先摆上JDK1.8中hashMap的类注释;我翻译了一下
/** * Doubly-linked list implementation of the {@code List} and {@code Deque} * interfaces. Implements all optional list operations, and permits all * elements (including {@code null}). * 双向链表实现了List和Deque接口。实现了List所有的操作,双向链表允许所有元素,包括null * * <p>All of the operations perform as could be expected for a doubly-linked * list. Operations that index into the list will traverse the list from * the beginning or the end, whichever is closer to the specified index. * 对于LinkedList所有的操作都是可以被预期的。操作LinkedList将会遍历LinkedList的指针. * 解读:通过set(i,e),get(i)访问LinkedList的元素时,要遍历指针,如果i>LinkedList容量的一半, * 就从尾部开始遍历. * * <p><strong>Note that this implementation is not synchronized.</strong> * If multiple threads access a linked list concurrently, and at least * one of the threads modifies the list structurally, it <i>must</i> be * synchronized externally. (A structural modification is any operation * that adds or deletes one or more elements; merely setting the value of * an element is not a structural modification.) This is typically * accomplished by synchronizing on some object that naturally * encapsulates the list. * 注意,LinkedList是线程不同步的.如果多线程同时访问LinkedList,此时如果有一个线程修改LinkedList结构, * 那么就必须在外层进行同步操作处理(这里的修改结构包括添加元素,删除元素)。 * 解读:ArrayList同样有此特性. * * If no such object exists, the list should be "wrapped" using the * {@link Collections#synchronizedList Collections.synchronizedList} * method. This is best done at creation time, to prevent accidental * unsynchronized access to the list:<pre> * List list = Collections.synchronizedList(new LinkedList(...));</pre> * 考虑线程同步问题,可以用Collections.synchronizedList替代LindedList * * <p>The iterators returned by this class's {@code iterator} and * {@code listIterator} methods are <i>fail-fast</i>: if the list is * structurally modified at any time after the iterator is created, in * any way except through the Iterator's own {@code remove} or * {@code add} methods, the iterator will throw a {@link * ConcurrentModificationException}. Thus, in the face of concurrent * modification, the iterator fails quickly and cleanly, rather than * risking arbitrary, non-deterministic behavior at an undetermined * time in the future. * 在迭代一个LinkedList时,任何修改LinkedList的操作,迭代器都会终止,并抛出 * ConcurrentModificationException异常. * * <p>Note that the fail-fast behavior of an iterator cannot be guaranteed * as it is, generally speaking, impossible to make any hard guarantees in the * presence of unsynchronized concurrent modification. Fail-fast iterators * throw {@code ConcurrentModificationException} on a best-effort basis. * Therefore, it would be wrong to write a program that depended on this * exception for its correctness: <i>the fail-fast behavior of iterators * should be used only to detect bugs.</i> * 快速失败机制,是一种错误检测机制。它只能被用来检测错误,因为JDK并不保证fail-fast机制一定会发生. * 参考我的博客 ”Iterator fail-fast“ * * @author Josh Bloch * @see List * @see ArrayList * @since 1.2 * @param <E> the type of elements held in this collection */ public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable
总结
1. LinkedList是基于链表结构实现,所以在类中包含了first和last两个指针(Node)。Node中包含了上一个节点和下一个节点的引用,这样就构成了双向的链表。每个Node只能
知道自己的前一个节点和后一个节点,但对于链表来说,这已经足够了
在此看一下LinkedList的数据结构,立体感受一下这个特性
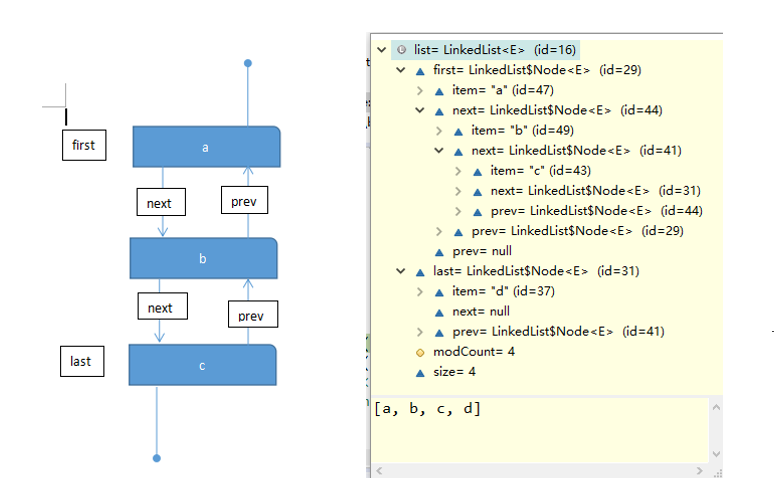
所以LinkedList插入和删除元素效率很高,比ArrayList高。通过set(i,e),get(i)访问效率低,因为要遍历指针,如果i>size/2,那么就从尾部开始遍历。
翻阅get(i),set(i,E)的源码
1 /** 2 * Replaces the element at the specified position in this list with the 3 * specified element. 4 * 5 * @param index index of the element to replace 6 * @param element element to be stored at the specified position 7 * @return the element previously at the specified position 8 * @throws IndexOutOfBoundsException {@inheritDoc} 9 */ 10 public E set(int index, E element) { 11 checkElementIndex(index); 12 Node<E> x = node(index); 13 E oldVal = x.item; 14 x.item = element; 15 return oldVal; 16 } 17 18 /** 19 * Returns the element at the specified position in this list. 20 * 21 * @param index index of the element to return 22 * @return the element at the specified position in this list 23 * @throws IndexOutOfBoundsException {@inheritDoc} 24 */ 25 public E get(int index) { 26 checkElementIndex(index); 27 return node(index).item; 28 } 29 30 /** 31 * Returns the (non-null) Node at the specified element index. 32 */ 33 Node<E> node(int index) { 34 // assert isElementIndex(index); 35 36 if (index < (size >> 1)) { 37 Node<E> x = first; 38 for (int i = 0; i < index; i++) 39 x = x.next; 40 return x; 41 } else { 42 Node<E> x = last; 43 for (int i = size - 1; i > index; i--) 44 x = x.prev; 45 return x; 46 } 47 }
很明显,在进行set和get操作时,并不是每次都从头部开始遍历指针的,而是调用了node(int index)这个方法,就是用来判断当前index的大致位置,如果i<(size>>1)也就是i<size/2,那么从first开始遍历,否则从last开始遍历。此时set,get操作的时间复杂度也就由O(n)变成了O(n/2)
2. 链表没有容量限制,但是双向链表本身使用了更多的空间.每插入一个元素都要构造一个Node对象
3. LinkedList线程不同步,采用fail-fast机制