ORBSLAM2回环检测简介
由于回环检测模块包含两个部分的内容:其一是位置识别,即外观验证,通过图像间的相似度信息进行判断;其二是几何验证,通过回环候选帧与当前关键帧的几何关系来做进一步验证。
由于两部分内容都较为繁琐,因此笔者将回环检测模块拆分成两讲,今天这一讲主要介绍外观验证,下一讲则继续几何验证。
外观验证,或者叫位置识别,实际上是一个图像检索的问题,即输入图像与地图存储的所有关键帧进行相似度比较,找出相似度分数最高的即是最优匹配。由于还有几何验证,因此在外观验证阶段,通常会留下几个相似度分数比较高的回环候选帧,以便几何验证选择最合适的回环帧。
这一讲,我们主要分下面几个部分来介绍外观验证:
1. 词袋模型;
2. 图像检索;
词袋模型
在讲图像匹配的时候,我们曾提及词袋模型,因为ORBSLAM2中的图像匹配用到的词袋模型,如果不稍微介绍一下,担心大家不太理解它们是怎么匹配的。值得注意的是,如何能保证高效且准确地找到正确匹配是一个检索问题的主要难题,而词袋模型基本上能满足这个要求。因此,本节将主要讲讲词袋模型,之后再利用词袋模型来介绍图像检索。
词袋的目的是用图像的某些特征来描述一幅图像。从我们人的直观感觉来看图像,我们会说这张照片里有一个人,一张桌子这些特征;而另一张照片里有一只狗,一张凳子和一张桌子等特征来描述。根据这些特征描述,我们就可以判断这两张图像的相似性了。如果我们将上述这些描述内容整合成字典,让他们形成一一映射的关系,比如:
$v_{1}$ 表示人,$v_{2}$ 表示桌子,$v_{3}$ 表示凳子,$v_{4}$ 表示狗。那么这字典的形式可以表示成 $D = [ v_{1}, v_{2}, v_{3}, v_{4} ]$。
而对于第一张照片,我们会表示成 $I_{1} = 1cdot v_{1} + 1cdot v_{2} + 0cdot v_{3} + 0cdot v_{4}$,于是我们就可以用一个向量来描述这个照片 $I_{1} = [ 1, 1, 0, 0 ]^{T}$;
同理,第二张照片表示成 $I_{2} = 0cdot v_{1} + 1cdot v_{2} + 1cdot v_{3} + 1cdot v_{4}$,描述成向量形式 $I_{2} = [ 0, 1, 1, 1 ]^{T}$。
对待这两个向量,我们可以设定度量方式,就能得到两张照片的相似度了。
在这里,我们提到了字典的概念,也用到了字典的方法,但是它是怎么定义的,怎么生成的?我们需要再稍微介绍一下。
----------字典------------
按照前面的介绍,字典是由很多单词组成,每一个单词代表一个概念。一个单词代表的不单单是一个特征点,他是一类具有相似性的特征的组合,或者更明确的说是它们的聚类中心。因此,字典的生成问题就类似于一个聚类问题。
聚类问题在无监督机器学习中非常常见,词袋模型主要使用经典的K-means算法来进行特征的聚类,假设有 $N$ 个特征点,我们需要将他分成 $k$ 类,下面的样本就表示特征点,具体流程如下:
1. 随机选取 $k$ 个中心点:$c_{1}, cdots, c_{k}$;
2. 对每个样本,计算它和每个中心点之间的距离,取最小的作为它的归类;
3. 重新计算每个类的中心点;
4. 如果每个中心点都变化很小,则算法收敛,退出;否则返回第2步。
但是在SLAM问题中,需要面对的场景非常多,特征的种类也非常多,如果只是非常笼统地将其分成几大类,这种做法显然是不够准确地。因此有学者提出了 $k$ 叉树的概念,类似于层次聚类,是K-means的直接拓展。同样,假设我们有 $N$ 个特征点,希望构建一个深度为 $d$,每次分叉为 $k$ 的树,那么做法如下:
1. 在根节点,即 $N$ 个特征点的集合,用K-means把所有样本聚成 $k$ 类,这样就得到了第一层;
2. 对第一层的每个节点,把属于把节点的样本再聚成 $k$ 类,得到下一层;
3. 以此类推,最后得到叶子层,叶子层即为所谓的词汇。
这些词汇就跟我们前面所讲的那个例子差不多,比如桌子只是其中一个词汇。当然,这里只是举例说明而已,这里的每一个词汇都是多个相似特征聚类而成的聚类中心,直接表征多个相似特征。更直观一些可以看下面这个图,尽管我们在图像匹配的时候看过,但是加上这里的描述,相信你可以更好地理解 $k$ 叉树是个什么东西。
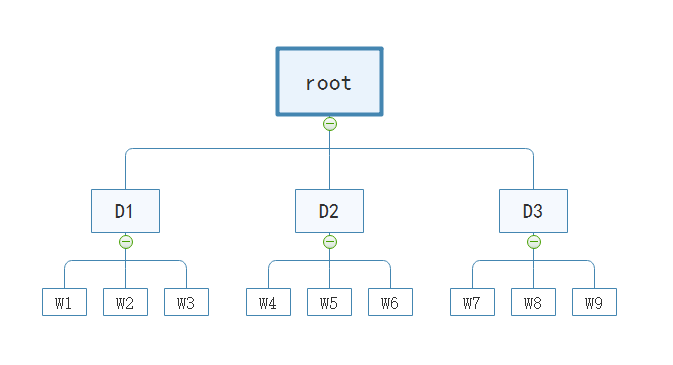
我们在叶子层构建了单词,树结构中的中间节点仅供快速查找时使用。实际上,我们构造了一个深度为2,3个分支的树,可以容纳 $3^{2}$ 个单词。我们可以通过增加树的深度和分支来增加字典的规模,达到更好的分类效果,这可以达到我们需要的准确率。此外,在检索时,一个特征会与逐层的中间节点的聚类中心比较,最终找到最优的匹配词汇,这个检索过程能达到对数级别的查找效率。
图像检索
在介绍了词袋模型这个工具以后,我们的图像检索问题就简单很多了。
检索问题的描述其实很简单:
输入一帧图像,和已有的数据库图像逐一对比,找到一个最合适的或者说匹配分数最高的图像。
笔者这里直接介绍ORBSLAM2的外观识别流程,因为它的意义是如此直观,只是在实现的时候加了一些小技巧,笔者将其罗列出来,以便大家参考:
1. 利用一范数来度量当前帧与共视图关键帧之间的相似度分数,假设共视图中一个关键帧的BOW向量为 $w$,当前帧的BOW向量为 $v$,则相似度分数的度量方式为:
$s(w-v) = 2sumlimits_{i=1}^{N}left|w_{i} ight| + left|v_{i} ight| - left|w_{i}-v_{i} ight|$
将所有相似分数进行排序,取最小的匹配分数 $S_{min}$ 作为参考值,用于查找回环候选帧。
2. 确定最小匹配分数后,排除当前帧共视图的所有关键帧,我们回环的意义是确定当前相机看到的场景,在很久之前是不是见过。而近期看到的,比如当前帧的共视图关键帧,我们通常是不考虑的,因为这对校正整个场景的误差,实际上作用不大。
3. 对当前帧的BOW向量中的词汇逐个逆向索引在地图中找到相关联的关键帧,参考下图。并统计各个关键帧中与当前帧相似的词汇数量。排序确定最大的相似词汇数量 $M$,并筛选相似词汇数量大于$0.8 imes M$的关键帧作为候选帧 $KF_{can}^{1}$;
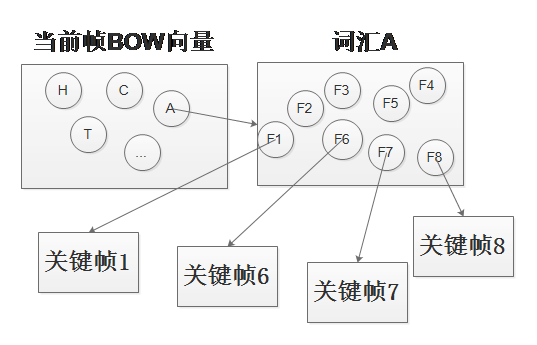
4. 将当前帧与步骤3的候选帧进行BOW向量计算匹配分数,取匹配分数高于步骤1计算的最小匹配分数 $S_{min}$的候选帧作为新的候选帧 $KF_{can}^{2}$;
5. 统计候选帧集中 $KF_{can}^{2}$ 每个候选帧的共视图关键帧与当前帧的BOW匹配分数总和 $S_{total}$,并取分数总和大于 $0.75 imes S_{total}$的候选帧组成新的候选帧 $KF_{can}^{3}$。笔者理解这也是为了确保在一个范围里都能检测到回环,增强回环的可靠性。
6. 在上述候选帧 $KF_{can}^{3}$ 的基础上,我们检测连续三帧都识别到同一个回环,那么就可以进一步缩小候选帧集,形成最终的候选帧集 $KF_{can}^{final}$ ,这在ORBSLAM2中叫一致性验证。
至此,我们的外观验证已经完成了。从步骤1开始到步骤6,ORBSLAM2都是在不断提高筛选条件进而缩小候选帧集。可以想见,这是在利用词袋模型检索和匹配效率极高的优势,快速完成粗检索,精细化的部分再交由几何验证去进一步确定最终的候选帧。
总结:
在这一讲中,我们概述了ORBSLAM2中采用的回环检测方法,并着重讲解了其中的外观验证方法,包括:
详细介绍了词袋模型的结构,以及生成方法;
详细罗列了ORBSLAM2中的视觉验证中所采用的检索方法;
下一讲,我们将继续回环检测方法中的另一部分——几何验证。
碎碎念:
笔者这种记录纲领的方法,在很多读者看来可能是一个记流水账的过程,十分枯燥。但是笔者还是同其他博主一样,优先写出对应模块的关键技术,再进一步分析ORBSLAM2中用这种关键技术,怎么样做优化,怎么样完成它想要完成的功能。
笔者认为这种列提纲的方式,可以帮助大家对这些细小的方法有一个清晰的认识。笔者之前就困惑于如何提高位置识别的准确性,而ORBSLAM2中这多种筛选方法可以给笔者提供多种参考方案。因此,笔者想传递给大家的也是这样一个信息,罗列提纲的方式可以为大家提供的是ORBSLAM2中某个模块采用的各种方法,读者可以根据实际需要选择提纲中的任意一个或多个组合的方法完成自己想要的功能。若是本文能对读者产生一两点帮助,那笔者将是十分欣慰的。
PS:
如果您觉得我的博客对您有所帮助,欢迎关注我的博客。此外,欢迎转载我的文章,但请注明出处链接。
对本文有任何问题可以在留言区进行评论,也可以在泡泡机器人论坛:http://paopaorobot.org/bbs/index.php?c=cate&fid=1中的SLAM技术交流模块发帖提问。
我的github链接是:https://github.com/yepeichu123/orbslam2_learn。