游戏中的三维数学
坐标系
笛卡尔坐标系:使用两个或三个相互垂直的轴来描述二维或三维空间的位置;如图1
圆柱坐标系:使用垂直“高度”轴h,垂直轴发出的辐射轴r和旋转的角度θ来表示一个位置;(类似平面的极坐标加上高度)如图2
球坐标系:使用俯仰角φ、偏航角θ和半径长度r来表示一个位置。如图3

左手坐标系和右手坐标系
右手坐标系三个轴方向为,右手握拳,伸出拇指指向x轴、食指指向y轴、中指指向z轴;同理左手坐标系使用左手。
比较左右手坐标系发现,两者只是三个轴中一个轴的方向相反,即翻转其中一个轴即可实现两个坐标系的变换。
矢量运算
矢量和标量的乘积:sa = (sax,say,saz)
矢量和标量的乘积可以看成对矢量的统一缩放,而矢量的非统一缩放如下:

它实际上等同于
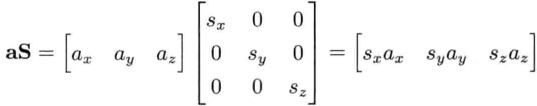
矢量的加减法



矢量的模
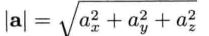
单位矢量
模为1的矢量为单位矢量,将任意矢量转换为单位矢量的过程称为归一化。
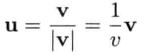
法矢量是垂直于平面的矢量,法矢量一般为单位矢量,可以通过它和平面上的一点来表示一个平面。
点积,又称为标量积、内积。两个矢量的点积结果是一个标量。它有下面两种计算方法

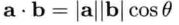
点积遵循的运算律:

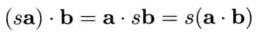
若b为单位矢量,则点积(a·b)表示在b方向定义的无限长直线上,a的投影的长度。

使用点积求矢量的模

点积的应用
- 共线:(a·b)= |a||b| = ab,即cosθ = 1,θ = 0o。则a、b共线。
- 共线且反向:(a·b)= |a||b| = -ab,即cosθ = -1,θ = 180o。则a、b共线,且反向。
- 垂直:(a·b)= 0,即cosθ = 0,θ = 90o。则a、b垂直。
- 同向:(a·b)> 0,即cosθ = > 0,θ < 90o。则a、b同向。
- 反向:(a·b)= 0,即cosθ = < 0,θ > 90o。则a、b反向。
- 任意一点到平面的高度:n为平面的法矢量,P为平面上一点,Q为平面外一点,则设v = P - Q,高度h = v·n
叉积,又称为矢量积、外积。叉积的结果仍然是一个矢量。它的计算方法如下:
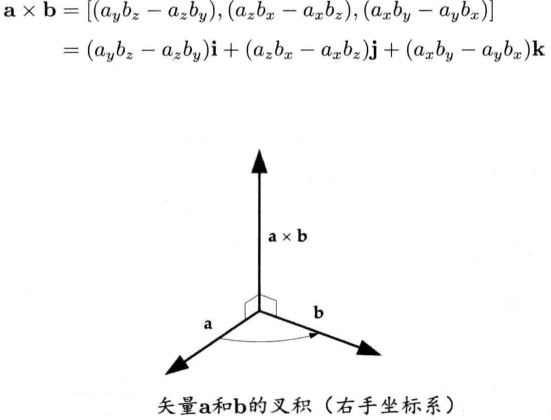
叉积的模
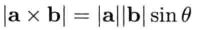
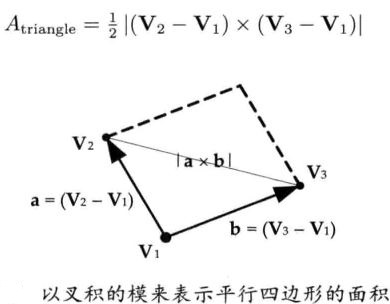
叉积可以表示三角形的面积
如果三角形的三个顶点分别是V1、V2、V3,则它的面积如下:
叉积遵循的规律
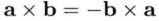

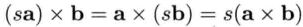
线性插值
线性插值(LERP)计算两个已知点的中间点,β表示0~1的范围之间的数。

矩阵
4x4矩阵可表示任意的三维变换,包括平移、旋转、放缩。平移、旋转、放缩组合的变换都是仿射矩阵。
所有仿射矩阵都有逆矩阵;标准正交阵的逆矩阵和转置矩阵相同。
齐次坐标
矢量在二维中的旋转
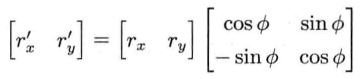
对应到三维空间,即表示三维中绕z轴旋转
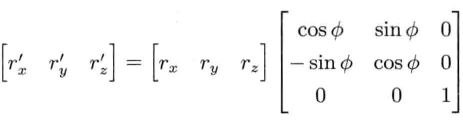
3x3矩阵的平移
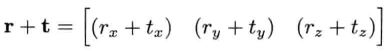
对3x3矩阵的平移,可以通过将三维延伸至四维来实现;下面的由于不需要旋转,所以前3x3的块是单位阵。

像这样将三维延伸至四维称为齐次坐标。
因此,如果希望求矢量v按照U旋转,在按照t平移的结果,可以这样计算:

基础变换矩阵
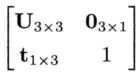
上面这4x4矩阵可由任意纯旋转、纯平移、纯缩放和旋转+平移串接而成,于是称它为基础变换矩阵。
U表示旋转及/或放缩;t表示平移;0 = [0 0 0]T;右下角的是标量1。
基础变换矩阵的最后一列必然是[0 0 0 1]T的矢量,因此,存储时,可以去掉它,存成4x3的仿射矩阵。
纯平移

缩写的形式如下
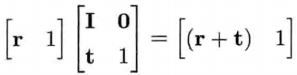
纯平移变换矩阵的逆矩阵,只需把t求反,即反转t中的正负号。
纯旋转的基础变换矩阵如下:
绕x轴旋转角度φ(从y到z)
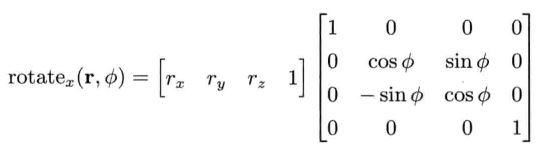
绕y轴旋转角度θ(注意绕y轴是从z到x)
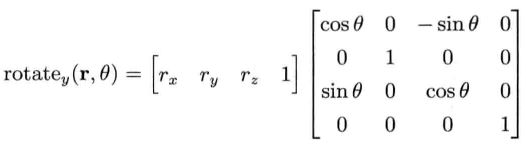
绕z轴旋转角度γ(从x到y)

纯旋转的逆矩阵,等同于用反向角度旋转,即将上面的θ变为-θ。也就是正弦求反,余弦不变。
缩放
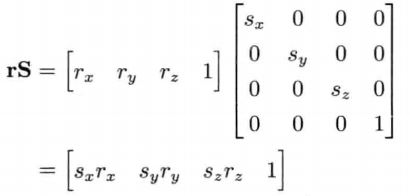
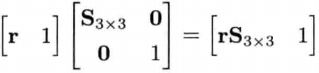
缩放的逆矩阵,只需要把Sx、Sy、Sz用它的倒数代替。
当Sx、Sy、Sz都相等时,它是统一缩放。
坐标空间:一组坐标轴表示一个参考系,每一个坐标系游戏界被称为坐标空间。
模型空间:又被称为物体空间或局部空间,它的原点位于物体中心。
世界空间:一个固定的坐标空间,游戏世界的所有物体的位置、定向、缩放都会用此空间的坐标表示。
观察空间:又称摄像机空间,固定于摄像机的坐标系,观察空间的原点在摄像机的焦点。
游戏世界的坐标空间是层次的,某个模型空间是另一个模型空间的父空间,而最终世界空间是游戏世界空间树的根。
某坐标空间A的点可以通过3x3矩阵M将其从空间A旋转到空间B,而它的法矢量可以使用M的逆转置矩阵(M-1)T做变换。因为,如果M中含非统一缩放或切变(M非正交),则平面和矢量间的夹角都用M矩阵变换后会改变。
四元数
上面提到用3x3矩阵表示旋转,但是旋转只有3个自由度,如何更高效的表示旋转呢?可以通过单位四元数q = [qx qy qz qw],且qx2 + qy2 + qz2 + qw2 = 1;
单位四元数中矢量部分qv是旋转的单位轴乘以旋转半角的正弦,标量部分qs是旋转半角的余弦。q = [qv qs] = [asin(θ/2) cos(θ/2)]
四元素乘法
四元素相乘仍是四元素
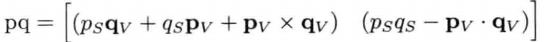
逆四元素
共轭的四元素q* = [-qv qs];逆四元素是q-1 = q*/(|q|2)。
而单位四元素满足|q| = qx2 + qy2 + qz2 + qw2 = 1;因此,q-1 = q* = [-qv qs]。
(pq)* = q*p* (pq)-1 = q-1p-1
四元素旋转矢量的计算
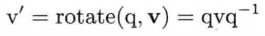
因为旋转用的四元素都是单位四元素,上式又可以写成下面形式

四元素和矩阵一样可以通过多个旋转四元素相乘串接旋转
设合成旋转四元素是qnet它的旋转矢量是v,则:

四元素和旋转矩阵的相互转换
任何三维旋转都可以用3x3矩阵R和四元素表示。若四元素q = [qv qs] = [qVx qVy qVz qs] = [x y z w],则:
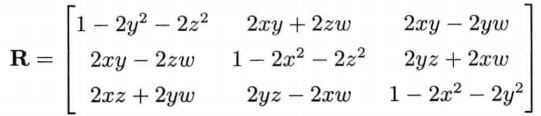
相对的如果已知R矩阵,如何转化为四元素q:
void matrixToQuaterion(const float R[3][3], float q[]){ float trace = R[0][0] + R[1][1] + R[2][2];//矩阵R的迹 if (trace > 0.0f){ float s = sqrt(trace + 1.0f); q[3] = s*0.5f; float t = 0.5f / s; q[0] = (R[2][1] - R[1][2])*t; q[1] = (R[0][2] - R[2][0])*t; q[2] = (R[1][0] - R[0][1])*t; } else{ int i = 0; if (R[1][1] > R[0][0])i = 1; if (R[2][2] > R[1][1])i = 2;//i为对角线上的最大元素下标 static const int next[3] = { 1, 2, 0 }; int j = next[i];//j为i的下一个位置模3 int k = next[j];//k为j的下一个位置模3 float s = sqrt((R[i][i] - (R[j][j] + R[k][k])) + 1.0f); q[i] = s*0.5f; float t; if (s != 0.0f)t = 0.5f / s; else t = s; q[3] = (R[k][j] - R[j][k])*t; q[j] = (R[j][i] + R[i][j])*t; q[k] = (R[k][i] + R[i][k])*t; } }
旋转性线性插值
给定两个旋转A和旋转B的四元素qA和qB,在两个旋转之间百分点β的地方插入中间旋转qLERP
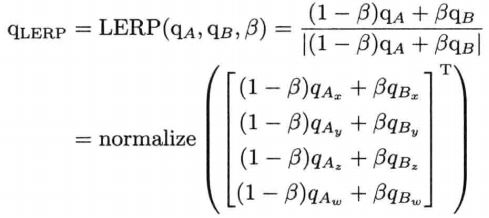
球面线性插值
LERP的线性插值当β以恒定速度变化时,旋转动画并非以恒定角速度进行。而球面上差值就能保证差值结果以常数角速率变化。
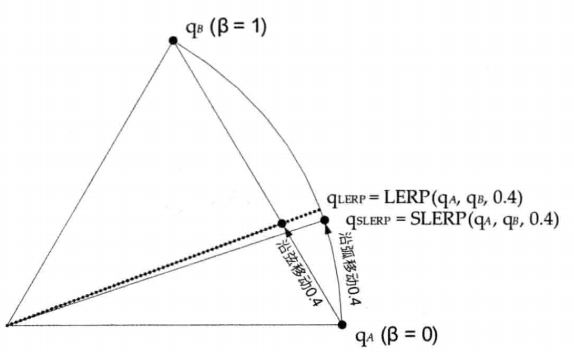
SLERP的计算公式
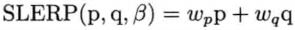
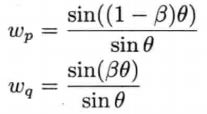 其中θ可以通过这样的方法计算:
其中θ可以通过这样的方法计算: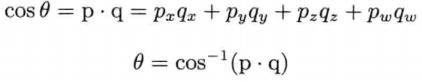
旋转表达方式
欧拉角:由3个标量值组成:偏航角、俯仰角、滚动角。[θγ θP θR]
- 优点:简单、直观、小巧、单轴旋转容易差值
- 缺点:任意方向的旋转轴,欧拉角不能轻易插值。有万向节死锁的问题(当旋转90o时,三主轴中的一个会与另一个主轴完全对齐,万向节死锁就会出现)。欧拉角的旋转依赖x/y/z轴和前、左右、上方向的映射。
3x3矩阵
- 优点:不受万向节死锁影响,可以独一无二的表达任意旋转。
- 缺点:旋转矩阵不太直观;旋转矩阵不容易插值。
轴角
一个以单位矢量定义的旋转轴,加上一个标量定义的旋转角,可以用来表示旋转。
优点:比较直观、紧凑
缺点:不能简单插值。
四元素
较于轴角优点:能够串接旋转,把旋转直接施于点和矢量,可以使用LERP和SLERP运算进行旋转插值。
SQT变换
在四元素的基础上结合平移矢量和缩放因子实现任意的仿射变换。

对偶四元素
旋转和自由度
自由度(degree of freedom,DOF)指物体有多少个相互独立的可变状态。
NDOF = N参数 - N约束
SIMD运算
游戏引擎中最常用的SSE模式为32位浮点数打包模式,此模式中,4个32位float值被打包进单个128位寄存器,单个指令可对4对浮点数进行并行运算。
visual studio编译器提供内建的__m128数据类型,使用该类型,编译器通常会把它置于SSE寄存器中。当__m128变量存到内存时,程序员需要确保该变量是16字节对齐的。
#include<iostream> #include<xmmintrin.h> using namespace std; __m128 addWithAssembly(__m128 a, __m128 b){ __m128 r; __asm{//内联汇编 movaps xmm0, xmmword ptr [a] movaps xmm1, xmmword ptr [b] addps xmm0 xmm1 movaps xmmword ptr [r], xmm0 } return r; } __m128 addWithIntrinsics(__m128 a, __m128 b){ __m128 r = _mm_add_ps(a, b); return r; } //16字节对齐 __declspec(align(16)) float A[] = { 2.0f, -1.0f, 3.0f, 4.0f }; __declspec(align(16)) float B[] = { -1.0f, 3.0f, 4.0f, 2.0f }; __declspec(align(16)) float C[] = { 0.0f, 0.0f, 0.0f, 0.0f }; __declspec(align(16)) float D[] = { 0.0f, 0.0f, 0.0f, 0.0f }; int _tmain(int argc, _TCHAR* argv[]) { //将以上浮点数据载入数组 __m128 a = _mm_load_ps(&A[0]); __m128 b = _mm_load_ps(&B[0]); __m128 c = addWithAssembly(a, b); __m128 d = addWithIntrinsics(a, b); //将a,b重新存回数组,确保没有改动 _mm_store_ps(&A[0], a); _mm_store_ps(&B[0], b); //将a,b重新存回数组,确保没有改动 _mm_store_ps(&C[0], c); _mm_store_ps(&D[0], d); cout << hex << A[0] << ' ' << A[1] << ' ' << A[2] << ' ' << A[3] << endl; cout << B[0] << ' ' << B[1] << ' ' << B[2] << ' ' << B[3] << endl; cout << C[0] << ' ' << C[1] << ' ' << C[2] << ' ' << C[3] << endl; cout << D[0] << ' ' << D[1] << ' ' << D[2] << ' ' << D[3] << dec << endl; system("pause"); return 0; }
SSE实现矩阵相乘
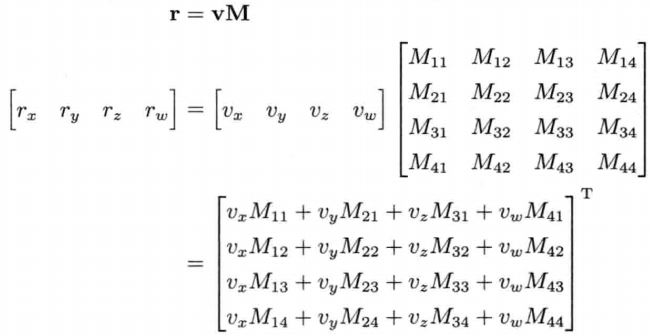
由于v乘以M的列向量时,得到的4个值存到一个SSE寄存器中,使它们相加不能使用SIMD;因此,应该以v乘以M的行向量;这样就需要把v的每个值扩充成4个存到SSE中。
#include<iostream> #include<xmmintrin.h> using namespace std; #define SHUFFLE_PARAM(x,y,z,w) ((x) | ((y) << 2) | ((z) << 4) | ((w) << 6)) #define _mm_replicate_x_ps(v) _mm_shuffle_ps((v),(v),SHUFFLE_PARAM(0,0,0,0)) #define _mm_replicate_y_ps(v) _mm_shuffle_ps((v),(v),SHUFFLE_PARAM(1,1,1,1)) #define _mm_replicate_z_ps(v) _mm_shuffle_ps((v),(v),SHUFFLE_PARAM(2,2,2,2)) #define _mm_replicate_w_ps(v) _mm_shuffle_ps((v),(v),SHUFFLE_PARAM(3,3,3,3)) __m128 mulVectorMatrixAttempt(__m128 v, __m128 Mrow1, __m128 Mrow2, __m128 Mrow3, __m128 Mrow4){ //v = [x,y,z,w]4个浮点数 __m128 xMrow1 = _mm_mul_ps(_mm_replicate_x_ps(v), Mrow1);//_mm_replicate_x_ps将v的x填充到一个SSE寄存器中,并和Mrow1逐位相乘 __m128 yMrow2 = _mm_mul_ps(_mm_replicate_y_ps(v), Mrow2);//(y,y,y,y)(M21,M22,M23,M24)T __m128 zMrow3 = _mm_mul_ps(_mm_replicate_z_ps(v), Mrow3);//(z,z,z,z)(M31,M32,M33,M34)T __m128 wMrow4 = _mm_mul_ps(_mm_replicate_w_ps(v), Mrow4);//(w,w,w,w)(M41,M42,M43,M44)T __m128 result = _mm_add_ps(xMrow1, yMrow2);//(VxM11 + VyM21,VxM12 + VyM22,VxM13 + VyM23,VxM14 + VyM24) result = _mm_add_ps(result, zMrow3); result = _mm_add_ps(result, wMrow4); return result; } __m128 mulVectorMatrixAttempt2(__m128 v, __m128 Mrow1, __m128 Mrow2, __m128 Mrow3, __m128 Mrow4){ __m128 result = _mm_mul_ps(_mm_replicate_x_ps(v), Mrow1); result = _mm_add_ps(_mm_mul_ps(_mm_replicate_y_ps(v), Mrow2), result); result = _mm_add_ps(_mm_mul_ps(_mm_replicate_z_ps(v), Mrow3), result); result = _mm_add_ps(_mm_mul_ps(_mm_replicate_w_ps(v), Mrow4), result); return result; }
产生随机数
随机数发生器:
线性同余发生器(LCG):给定相同的初始种子,则会产生相同的序列。具体参考《C数值算法(Numerical Recipes C)》
梅森旋转发生器(MT):很快、庞大的周期、高阶的分布维度。还有通过SIMD优化的SFMT:http://www.math.sci.hiroshima-u.ac.jp/~m-mat/MT/SFMT/index.html
Xorshift:http://www.jstatsoft.org/v08/il4/paper
随机性好于MT,运行速度优于所有伪随机数产生器之母(http://www.anger.org/random)。