导语:为什么用pandas绘图
matplotlib虽然功能强大,但是matplotlib相对而言较为底层,画图时步骤较为繁琐,比较麻烦,因为要画一张完整的图表,需要实现很多的基本组件,比如图像类型、刻度、标题、图例、注解等等。目前有很多的开源框架所实现的绘图功能是基于matplotlib的,pandas便是其中之一,对于pandas数据,直接使用pandas本身实现的绘图方法比matplotlib更加方便简单。
pandas的两类基本数据结构series和dataframe都提供了一个统一的接口plot(),即data.plot()或者data.plot.bar/box...即可。
kind:画图的种类,可以是 line(默认)、bar、barh、kde。
- ‘bar’ or ‘barh’ for bar plots,bar表示垂直柱状图,barh表示水平柱状图
- ‘hist’ for histogram
- ‘box’ for boxplot
- ‘kde’ or ‘density’ for density plots。即Kernel Density Estimate 和密度估计,常常与hist一起混合使用。
- ‘area’ for area plots
- ‘scatter’ for scatter plots
- ‘hexbin’ for hexagonal bin plots
- ‘pie’ for pie plots
- kind:“line”、"bar"、"barh"、"kde"
- ax:要在其上进行绘制的matplotlib.subplot对象,如果没有,则使用默认的subplot对象。
- figsize:图像尺寸
- use_index:True(默认),False。表示默认情况下,会将series和dataframe的index传给matplotlib,用已绘制X轴。
- title:标题
- grid:网格
- legend:图例
- style:绘图的风格,如‘ko--’
- logx:在X轴上使用对数标尺
- logy: 在Y轴上使用对数标尺
- loglog:
- xticks=None,用做x刻度的值
- yticks=None,用做Y轴刻度的值
- xlim=None, X轴的界限如【0,10】
- ylim=None,Y轴的界限
- rot=None, 旋转刻度标签 0-360
- fontsize=None,
- colormap=None,
- table=False,
- yerr=None,
- xerr=None,
- label=None,
注:pandas绘图时会默认索引作为x轴
导入数据
1 import matplotlib.pyplot as plt 2 %matplotlib inline 3 plt.rcParams['font.sans-serif'] = ['SimHei']#显示中文 4 plt.rcParams['axes.unicode_minus'] = False#显示负号 5 import pandas as pd 6 import numpy as np 7 from pandas import Series,DataFrame 8 test=pd.read_excel("/Users/yaozhilin/Downloads/exercise.xlsx",sep="t") 9 test.head(5)#显示前五行

•离散型数据的可视化
~饼图
1 fig= plt.figure(figsize=(6,6))#调整图的大小 2 t=test["所属区域"].value_counts() 3 t.plot.pie(autopct='%.1f%%',explode = [0,0.1,0,0])

比较matplotlib:
1 plt.pie(t.values,labels=t.index,autopct='%.1f%%',explode = [0,0.1,0,0])
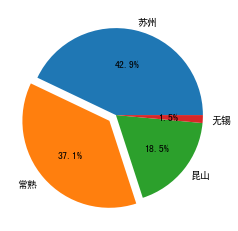
相比pandas默认索引为labels,values为数值。
~条形图
1 fig=plt.figure(figsize=(7,7)) 2 tb=test.groupby(["所属区域"]).agg({"数量":np.mean}) 3 tb.plot(kind="bar") 4 plt.grid(linestyle="-.", axis='y', alpha=0.4)#设置横向网格

双条形图
1 fig=plt.figure(figsize=(7,7)) 2 tb=test.groupby(["所属区域"]).agg({"成本":np.mean,"金额":np.mean}) 3 tb.plot(kind="barh")
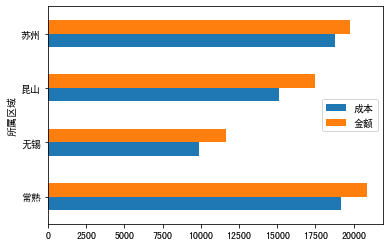
堆积图
data.plot(kind="barh",stacked=True)
1 fig=plt.figure(figsize=(7,7)) 2 tb=test.groupby(["所属区域"]).agg({"成本":np.mean,"金额":np.mean}) 3 tb.plot(kind="barh",stacked=True) 4 plt.grid(linestyle="-.", axis='y', alpha=0.4)#设置横向网格

•连续性数据的可视化
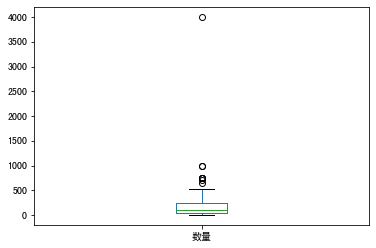
~箱型图
常用于数据清洗查看异常值
1 t=test["数量"].dropna()#切记要去除na 2 t.plot(kind="box")
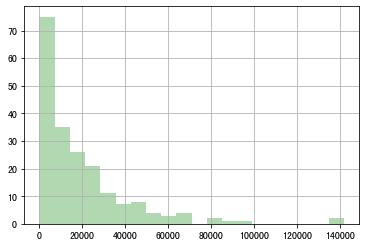
~直方图:data.hist(bin=)
计算连续变量的频率
1 test["金额"].hist(bins=20,alpha=0.3,color='g')#bins表示x分为多少份
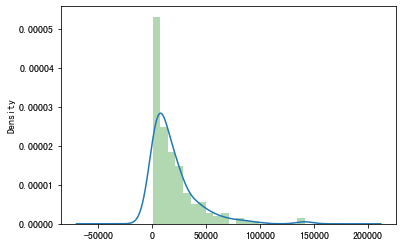
~密度图:kde
1 test["金额"].hist(bins=20,alpha=0.3,color='g',density=True) 2 test["金额"].plot(kind="kde")
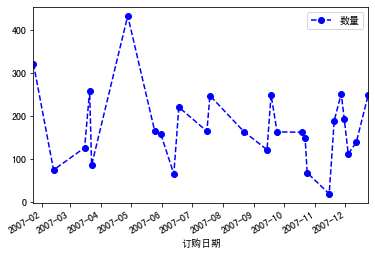
~折线图
常用于随时间变化的连续数据
比如探究test中数量随时间变化趋势
1 tl=test.groupby("订购日期").agg({"数量":np.mean}) 2 tl.plot(kind="line",style="bo--")
~面积图 :data.plot.area
1 fig,axes=plt.subplots(1,2) 2 ta=test.groupby(["订购日期"]).agg({"成本":np.mean,"金额":np.mean}) 3 ta.plot(ax=axes[0])#第一个画布 4 ta=test.groupby(["订购日期"]).agg({"成本":np.mean,"金额":np.mean}) 5 ta.plot.area(ax=axes[1])

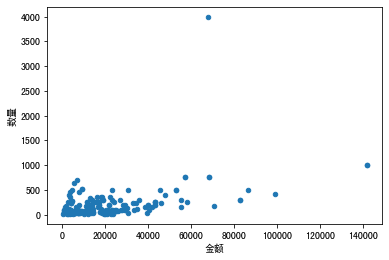
•关系型数据的可视化
~散点图:data.plot.scatter
1 test.plot.scatter(x="金额",y="数量")