概述
SUM()是一个聚合函数。在应用将影响公式的所有过滤器后,它会将您指定的单个列中的所有值相加。SUM()不知道行的存在(它不能逐行求值) - 它所能做的就是在应用过滤器之后将所有内容添加到它所呈现的单列中。
SUMX()是一个迭代器函数。它应用于一个表,一行一行地应用所有过滤器后完成求值。 SUMX()具有表中行的感知,因此可以引用每行与表中任何列的交集。SUMX()可以在单个列上运行,但也可以在多个列上运行 - 因为它具有逐行工作的能力。
综上所述
·SUM()在单个列上运行,并且不知道列中的各个行(没有逐行求值)。
·SUMX()可以对表中的多个列进行操作,并且可以在这些列中完成逐行求值。
这两个功能可以最终给你同样的结果(也许是,也许不是)。它们通常在矩阵给出相同的结果,但通常在视觉的子总数和总计部分中给出不同的结果。
SUM()函数
语法:= SUM(<列名>)
示例:总销售额= SUM(销售表[销售额])
SUM()函数在单个数据列上运行,以聚合该单个列中的所有数据并应用当前过滤器 - 首先过滤,然后评估第二个。
SUMX()函数
语法:= SUMX(<Table>,<expression>)
示例:总销售额SUMX = SUMX(销售表,销售表[数量] *销售表[单位价格])
SUMX()将迭代第一个参数中指定的表,一次一行,并完成第二个参数中指定的计算,例如数量x单位价格,如上例所示,当前过滤器已应用(即仍然首先过滤,求值第二)。一旦它对指定表中的每一行(在应用当前过滤器之后)完成此操作,它就会累计所有逐行计算的总和以获得总计。结果返回此总数。
那么我应该使用哪一个呢?
您使用哪种方式取决于您的个人偏好和数据结构。我们来看几个例子。
1数量和每单位价格
2延期金额
3总计不要加起来
1.数量和价格
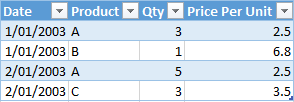
如果您的销售表包含数量列和“单价”的另一列(如上所示),那么您必须将“数量”乘以“单价”以便获得总销售额。将总量SUM(数量)加起来并将其乘以平均单价是不合适的,因为这将给出错误的答案。
如果您的数据以这种方式构建(如上图所示),那么您只需要使用SUMX() - 这就是迭代器函数的设计目的。这是公式的样子。
总销售额1 = SUMX(销售表,销售表[数量] *销售表[单价])
2.延期金额
如果您的数据包含具有该行项目的扩展总销售额的单个列(即,它没有每单位的数量和价格),则可以使用 SUM()来累加值。

总销售额2 = SUM(销售表[销售额])
在此示例中不需要迭代器,因为在这种情况下,它只是跨单个列的简单计算,并且不需要逐行执行。但请注意,你仍然可以使用SUMX()(如下所示),它会给你相同的答案。
总销售额2替代= SUMX(销售表,销售表[销售额])
并且使用SUMX()的替代公式在性能和效率上与SUM()是相同的.
3.总计不要加起来
当你必须使用不那么明显的SUMX()时,还有另一个用例。当您遇到总计不按需要/期望加起来的问题时,您将需要使用像SUMX这样的迭代器来纠正问题。我已经创建了一个小样本数据表来解释。
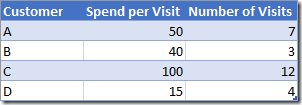
上表显示了4位客户,他们每次购物时平均花费的金额以及他们购物的次数。如果我将这些数据加载到Power BI中,然后尝试使用聚合器函数来查找所有客户的平均支出以及花费的总金额,我会在总行中得到错误的答案(如下所示)。
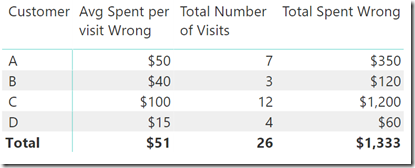
以下是上述措施:
总访问次数= SUM(购物表[访问次数]) - 该公式的总数是正确的。
每次访问平均花费=AVERAGE(购物表 [每次访问花费]) - 这里的总数是错误的。
总支出= [每次访问费用] * [访问总次数] - 这里的总数也是错误的。
第一个度量[访问总数]是正确的,因为数据是加性的,但其他2个度量给出了错误的结果。这是一个典型的情况,你无法在总体水平上对平均值进行乘法运算。鉴于我开始使用的样本数据,计算正确答案的唯一方法是为表中的每个客户完成逐行评估,如下所示。
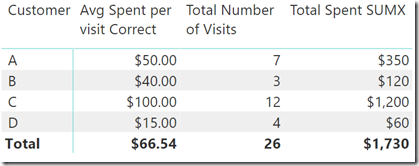
在上面的第二个表中,我编写了一个SUMX()来首先创建Total Spent SUMX(逐行)。只有这样我才能计算每次访问的平均花费作为最终公式。
总访问次数= SUM(购物表[访问次数])
总花费= SUMX(购物表,购物表 [每次访问花费] *购物表[访问次数])
每次访问平均花费= DIVIDE([总花费SUMX], [总访问量])
在第二种情况下,SUMX正在一次一行地处理数据表并正确计算结果,即使对于表底部的总行也是如此。
性能影响存储引擎
我要谈的最后一件事是使用SUM与SUMX的性能影响。鉴于SUMX是一个迭代器,您可能认为SUMX本质上是低效的。一般来说,这不是真的,因为软件已经过优化以有效地处理场景。话虽如此,糟糕的DAX肯定会导致SUMX效率低下。
Power Pivot有2个计算引擎,存储引擎(SE)和公式引擎(FE)。SE更快,多线程和缓存。FE速度较慢,单线程且未缓存。这本身就是一个复杂的主题,我将只讨论表面,但其含义是您应该编写公式以尽可能利用SE。当然,如果您不确切知道如何做到这一点,这可能很难,但有一些简单的提示可以帮助您。
1.SUM()总是使用SE进行计算,因此无需担心。
2.对于大多数简单的计算(如Sales [数量] *销售[单位价格]),SUMX()也将使用SE,所以那里都很好。
3.在某些情况下,SUMX()可以使用FE执行部分或全部计算,特别是如果公式中有复杂的比较语句。如果SUMX需要使用FE,那么性能可能会很慢 - 有时非常慢。
关于第3点,最好建议是避免在SUMX函数中编写复杂的条件语句,如“IF语句”。考虑以下两个公式:
物品总销售额超过100美元
= SUMX(销售,
IF(销售[ExtendedAmount]> 100,销售[ExtendedAmount])
)
物品总销售额超过100美元
=CALCULATE
(
SUMX(销售,销售[ExtendedAmount]),
销售[ExtendedAmount]> 100
)
第一个公式(Bad)在SUMX中有一个IF语句。此IF语句强制存储引擎将求值任务传递给公式引擎以进行比较检查,以确定每个单独的行是否大于100,然后再决定是否将其包括在计算中。因此,公式引擎必须一次完成一行任务,使评估变得缓慢且低效。
第二个公式(Good)首先使用CALCULATE()修改来自visual的初始过滤器,以在Sales [ExtendedAmount]> 100上添加额外的过滤器。这个新过滤器由存储引擎非常有效地应用。在CALCULATE()修改过滤器之后,SUMX()可以完成其工作,即使用存储引擎(而不是公式引擎)应用新的过滤器集合来添加剩余的行。结果,这第二个公式非常有效。在我完成的一些简单测试中,第一个(坏)公式比第二个(好)公式慢了5倍。在其他情况下,它可能会慢100或甚至1000倍,所以这显然可能是一个问题。
压缩对性能的影响
可影响性能的第二个领域是整体数据模型压缩。数据模型中的列中存在的唯一值越多,数据的压缩程度就越低。数据压缩得越少,所需的内存就越多,计算速度就越慢。让我们再看一下本文前面的表格。
示例表1
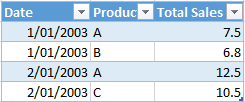
示例表1[Total Sales]数据列具有所有唯一值。此列不能很好地压缩。
示例表2
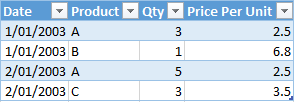
在此表中,Qty列中还有重复值,还有每单位价格列。列中的唯一值越少,压缩越好。
当然,这两个样本表当然非常小,但想象一下这个概念对非常大的表(例如具有数百万行数据的表)的影响。对于非常大的表,示例表1中的唯一值的数量可能远远大于示例表2中的列中的唯一值的数量。因此,如示例2中所述的加载数据可能具有对总表大小产生积极影响,从而影响数据模型的性能。做出改变当然可能意味着你必须交换你的措施:
SUM(销售[总销售额])
至
SUMX(销售,销售[数量] *销售[单位价格])
SUMX比起SUM的这种用法非常精细并且有更高的性能。
1.Power BI免费下载:http://www.yeacer.com/
Microsoft Power BI Desktop中文最新版:下载地址
2.欢迎加入的Power BI技术群,目前正在学习阶段,有兴趣的朋友可以一起学习讨论。
Power Data技术交流群:702966126 (验证注明:博客园Power BI)
更多精彩内容请关注微信公众号:悦策PowerBI
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!欢迎各位转载,作者博客:https://www.cnblogs.com/yeacer/