纸上得来终觉浅,绝知此事要躬行。
Redis复制
- 建立连接
- 同步
- 命令传播
建立连接
通过向从服务器发送SALVEOF命令,我们可以让一个从服务器去复制一个主服务器:
slaveof <master_ip> <master_port>
例如一个从服务器127.0.0.1:6380接受我们发送的命令salveof 127.0.0.1 6379,就表示6380这个从服务器连接6379主服务器进行复制,如图所示:

步骤一:设置主服务器的地址和端口
SLAVEOF是一个异步命令,在执行完毕之后会从服务器把主服务器的ip和port保存到服务器状态。然后返回OK,表示复制命令已经被接受,而实际的复制工作将在OK返回之后才真正开始执行。再返回Ok之前仍需要一下几个步骤。
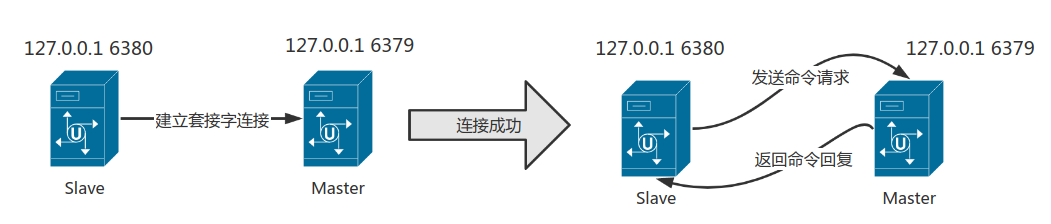
步骤二:建立套接字连接
在SALVEOF命令执行之后,从服务器将根据命令所设置的ip和port创建套接字连接,那么从服务器将为这个套接字关联一个专门用于处理复制工作的文件事件处理器,负责后续的复制工作,比如接受RDB文件以及接受主服务器发送的写命令等。
而主服务器与从服务器建立套接字连接,从而充当是从服务的服务器,就是向从服务器返回命令回复。过程如图所示:
步骤三:发送PING命令
建立套接字连接之后,从服务器第一件事就是向主服务器发送PING命令,主要有两个作用:
- 初次建立连接,通过PING命令来检查套接字的读写状态时候正常。
- 在之后的复制过程中,通过PING检查主服务器能否正常处理命令请求。
当发送的PING命令,从服务器接受到主服务器返回的PONG则表示网络连接正常,当然发送PING命令也会出现的异常情况:
- 在从服务器向主服务器发送PING命令可能会接受到主服务器一个的错误回复
- 从服务器未能在规定时间发送PING命令给主服务器
对于以上的错误情况,从服务器将会断开重新连接主服务器。过程如图所示:

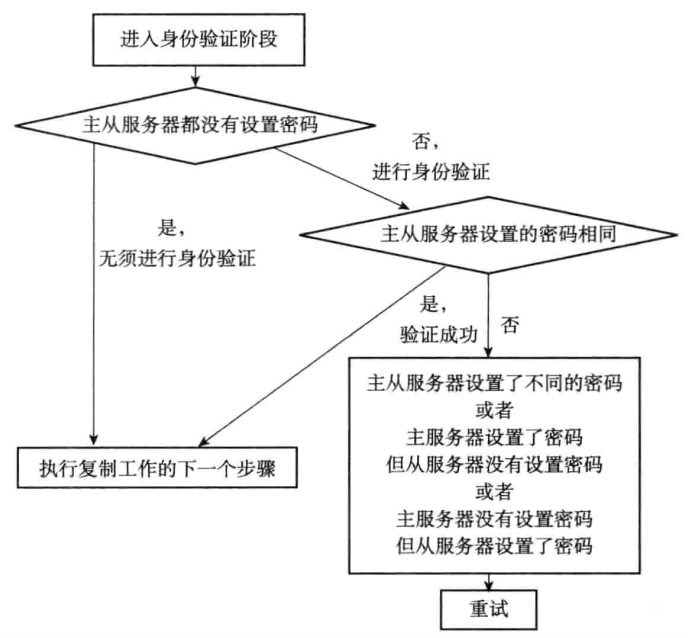
步骤四:身份验证
从服务器接受到主服务器返回的PONG之后,下一步要做的就是决定是否进行身份验证。如果从服务器设置了masterauth选项,则进行身份验证,否则不需要。
在需要身份认证的情况下,从服务器将向主服务器发送一条auth password命令,从服务器在身份验证阶段可能遇到多种情况:
- 主服务器没有设置
requirepass,从服务器没有设置masterauth,则不需要验证 - 主服务器设置了
requirepass,从服务器设置了masterauth,且二者相同,验证通过 - 任意一方服务器设置另一方不设置,又或者都设置了但是值不相同,这验证失败
以上情况如流程图所示:
步骤五:发送端口信息
验证通过以后,从服务器将执行命令REPLCONF listening-port <port>,例如:REPLCONF listening-port 6380,将从服务器自己的端口发送给主服务器,主服务器接受到之后会将端口记录在从服务器谁对应的客户端状态中。通过info relication可以查看。
以上的步骤就是从服务器与主服务器建立连接的整个过程,总结如下图所示:

同步
通过上面发送SLAVEOF命令建立连接之后,表示要求从服务器开始复制主服务器,首先从服务器需要先执行同步操作,也就是,将从服务器的数据库状态更新至主服务器当前的状态。
步骤如下:
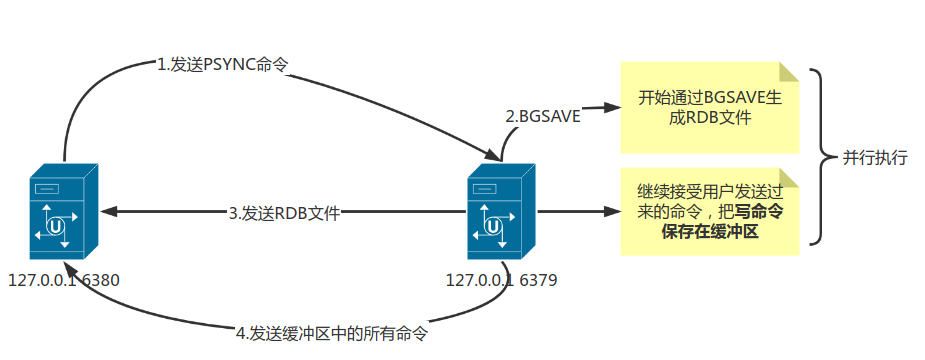
- 从服务器对主服务器发送
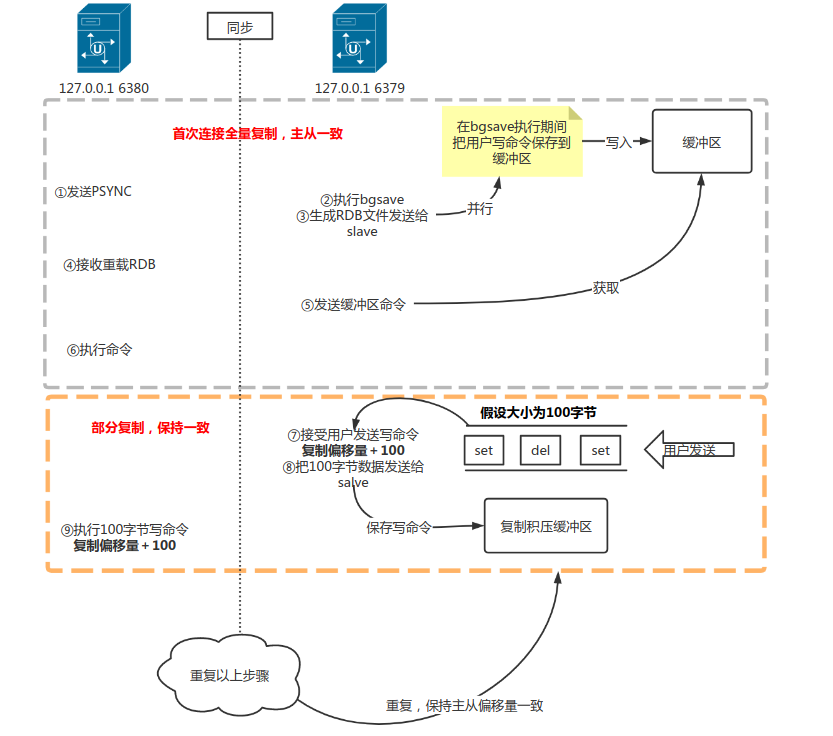
PSYNC命令 - 主服务器接受到命令执行
BGSAVE命令,在后台生成一个RDB文件,在生成RDB文件期间主服务器接收到的所有写命令将会保存在一个缓冲区。 - 主服务器
BGSAVE执行完毕,主服务器通过之间建立的套接字连接将RDB文件发送给从服务器,从服务接受并载入这个RDB文件,将数据库状态更新为主服务器执行BGSAVE命令时的数据库状态。 - 之后主服务器会将记录在缓冲区里面的所有写命令发送给从服务器,从服务器执行这些写命令,更新数据库状态。
如图展示了PSYNC命令执行期间,主从服务器通信过程:
扩展:老版本Redis采用的是
SYNC命令完成复制的同步操作,主要存在功能缺陷,例如:主从服务器之间断线后需要全量重新复制,也就是无法实现断点续传类似的功能,导致主服务器重新生成RDB文件会消耗大量CPU资源、IO资源以及发送给从服务器的RDB文件消耗带宽。而从服务器在重载新的RDB文件时,可能文件过大而导致服务器阻塞无法处理其他命令请求。所以Redis2.8之后使用PSYNC命令替代SYNC来执行复制时的同步操作。目前好像有了PSYNC2
命令传播
在同步操作完成之后,主从服务器两者的数据库达到一致状态,但是这种一致状态不是一成不变的,每当主服务器执行用户发送的写命令时,主服务器可能会修改,并导致主从服务器状态不一致。
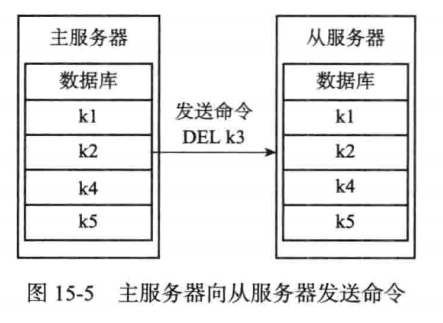
例如:主服务器接受到用户发送发送过来的删除命令DEL k3,那么主服务器执行完毕之后,主从服务器数据库之间出现不一致,过程如图所示:

为了解决主从服务器再次回到一致状态,主服务器需要对从服务器执行命令传播:也就是把自己执行的写命令,更具体就是造成主从服务器不一致的写命令,发送给从服务器去执行,当从服务器执行完毕之后,主从服务器又回到一致状态。如图所示。
这一步骤称为部分重同步,有点类似断点续传的意思。
部分重同步实现
部分重同步由一下三个部分组成:
- 主服务器的复制偏移量和从服务器的复制偏移量
- 主服务器的复制积压缓冲区
- 审核服务器的运行ID
复制偏移量
主从复制服务器双方分别维护这一个复制偏移量,比如:
主服务每次向从服务器发送1000个字节的数据,就在自己的复制偏移量加上1000,同时从服务器接收到1000个字节数据时,也将自己的复制偏移量加上1000,过程如图所示。
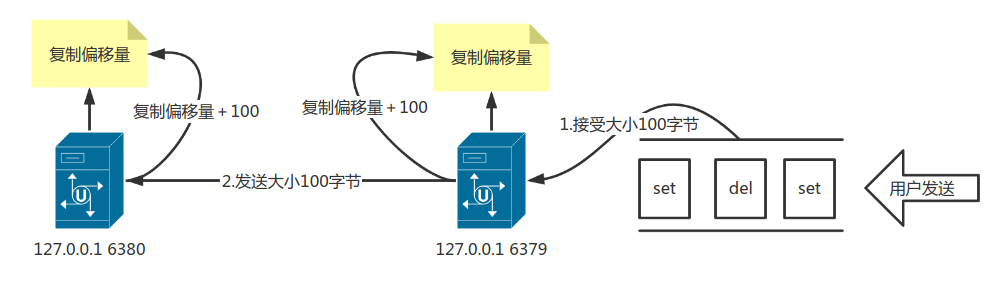
也就是说如果主从服务器的复制偏移量大小不一致,则主从服务器复制并不一致。
可能会出现某种情况:假设当前主从服务器的的偏移量都是1000,但是由于从服务处于断线状态,而此时主服务接受到写命令100字节,那么主服务器的复制偏移量就成为了1100,而从服务器仍然停留在1000,就导致了主从服务器不一致问题。
当从服务器断线之后就立即重新连接主服务器,并且连接成功,那么接下来,从服务器将会向主服务器发送PSYNC命令给主服务,那么此时有两种情况:
- 全量复制
- 部分复制
至于选择那种,就需要根据复制积压缓冲区的大小来做判断。
复制积压缓冲区
复制积压缓冲区是由主服务器维护的一个固定长度的队列,默认大小1MB。
意思就是当主服务器接受到用户发送的命令,不仅会通过命令传播发送命令给从服务器,还会将写命令写入到复制积压黄缓冲区的队列当中,如图所示。
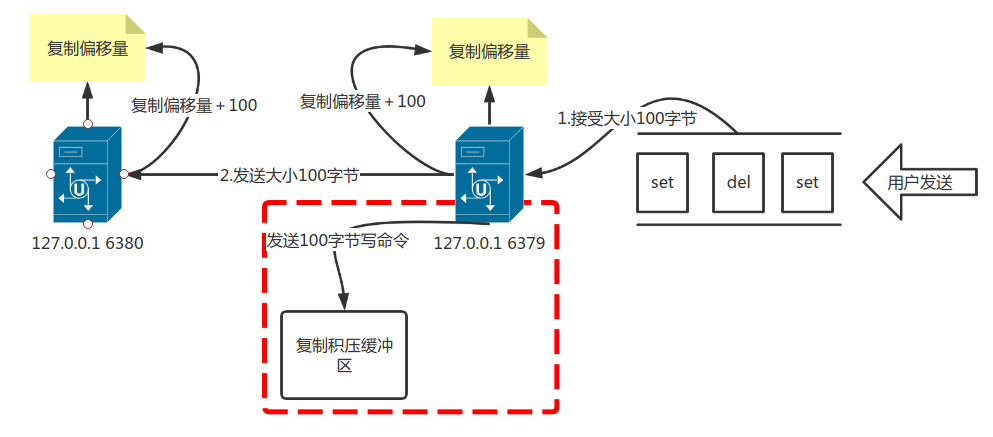
复制积压缓冲区是一个队列,也就是说当队列满了之后,后面的命令入队,对头的命令就要出队,也就是总是保存这最新传播的写命令,并且复制积压缓冲区回味队列中每一个直接记录相应的复制偏移量。
当从服务重新连接上主服务器后,从服务器会通过PSYNC,命令将自己的复制偏移量发送给主服务器,主服务器根据这个复制偏移量来决定对应操作:
- 如果偏移量之后的数据存在于复制积压缓冲区,那么主服务器舰队从服务器执行部分复制
- 相反,不存在复制积压缓冲区,那么将进行全量复制。
所以在实际应用场景中需要合理的调整复制积压缓冲区的大小,这样可以降低断线后全量复制的可能性。
服务器运行ID
除了复制偏移量和复制积压缓冲区之外,实现部分重同步,还会用到服务器运行ID。
每个Redis服务器都有一个自己唯一的运行ID,进行初次复制,主服务器会将自己的ID发送给从服务器进行保存。而从服务器在断线重新连接主服务器会将自己之前保存的运行ID发送给现在连接的主服务器。通过判断ID是否相同,来判断是否连接同一台主服务器,从而区分需要重新执行全量复制还是部分复制。
同步过程总结,如图所示。
相关参考:
http://www.redis.cn/topics/replication.html
Redi设计与实现