这篇文章是在上一篇常用正则表达式(合) https://blog.csdn.net/yeyeye200/article/details/86186889
基础上的延伸:关于通配符的使用~
一开始get通配符的好处,是为了实现[分别提取文档中的中英文]。
在网上搜了一下正则表达式的提取方法,有点复杂而且很容易搞混。所以换了个方向,最终搜到一强大网友给出的表达式:
<[!^1-^127]>
ps:<[!^1-^127]>表示ASCII码不在1-127范围的所有字符,即中文字符、全角字符等。体现为下面图片显示的结果,简单直接。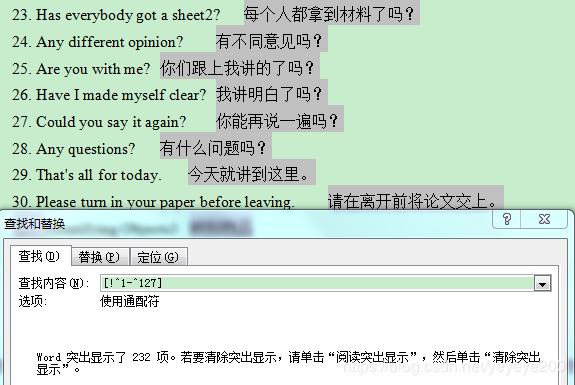
完爆正则,当然前提是:不涉及代码
如果日常生活中不涉及代码&&文档处理繁多复杂,那word自带的通配符处理,就可以解决大部分的操作烦恼了。并且熟悉了通配符的使用之后,还可以应用到其它文字编辑器当中(如Notepad++~UltraEdit),发散思维。
有关通配符的操作使用手册,word2007的脱机帮助文档做得很好,本来我想把这一部分直接转载出来的,但我电脑上安装的是word2010,word2010的脱机帮助文档,没有通配符相关的操作手册,网上也没有下载07脱机帮助文档的渠道,所以就借用其他的博客内容。链接如下:

以下是摘抄:
使用通配符搜索
选中"使用通配符"复选框后,Word只查找与指定文本精确匹配的文本(请注意,"区分大小写"和"全字匹配"复选框会变灰而不可用,表明这些选项已自动选中,您不能关闭这些选项)。
要查找已被定义为通配符的字符,请在该字符前键入反斜扛(),例如,要查找问号,可键入"?"。
|
序号 |
查找内容 |
通配符 |
示例 |
|
1. |
任意单个字符 |
? |
例如,s?t可查找"sat"和"set"。 |
|
2. |
任意字符串 |
* |
例如,s*d可查找"sad"和"started"。 |
|
3. |
单词的开头 |
< |
例如,<(inter)查找"interesting"和"intercept",但不查找"splintered"。 |
|
4. |
单词的结尾 |
> |
例如,(in)>查找"in"和"within",但不查找"interesting"。 |
|
5. |
指定字符之一 |
[] |
例如,w[io]n查找"win"和"won"。 |
|
6. |
指定范围内任意单个字符 |
[-] |
例如,[r-t]ight查找"right"和"sight"。必须用升序来表示该范围。 |
|
7. |
中括号内指定字符范围以外的任意单个字符 |
[!x-z] |
例如,t[!a-m]ck查找"tock"和"tuck",但不查找"tack"和"tick"。 |
|
8. |
n个重复的前一字符或表达式 |
{n} |
例如,fe{2}d查找"feed",但不查找"fed"。 |
|
9. |
至少n个前一字符或表达式 |
{n,} |
例如,fe{1,}d查找"fed"和"feed"。 |
|
10. |
n到m个前一字符或表达式 |
{n,m} |
例如,10{1,3}查找"10"、"100"和"1000"。 |
|
11. |
一个以上的前一字符或表达式 |
@ |
例如,lo@t查找"lot"和"loot"。 |
有了通配符这个工具,再加上你强大的大脑,组合各种查询方式,嗨起来吧。
这里记录一些常用组合:
[0-9]或^#代表任意单个数字
[!0-9]代表所有非数字字符
[a-zA-Z]或^$代表任意英文字母
[a-z]代表所有小写字母
[A-Z]代表所有大写字母
[^1-^127]代表所有西文字符
[!^1-^127]代表所有中文汉字和中文标点
[一-龥]or[一-﨩]代表所有中文汉字
[!一-龥^1-^127]代表所有中文标点
当然,深入一点,还有分组的用法,与正则类似。