好久没更新博客园了,说来也惭愧,之前说好每隔几天更新一个的,虽然没什么人看,但是作为一个记录,回顾也是能有新的认识,这篇博客是讲的目前我在工作中使用的一个结束点,这个技术点目前网上资料少之甚少,也是希望给刚接触的人一个大概的思路,稍作分析下。说了这么多其实我也是个半吊子,也就间接性的踌躇满志,想到一出是一出,写下这个博客都是脑子一热,只是在自己使用的过程中遇到很多问题,解决的比较艰难,查资料又查不了,只能看官方文档,官方文档又是全英文的,阅读起来速度又比较慢,看翻译之后的有很多翻译根本就不对,会导致对方法的错误理解和使用。总之贼鸡儿烦,所以下面的东西希望对你有所帮助,讲的内容不多,也不深,只是给刚刚接触的一个介绍,和自己的一个记录,说了这么多自己都不知道说啥,欲言又止,作为一个程序员在生活中没有那么多时间去扯犊子,所以我就在这多唠叨几句了,对了我还有一个学习的群,有兴趣的可以进来玩玩,494696003 反正没事进来唠唠嗑啥的也是不错的。
首先申明:一下内容仅供参考,切勿转发。 阅读一下文章需要对TICK架构脚本 有一定了解,起码知道TICK是干嘛的,里面的一部分语法是怎样的。 熟悉一下TICK的官方文档有一定的必要,否则可能不知道我在说啥。

下面我们去看下tick里面的脚本长什么样
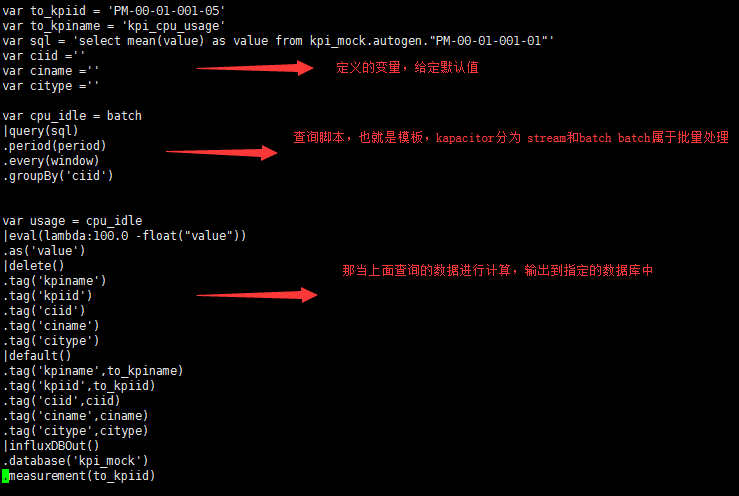
在这个地方给大家介绍一下 脚本为啥要这样写:
TICK 遵循一定的规范,官网可以查。
|query(sql) 此节点可以执行sql的查询语句,
.period(10m) 此链接方法 是属于query下的,意为查询时间的范围,也就是说如果到时候你的sql写完之后 会在真正执行的时候在你的sql后面拼接 where xx - xx 时间的范围查询,这个范围就是你设定的 10m
.window(10) 以此类推 一下就不多做说明,这个也是属于query的连接方法,意为每个多长时间我们的脚本去执行一次这个查询的时间,也就是10分钟去执行一次查询。
.groupBy('ciid') 这是根据给定的字段进行分组。
|eval 这个节点是TICK脚本中用于业务计算的一个节点,通过lambda表达式能够对以上查询出来的数据进行计算。 计算的时候在tick中 只有浮点数和整数的概念,所以计算的2侧的数据类型要一致否则脚本运行出错。 |influxDBOut() 这个节点是将以上的数据计算之后 输出到制定的数据库中。 .databases(xx) .measurement(xx) 以上数据库均是Influxdb
以下是我写的一个脚本:计算CPU使用率的一个模板 脚本
var period = 10m
var window = 10m
var to_kpiid = 'PM-00-01-001-05'
var to_kpiname = 'kpi_cpu_usage'
var sql = 'select mean(value) as value from kpi_mock.autogen."PM-00-01-001-01"'
var ciid = ''
var ciname = ''
var citype = ''
var cpu_idle = batch
|query(sql)
.period(period)
.every(window)
.align()
var usage = cpu_idle
|eval(lambda: 100.0 - float("value"))
.as('value')
|delete()
.tag('kpiname')
.tag('kpiid')
.tag('ciid')
.tag('ciname')
.tag('citype')
|default()
.tag('kpiname', to_kpiname)
.tag('kpiid', to_kpiid)
.tag('ciid', ciid)
.tag('ciname', ciname)
.tag('citype', citype)
|influxDBOut()
.database('kpi_mock')
.measurement(to_kpiid)
如何定义一个模板(template 此处batch为例,stream类似)
batch_avg_test为自己取名 带上.tick 即你的tick脚本 类型为batch
./kapacitor define-template batch_avg_test -tick batch_avg_test.tick -type batch
如何根据一个模板创建具体的任务(task)
在创建具体任务的时候 你需要根据模板参数 写一个相应的json文件,将参数传入模板当中 生成具体的任务
PM-XX-XX-XX-XX:为任务名称
batch_avg_test:模板名称(即刚上面创建的模板)
test.json:传入数据的json文件
xxx.autogen 制定脚本当中执行sql语句和输出数据库的 保留策略(见官方文档)
./kapacitor define PM-XX-XX-XX-XX -template batch_avg_test -vars test.json -dbrp xxx.autogen
在kapacitor的后台当中 有很多命令都是查看 任务 模板 状态 ,这些都在官方文档有介绍,我这列出一些图给大家进行参考结合自己的理解。
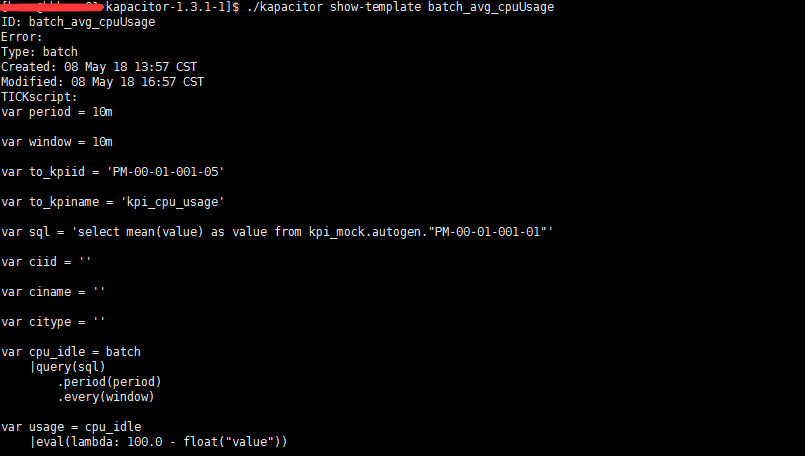
这个是查看 定义脚本之后生成的模板命令,展示的就是模板。

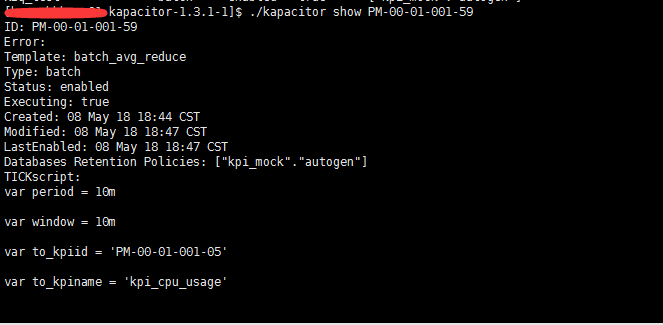
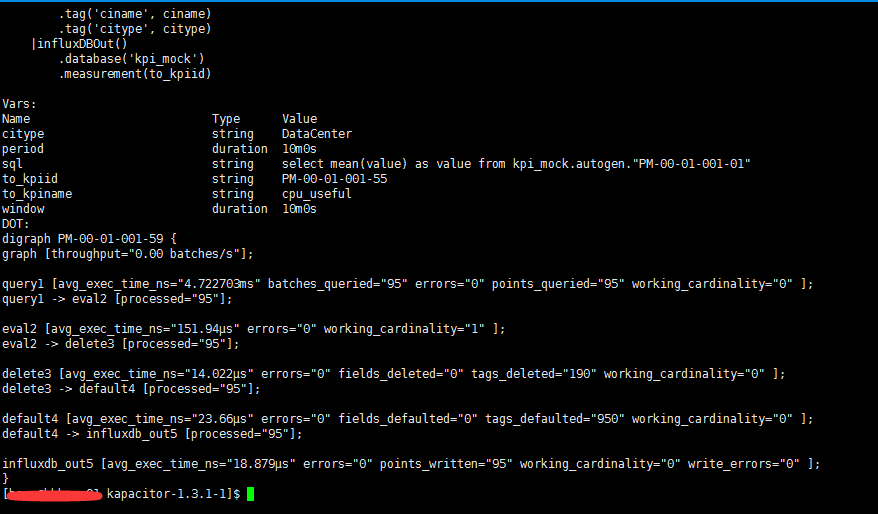
想要查看具体模板的信息 如下图
这个是查看 根据模板 生成具体的任务, 展示的是任务
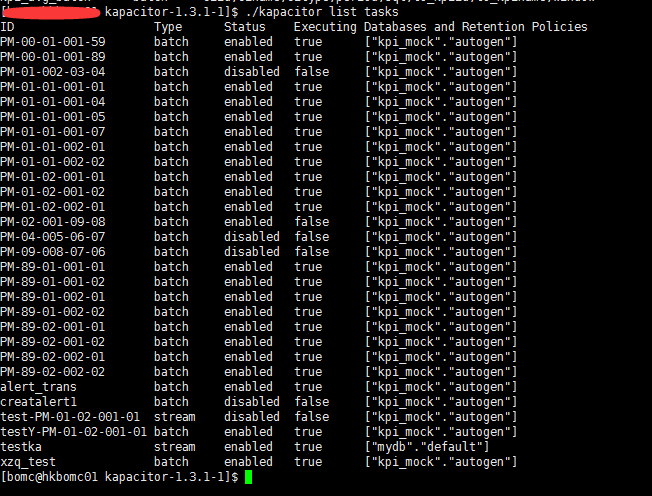
想要查看每一个任务的具体的状态信息可以执行,可以查看到具体的执行时间,写入的节点数等等...
如果在操作的过程中,状态那边的节点数都是0 如果有error 那个error那里会显示出具体的个数,但是不会显示具体的错误。具体错误查看下面讲解。
相信大家现在对TICK 具体是什么有一定的了解了吧。 下来我们查看下如何查看我们的TICK脚本 都执行了什么,错在了,怎么查看日志
还记得第一张图中有一个 KapaData的目录吗,进去到log 目录下执行
grep PM-XX-XX-XX-XX *.log
其中 PM-XX-XX-XX-XX 代表着你具体的执行任务的名称
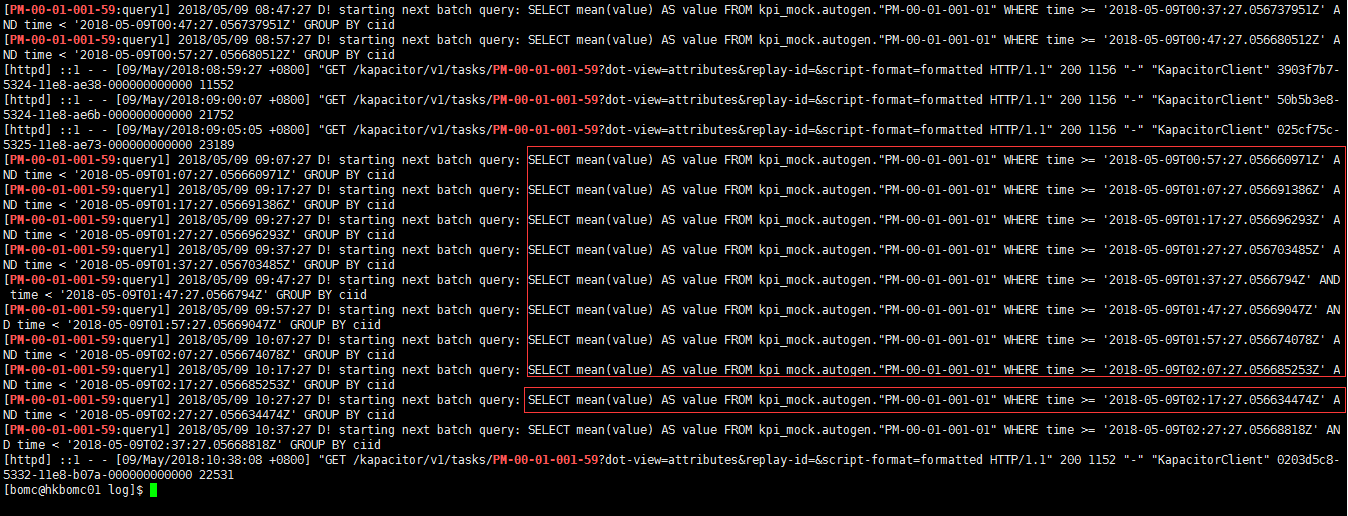
这样你就知道你的任务具体是怎么跑,出什么错都会在这里显示,还有sql 语句,将sql复制去influxdb 执行就能对比出来数据是否正确了。
以上是使用TICK 的一整套的流程,具体的计算方式需要阅读官方文档,例如计算,保留策略,节点,链接方法,精度等问题。 所有运行都没问题的情况下,你只需查看influxdb数据库产生的表中的数据是否正确即可。这样一整套TICK脚本监控指标就完成了。 文中有很多没有详细讲解,毕竟时间有限,篇幅有限,如有时间继续细化内容。(如有差错望博友指正以至于及时修改,浅显讲解勿喷~都是有素质的人) 在这里祝大家工作顺利,所有BUG都能顺利结局~ 再见