1. 上一篇我们已经稍微体验了一下用 urllib 和 BeautifulSoup 爬数据的基本操作。现在开始正式准备扒一个网站了。
1)首先确定扒谁? 由于我对狗东恨之入骨(狗贼刘强东老太可恶了,用我的钱,养我的奶茶妹,这种人,人人得而诛之!!!), 所以我们打算扒强东。
2)狗东有什么数据? 商品 和 店铺.
3)商品有什么值得扒的东西? 名字 + 价格 + 评价数量(好评+差评)+ 交易量
4)店铺有什么值得扒的东西? 店铺名 + 店铺销售类目 + 店铺评价?
2. 有了目标,我们就可以开始干了!
1)先找一个商品。比如。。。emmm作为一个男人,为了保持愉快的爬虫开发体验,我们研究一个裙子 : 梵钰美 2018新款秋冬季韩版性感包臀夜店女装针织连衣裙长袖毛衣女套头打底中长裙春20 黑色 均码
2)先看这个链接 https://item.jd.com/10671563387.htm, 很显然,这一串数字很有可能就是和商品一 一对应的 ID , 记下来这个知识点, 后期我们大量爬数据的时候可以作为去重的凭证。
3)我们进到这个页面,我把暂定要扒的数据标记了一下
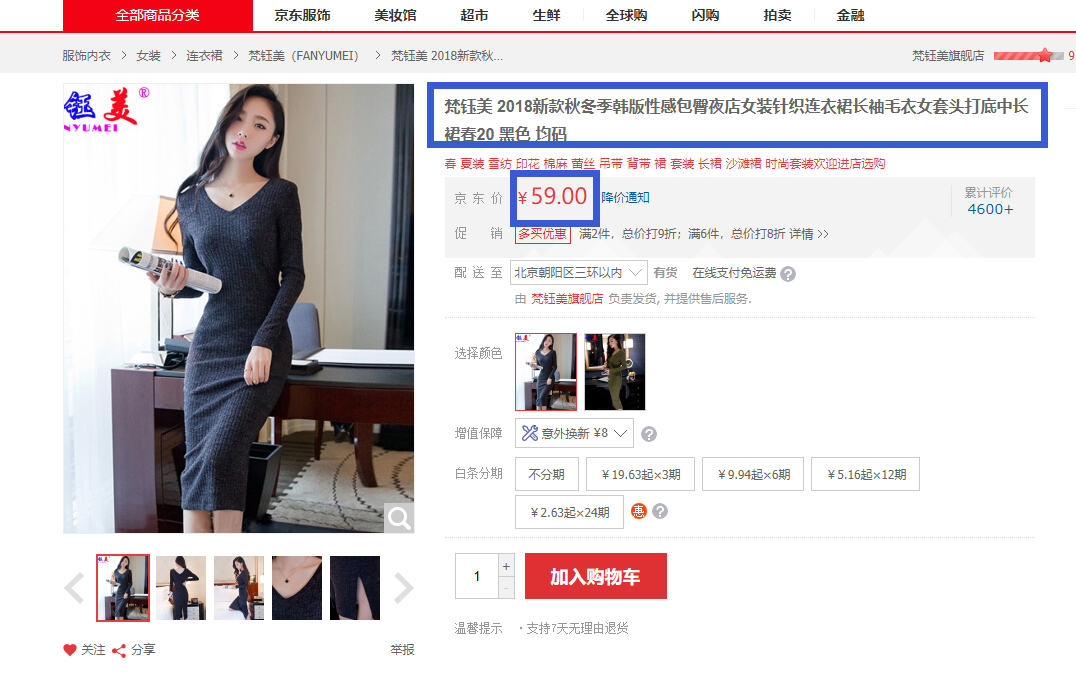
4)以我为数不多的 java 爬虫经验,很不服责任地告诉大家:我们昨天那样简单粗暴地获取到的页面并不一定是你浏览器打开后看到的页面。一般你一个url丢进去urlopen( url ), 看到的是以下这么个东西的数据。
a. 首先你右键点击这个页面的空白处, 然后 查看网页源代码,就能看到后面那张图了。这些数据就是昨天在控制台打印的数据。
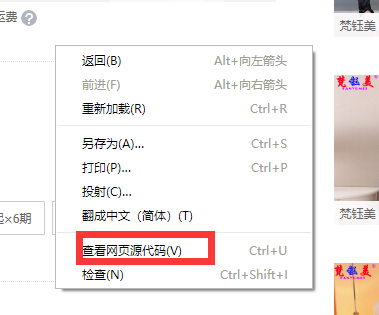

b. 我们来验证一下我们浏览器看到的页面的数据和这串代码的数据是不是一样的。首先我们把源代码这一页全选复制保存到一个txt文件里,像这样。然后我们把txt的后缀名改成 .html
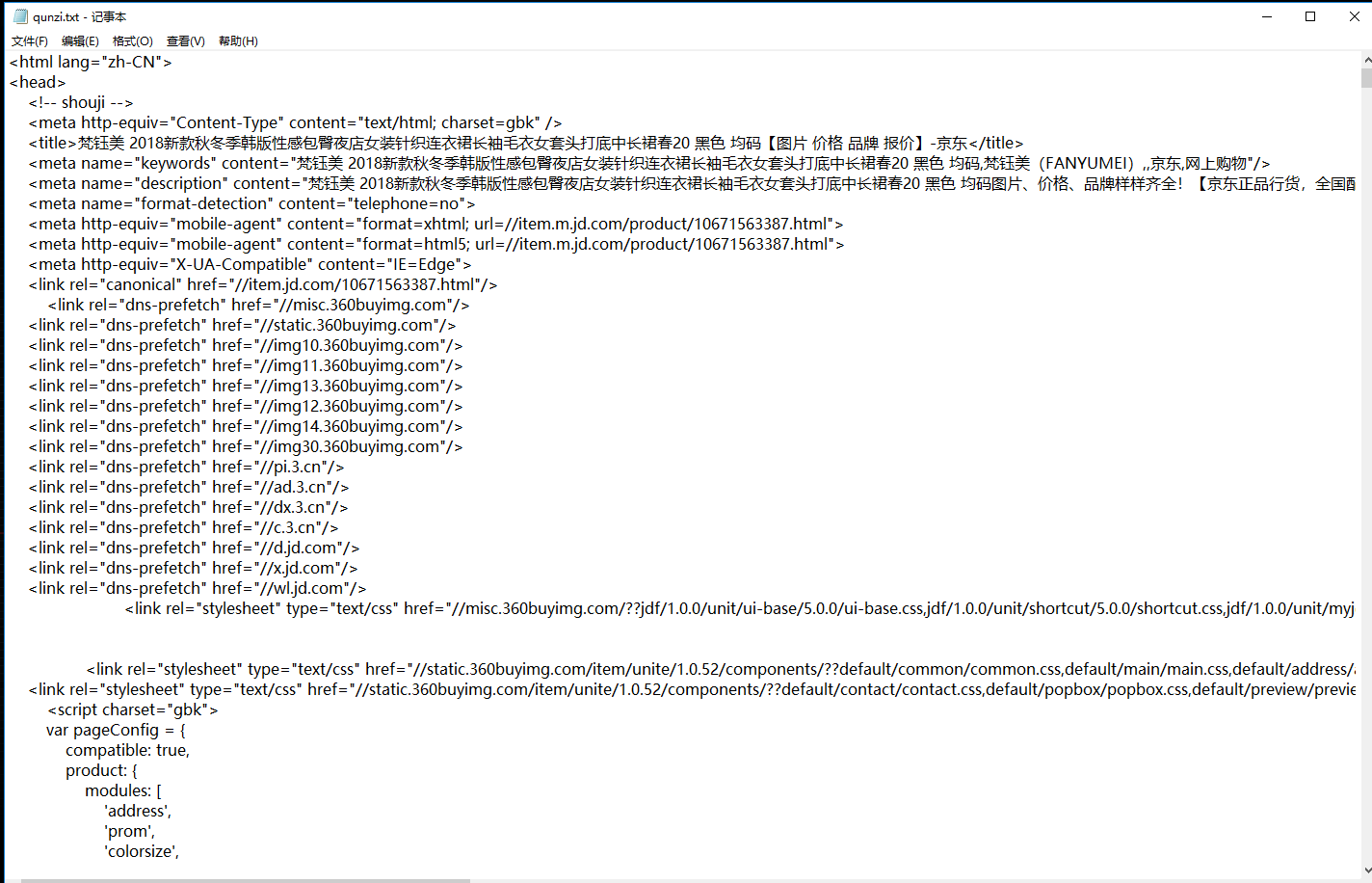
c. 像这样,然后用Chrome浏览器打开。见证奇迹的时刻到了, 你就看到了一个这样的页面。我们忽略由于没有css文件和图片造成的布局错乱问题,你会发现这个页面的数据,少得可怜。没有售价。看最后一张图很直观,评价数据没有。
这是因为现在一个页面的数据非常多,如果一次性全部吐出来服务器和客户端压力都很大。所以先抛出一部分数据。这个源码里的数据就是一开始抛出来的。这个页面刷出来后又会再次像服务器请求售价,评价,关联商品这样的数据。



d. 那么问题就来了, 我们一开始就只获取了这点数据,根本没法满足我们要抓取的需求。怎么办?浏览器自带的开发者工具用处就体现出来了。我们回到刚才那个裙子的页面,欣赏一下美女,然后按F12调出开发者工具, 按箭头指示来到这么一个地方
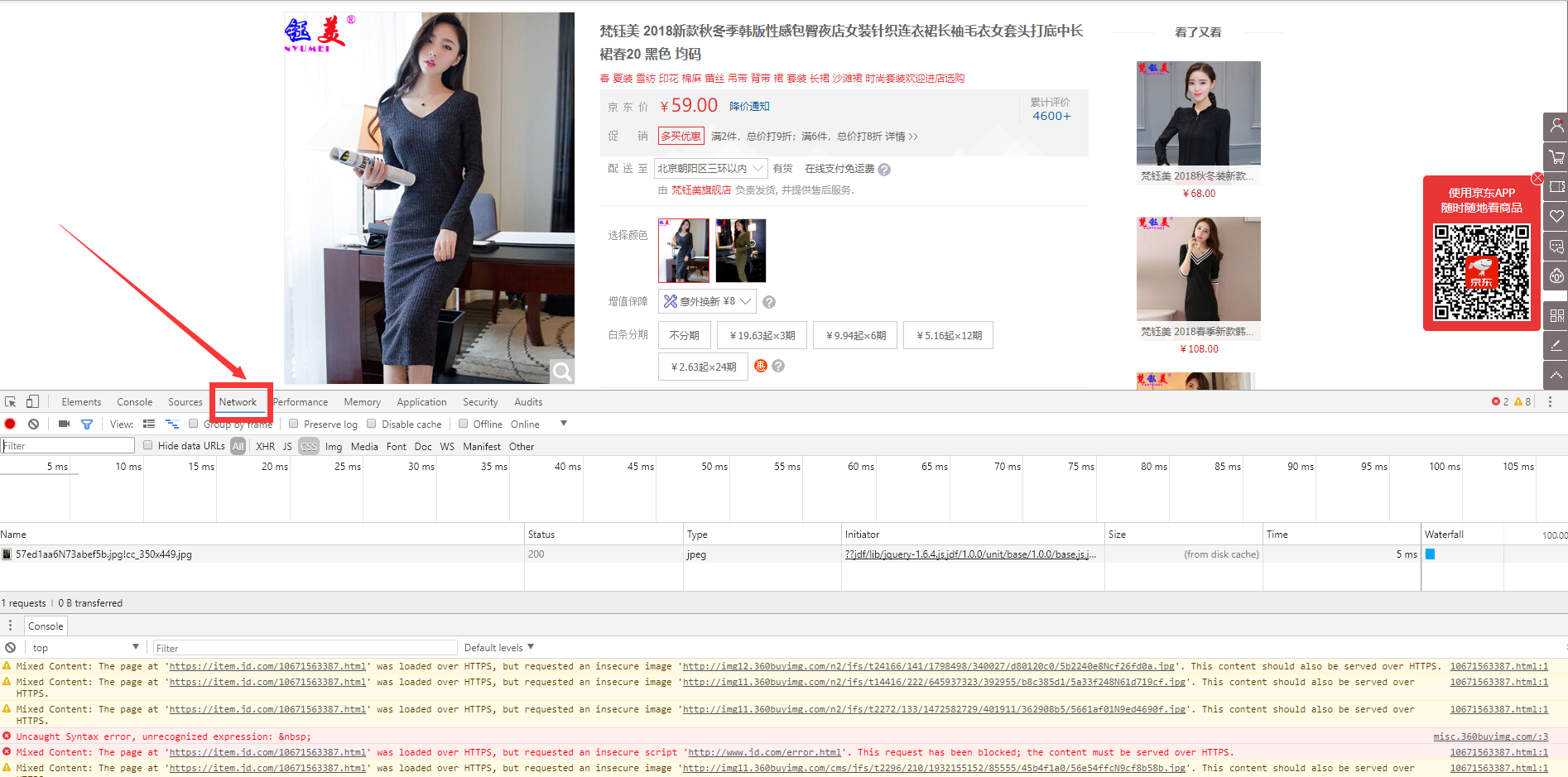
f. 刷新一下页面我们看到开发者工具调试框在疯狂地写数据。这个红框里就是在做不断请求数据地操作。
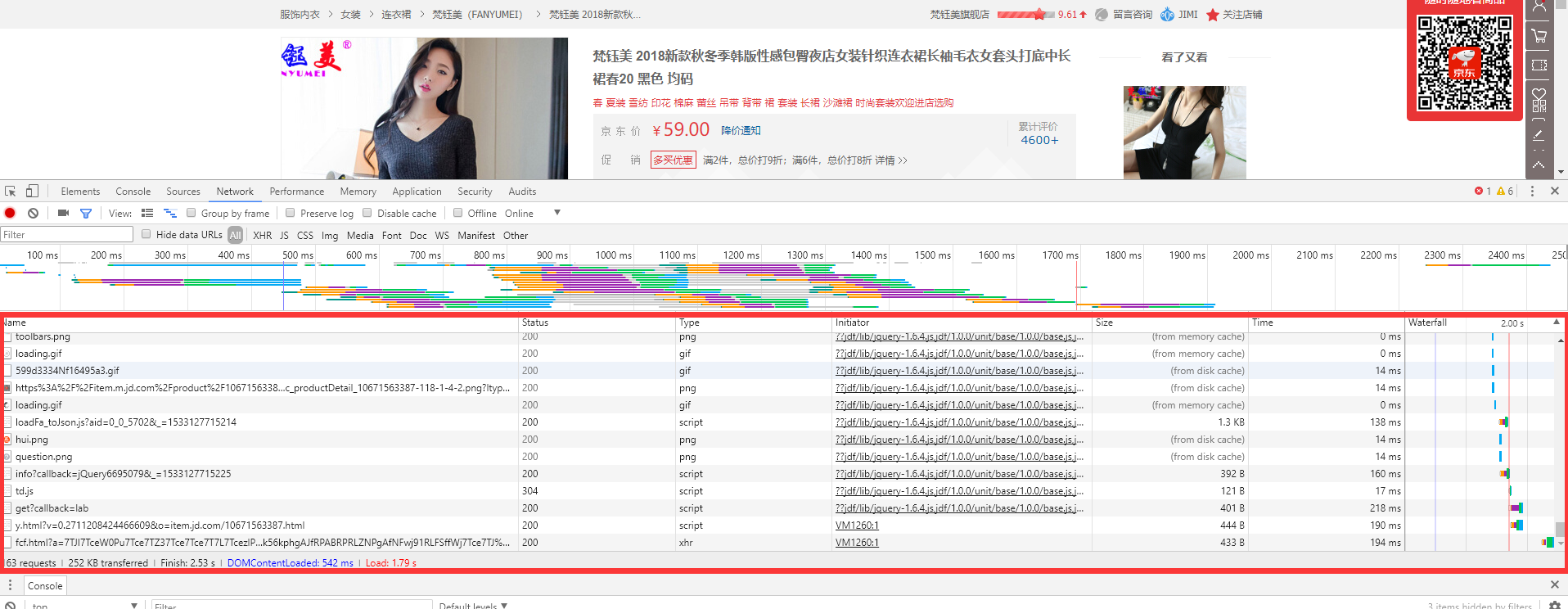
g. 由于我天(丧)赋(心)异(病)禀(狂),我很快地找了关于评价和价格的请求,如下。



h. 其实上面的价格为什么少了1块钱我也不知道,我们点Heraers。 朋友们,接下来的这张图全是知识点。这是我们获取数据需要的信息。有了这些,交给python就可以了
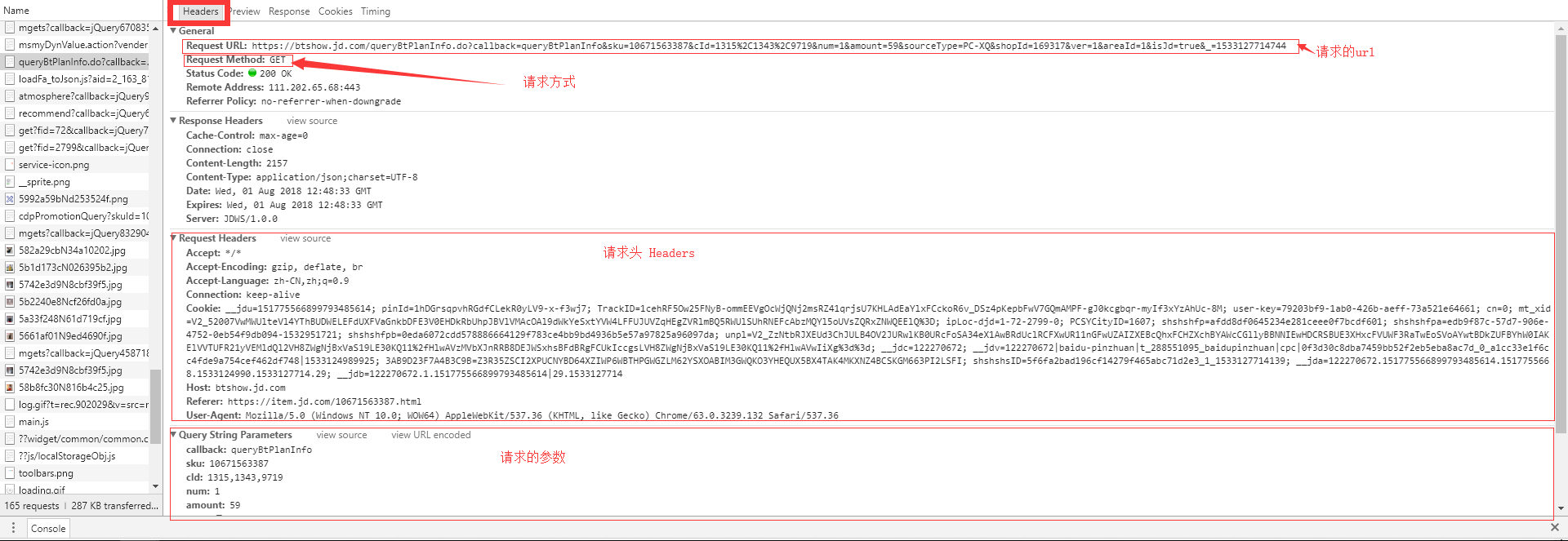
j. 我们可以试一下用python请求这条链接: https://btshow.jd.com/queryBtPlanInfo.do?callback=queryBtPlanInfo&sku=10671563387&cId=1315%2C1343%2C9719&num=1&amount=59&sourceType=PC-XQ&shopId=169317&ver=1&areaId=1&isJd=true&_=1533127714744
看代码
import urllib.request header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36', 'Referer': 'https://item.jd.com/10671563387.html' } url = "https://btshow.jd.com/queryBtPlanInfo.do?callback=queryBtPlanInfo&sku=10671563387&cId=1315%2C1343%2C9719&num=1&amount=59&sourceType=PC-XQ&shopId=169317&ver=1&areaId=1&isJd=true&_=1533127714744" request = urllib.request.Request(url=url, headers=header) # url为爬取的链接,headers主要是假装我们不是爬虫,现在我们就假装我们是个Chrome浏览器 response = urllib.request.urlopen(request) # 请求数据 data = response.read() # 读取返回的数据 data.decode("UTF-8") # 设置字符格式为utf-8,可以处理中文 print(data)
输出如下。OJBK。所以到现在我们的任务变成了抓取这条url的参数。然后再去请求这些数据
queryBtPlanInfo({"planInfos":[{"fee":0.00,"planFee":0.00,"firstPay":58.00,"laterPay":58.00,"total":58.00,"curTotal":58.00,"plan":1,"rate":0.00,"firstRepayDate":"2018-09-01","isDiscount":true,"discountList":[{"activityCode":
"00001","couponCode":"00001","discountAmount":"1.00","couponInfo":"xe3x80x90xe6xbfx80xe6xb4xbbxe7x99xbdxe6x9dxa1xe3x80x91xe6x96xb0xe7x94xa8xe6x88xb7xe5xbex97xe7x99xbexe5x85x83xe7xa4xbcxe5x8cx85","activityType":"ZJ"}],"isMaxDiscount":true},{"fee":0.87,"planFee":0.29,"firstPay":19.62,"laterPay":19.63,"total":58.87,"curTotal":19.63,"plan":3,"rate":0.50,"firstRepayDate":"2018-09-01","isDiscount":true,"discountList":[{"activityCode":"00001","couponCode":"00001","discountAmount":"1.00","couponInfo":"xe3x80x90xe6xbfx80xe6xb4xbbxe7x99xbdxe6x9dxa1xe3x80x91xe6x96xb0xe7x94xa8xe6x88xb7xe5xbex97xe7x99xbexe5x85x83xe7xa4xbcxe5x8cx85","activityType":"ZJ"}],"text":"xe8xb5xb7","isMaxDiscount":false},{"fee":1.74,"planFee":0.29,"firstPay":9.96,"laterPay":9.94,"total":59.74,"curTotal":9.94,"plan":6,"rate":0.50,"firstRepayDate":"2018-09-01","isDiscount":true,"discountList":[{"activityCode":"00001","couponCode":"00001","discountAmount":"1.00","couponInfo":"xe3x80x90xe6xbfx80xe6xb4xbbxe7x99xbdxe6x9dxa1xe3x80x91xe6x96xb0xe7x94xa8xe6x88xb7xe5xbex97xe7x99xbexe5x85x83xe7xa4xbcxe5x8cx85","activityType":"ZJ"}],"text":"xe8xb5xb7","isMaxDiscount":false},{"fee":3.48,"planFee":0.29,"firstPay":5.12,"laterPay":5.16,"total":61.48,"curTotal":5.16,"plan":12,"rate":0.50,"firstRepayDate":"2018-09-01","isDiscount":true,"discountList":[{"activityCode":"00001","couponCode":"00001","discountAmount":"1.00","couponInfo":"xe3x80x90xe6xbfx80xe6xb4xbbxe7x99xbdxe6x9dxa1xe3x80x91xe6x96xb0xe7x94xa8xe6x88xb7xe5xbex97xe7x99xbexe5x85x83xe7xa4xbcxe5x8cx85","activityType":"ZJ"}],"text":"xe8xb5xb7","isMaxDiscount":false},{"fee":6.96,"planFee":0.29,"firstPay":2.71,"laterPay":2.63,"total":64.96,"curTotal":2.63,"plan":24,"rate":0.50,"firstRepayDate":"2018-09-01","isDiscount":true,"discountList":[{"activityCode":"00001","couponCode":"00001","discountAmount":"1.00","couponInfo":"xe3x80x90xe6xbfx80xe6xb4xbbxe7x99xbdxe6x9dxa1xe3x80x91xe6x96xb0xe7x94xa8xe6x88xb7xe5xbex97xe7x99xbexe5x85x83xe7xa4xbcxe5x8cx85","activityType":"ZJ"}],"text":"xe8xb5xb7","isMaxDiscount":false}],"creditStatus":2,"isDiscountAll":true,"isLogin":false,"isBtUser":false,"isFull":false,"isAva":true,"isShopAva":true,"isSkuAva":true,"isItemAva":true,"noAvaInfo":"","key":"83A0C5DEA5C338767657A14B878B62BC","ver":"1","marketingText":"xe3x80x90xe6xbfx80xe6xb4xbbxe7x99xbdxe6x9dxa1xe3x80x91xe6x96xb0xe7x94xa8xe6x88xb7xe5xbex97xe7x99xbexe5x85x83xe7xa4xbcxe5x8cx85","result":{"isSuccess":true,"code":"00000","info":"success"}})'