确率是:
", score)
# 5.2 均方误差
ret = mean_squared_error(y_test, y_pre)
print("均方误差是:
", ret)
def linear_model3():
"""
岭回归
:return: None
"""
# 1.获取数据
boston = load_boston()
# 2.数据基本处理
# 2.1 数据集划分
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, test_size=0.2)
# 3.特征工程 --标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
# 4.机器学习(线性回归)
# estimator = Ridge()
estimator = RidgeCV(alphas=(0.001, 0.1, 1, 10, 100))
estimator.fit(x_train, y_train)
print("这个模型的偏置是:
", estimator.intercept_)
# 5.模型评估
# 5.1 预测值和准确率
y_pre = estimator.predict(x_test)
print("预测值是:
", y_pre)
score = estimator.score(x_test, y_test)
print("准确率是:
", score)
# 5.2 均方误差
ret = mean_squared_error(y_test, y_pre)
print("均方误差是:
", ret)
if __name__ == '__main__':
linear_model1()
linear_model2()
linear_model3()