机器学习项目流程清单
这份列表可以让你学习到如何部署自己的机器学习项目。总共八个步骤:
-
首先你要有一个要解决的问题
-
获取解决问题需要的数据
-
探索数据,对数据有一个清楚的理解
-
预处理数据以便更好地输入给机器学习算法
-
探索不同的模型并且找到最好的那个
-
调整你的模型参数,并将这些参数组合成一个更好的解决方案
-
展示你的结果
-
对你的系统进行上线、监控和维护
-
规范化问题(抽象成数学问题):Frame the problem and look at the big picture
明确问题是进行机器学习的第一步。机器学习的训练过程通常都是一件非常耗时的事情,胡乱尝试时间成不是非常高的。
这里要先将问题抽象成数学问题,指的是我们明确我们可以获得什么样的数据,目标是一个分类还是回归或者是聚类的问题,如果都不是的话,划归为其中的某类问题。
-
用商业术语来定义你的目标
-
您的解决方案将如何使用?
-
如果有的话,目前的解决方案/方法是什么?
-
你如何规范化这个问题(有监督/无监督,在线/离线)?
-
模型的效果如何测量?
-
模型测量的指标是否与业务目标(原文为business objective)保持一致?
-
达到业务目标所需的最低模型性能是多少?
-
类似的问题有哪些? 你可以重复使用他们的经验或工具吗?
-
是不是人类专长的问题?
-
你如何人工手动解决这个问题?
-
列出目前为止,你或其他人所做出的假设
-
如果可能的话,验证假设
-
-
获取数据 Get the Data
数据决定了机器学习结果的上限,而算法只是尽可能逼近这个上限。
数据要有代表性,否则必然会过拟合。
而且对于分类问题,数据偏斜不能过于严重,不同类别的数据数量不要有数个数量级的差距。
而且还要对数据的量级有一个评估,多少个样本,多少个特征,可以估算出其对内存的消耗程度,判断训练过程中内存是否能够放得下。如果放不下就得考虑改进算法或者使用一些降维的技巧了。如果数据量实在太大,那就要考虑分布式了。
-
列出你需要的数据和你需要的数据量
-
查找并记录可以获取该数据的位置
-
检查这些数据需要多少空间
-
检查法律义务,并在必要时获得授权
-
获取访问权限
-
创建一个足够的存储空间的工作区(可以简单理解为计算机上的文件夹)
-
将数据转换为你可以轻松操作的格式(不要更改数据本身)
-
确保删除或保护敏感信息(例如:使用匿名)
-
检查数据的大小和类型
-
抽样出一个测试集,放在一边,不要管它
-
-
探索数据(explore the data)
-
为探索数据常见一份数据副本(如果需要,可将其抽样为可管理的大小)
-
在Jupyter notebook上以记录您的数据探索过程
-
研究每个属性及其特征
-
名字
-
类型:分类,int / float,有界/无界,文本,结构化等
-
丢失数据的百分比
-
噪音和噪音类型(随机,异常值,舍入误差等)
-
对任务的有用性
-
数据分布的类型(高斯分布,均匀分布,对数分布等)
-
-
对于有监督学习任务,确定标签值
-
可视化数据
-
研究样本属性之间的关系
-
思考如何手动解决这个问题
-
确定您可能想要应用的数据转换
-
确认可能有用的额外数据
-
将你学到的东西记录下来
-
-
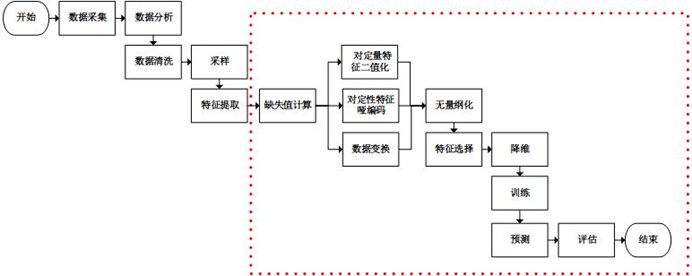
数据预处理(特征预处理与特征选择)
良好的数据要能够提取出良好的特征才能真正发挥效力。
特征预处理、数据清洗是很关键的步骤,往往能够使得算法的效果和性能得到显著提高。归一化、离散化、因子化、缺失值处理、去除共线性等,数据挖掘过程中很多时间就花在它们上面。这些工作简单可复制,收益稳定可预期,是机器学习的基础必备步骤。
筛选出显著特征、摒弃非显著特征,需要机器学习工程师反复理解业务。这对很多结果有决定性的影响。特征选择好了,非常简单的算法也能得出良好、稳定的结果。这需要运用特征有效性分析的相关技术,如相关系数、卡方检验、平均互信息、条件熵、后验概率、逻辑回归权重等方法。
-
数据清理
-
根据需要,修复或删除异常值
-
补全异常值(利用零、均值、中位数等)或者删除掉此行(或者列)
-
-
特征选择
1)删除对任务无用的属性
-
适当的特征工程
-
对连续特征离散化处理
-
分解特征(例如,分类,日期/时间等)
-
添加有希望的特征转换
-
将特征聚合成新的特征
-
-
特征缩放:对特征进行归一化或者标准化处理
-
注意:
在数据副本上进行处理(保持原始数据集的完整)
对所有数据转换的函数编写代码,原因有五:
可以在下次获取新数据集时轻松处理数据
可以在未来的项目中应用这些转换
对测试集进行预处理
在解决方案生效后清理并准备新的数据实例
轻松地将预处理选择作为超参数来处理
-
训练模型与调优
直到这一步才用到我们上面说的算法进行训练。现在很多算法都能够封装成黑盒供人使用。但是真正考验水平的是调整这些算法的(超)参数,使得结果变得更加优良。这需要我们对算法的原理有深入的理解。理解越深入,就越能发现问题的症结,提出良好的调优方案。
-
模型诊断
如何确定模型调优的方向与思路呢?这就需要对模型进行诊断的技术。
过拟合、欠拟合 判断是模型诊断中至关重要的一步。常见的方法如交叉验证,绘制学习曲线等。过拟合的基本调优思路是增加数据量,降低模型复杂度。欠拟合的基本调优思路是提高特征数量和质量,增加模型复杂度。
误差分析 也是机器学习至关重要的步骤。通过观察误差样本,全面分析误差产生误差的原因:是参数的问题还是算法选择的问题,是特征的问题还是数据本身的问题……
诊断后的模型需要进行调优,调优后的新模型需要重新进行诊断,这是一个反复迭代不断逼近的过程,需要不断地尝试, 进而达到最优状态。
-
模型融合
一般来说,模型融合后都能使得效果有一定提升。而且效果很好。
工程上,主要提升算法准确度的方法是分别在模型的前端(特征清洗和预处理,不同的采样模式)与后端(模型融合)上下功夫。因为他们比较标准可复制,效果比较稳定。而直接调参的工作不会很多,毕竟大量数据训练起来太慢了,而且效果难以保证。
- 记录下你所做的事情
-
创建一个不错的演示
- 确保首先突出重点。
- 解释您的解决方案为何能够达到业务目标
-
不要忘记提出你一路注意到的有趣观点
- 描述什么工作是有效的,什么没效
- 列出您的假设和模型系统的局限性
- 确保您关键的研究结果通过美观的可视化或易于记忆的陈述进行传达(例如,"收入中位数是房价的头号预测指标")
-
上限运行
这一部分内容主要跟工程实现的相关性比较大。工程上是结果导向,模型在线上运行的效果直接决定模型的成败。 不单纯包括其准确程度、误差等情况,还包括其运行的速度(时间复杂度)、资源消耗程度(空间复杂度)、稳定性是否可接受。
这些工作流程主要是工程实践上总结出的一些经验。并不是每个项目都包含完整的一个流程。这里的部分只是一个指导性的说明,只有大家自己多实践,多积累项目经验,才会有自己更深刻的认识。