宜未雨而绸缪,毋临渴而掘井
Python基础
什么是Python?
至于Python到底是什么,说实话突然问你可能会说:Python是一种解释性语言,含有丰富的模块和库,应用于数据处理、数据分析、Web开发、爬虫以及人工智能各个领域,同时Python相对其他语言简单,而且完全面向对象,所谓Python一切皆对象,Python又号称胶水语言,它可以采用 C 或 C ++ 来进行扩展。最后Python是跨平台的,可以在各种操作系统运行。
接着我们看一下官方是怎么定义的:
Python 是一种解释性、交互式、面向对象的编程语言。 它包含了模块、异常、动态类型、非常高层级的动态数据类型以及类的概念。 Python结合了超强的功能和极清晰的语法。 它带有许多系统调用和库以及各种窗口系统的接口,并且可以用 C 或 C ++ 来进行扩展。 它还可用作需要可编程接口的应用程序的扩展语言。 最后,Python 还是可移植的:它可以在许多 Unix 变种、Mac 以及 Windows 2000 以上的操作系统中运行。
Python函数调用时参数传递是按值传递还是按照引用传递?
对于这个问题争论很多,姑且这么理解。参数的传递分为可变对象和不可变对象:
- 不可变参数用值传递
def func(a):
print(id(a)) # 9085376
a = a + 100
print(id(a)) # 140501750383952
print(id(300)) # 140501750383952
a = 200
print(id(a)) # 9085376
print(id(200)) # 9085376
func(a)
print(id(a)) # 9085376
通过代码可以发现,可以看到,在执行完a = a + 100之后,a引用中保存的值,即内存地址发生变化,由原来200对象的所在的地址变成了300这个实体对象的内存地址。
- 可变参数是引用传递
a = []
def fun(a):
print((id(a))) # 140215362068680
a.append(1)
# a = [] 赋值会改变地址
# print(a) # 140469919166728
print(id(a)) # 140215362068680
print(id(a)) # 140215362068680
fun(a)
print(a) # [1]
print(id(a)) # 140215362068680
而对于可变对象列表,在执行a.append(1)之后,a引用保存的内存值就不会发生改变,但是当我们使用赋值a=[]相当于重新创建一个变量,而外部的a不受影响
@staticmethod和@classmethod区别
- 定义区别
class Demo(object):
age = 20
def __init__(self):
self.name = "ydongy"
@staticmethod
def this_static_method():
print("this is a static method")
@classmethod
def this_class_method(cls):
print(cls.age) # 20
cls.age=30 # 修改类变量
print(cls.age) # 30
print("this is a class method")
if __name__ == "__main__":
Demo.this_static_method()
Demo.this_class_method()
d = Demo()
print(d.age) # 30
print(Demo.age) # 30
代码是一个Demo类实现了两个方法,一个方法被@staticmethod装饰器装饰即:静态方法,另一个方法被@classmethod装饰器装饰即:类方法
- 用法区别
- 静态方法:可以不用传递参数,通过类名可这直接调用,相当于普通函数
- 类方法:必须有
cls参数,这个参数指向当前类,可以修改当前类状态(比如:类变量),同样可以通过类名直接调用
类变量和实例变量区别
- 类变量:可以使类的所有实例共享,但是当实例对类变量进行修改时,实际是给实例增加了新的变量,而不会修改类变量。例如以下代码示例:
class Demo(object):
age = 20
def __init__(self):
self.name = "ydongy"
if __name__ == '__main__':
d = Demo()
print(d.age) # 20
d.age = 30 # 注意:这里并不是修改类变量age,而是给实例d增加了一个age属性,通过d.__dict__可以查看
print(d.__dict__) # {'name': 'ydongy', 'age': 30}
print(d.age) # 30
print(Demo.age) # 20
- 实例变量:类实例化后,每个实例单独拥有的变量。
Python中的单下划线和双下划线区别
__foo__:这是Python的一种内部约定,为了防止与用户自定义命名冲突,这一类的函数称为魔法函数。_foo:这是一种编程规范,表示这是一个私有变量或方法,不想被类的外部访问(本质是可以访问的),但是不能用from module import *导入,其他方面和公有函数一样访问;__foo:这是"真正意义"上的私有,只不过是Python的小把戏,把名字换成了_类名__foo的形式,使其无法像成员变量和方法一样访问
新式类和旧式类区别
- 新式类都从object继承,经典类不需要。
- 新式类的MRO(method resolution order 基类搜索顺序)算法采用C3算法广度优先搜索,而旧式类的MRO算法是采用深度优先搜索
- 新式类相同父类只执行一次构造函数,经典类重复执行多次。
Python中的作用域
Python 中,一个变量的作用域总是由在代码中被赋值的地方所决定。
有四种作用域:
- L(Local):最内层,包含局部变量,比如一个函数/方法内部。
- E(Enclosing):包含了非局部(non-local)也非全局(non-global)的变量。比如两个嵌套函数,一个函数(或类) A 里面又包含了一个函数 B ,那么对于 B 中的名称来说 A 中的作用域就为 nonlocal。
- G(Global):当前脚本的最外层,比如当前模块的全局变量。
- B(Built-in): 包含了内建的变量/关键字等。,最后被搜索
规则顺序: L –> E –> G –> B。
G = 3
def outer():
E = 2
def inner():
L = 1
print(L) # 1
print(E) # 2
print(G) # 3
return inner
outer()()
以上代码就是一个查找规则,在局部找不到,便会去局部外的局部找(例如闭包),再找不到就会去全局找,再者去内置中找。
is和==区别
编写一个代码,通过地址来比较以下:
a = [1, 2, 3]
b = [1, 2, 3]
print(id(a)) # 139837987049672
print(id(b)) # 139837987049736
print(a is b) # False
print(a == b) # True
通过代码可以发现,a和b的地址不同,则is的比较结果为False,但是他们的内容值是相同的,==的比较结果是True,由此得知:is比较的是地址是否相同,也即变量是否指向同一个对象,==是比较的内容是否相同
read、readline、readlines三者的区别
- read:从文件读取指定的字节数,如果未给定或为负则读取所有。
- readline:读取整行,包括 " " 字符。
- readlines:读取所有行并返回列表,若给定sizeint>0,则是设置一次读多少字节,这是为了减轻读取压力。
Python2.x和Python3.x区别
print函数:Python3需要加小括号- 整除:
# python2.7
10 / 3 = 3 # 不同之处
10.0 / 3 = 3.333333...
10 // 3 = 3
10.0 // 3 = 3.0
# python3.7
10 / 3 = 3.3333333....
10.0 / 3 = 3.333333....
10 // 3 = 3
10.0 // 3 = 3.0
range
# python2.7
t = range(10)
type(t) # list
# python3.7
t = range(10)
type(t) # range(0,10)
os.path 和 sys.path区别
- os.path 主要是用于对系统路径文件的操作。
- sys.path 主要是对 Python 解释器的系统环境参数的操作(动态的改变 Python 解释器搜索路径)
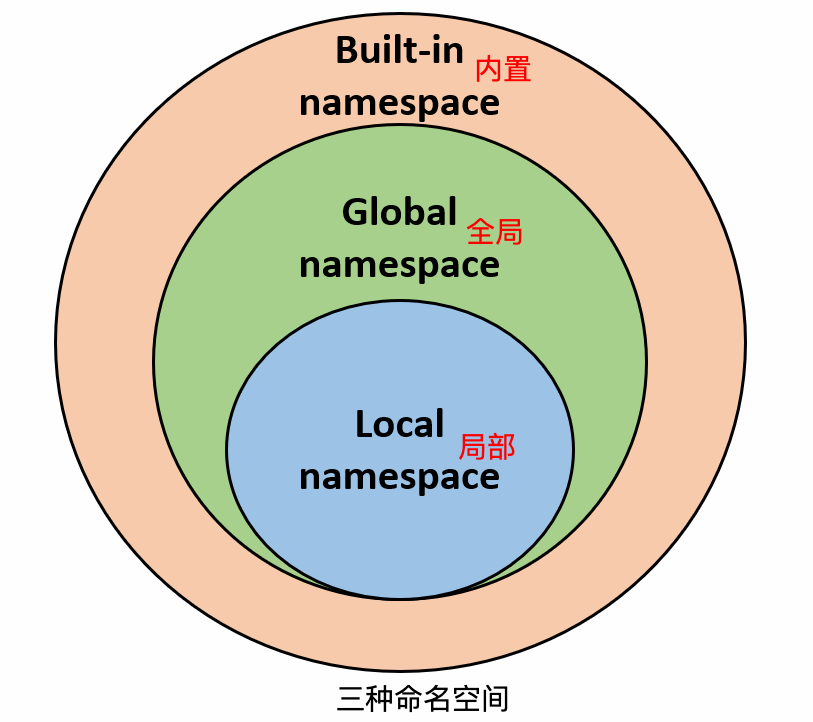
什么是 Python 的命名空间
命名空间(Namespace)是从名称到对象的映射,大部分的命名空间都是通过 Python 字典来实现的。也就说明了同一个命名空间的对象名称不能重复,不同命名空间可以存在相同的对象名称
一般有三种命名空间:
- 内置名称(built-in names), Python 语言内置的名称,比如函数名 abs、char 和异常名称 BaseException、Exception 等等。
- 全局名称(global names),模块中定义的名称,记录了模块的变量,包括函数、类、其它导入的模块、模块级的变量和常量。
- 局部名称(local names),函数中定义的名称,记录了函数的变量,包括函数的参数和局部定义的变量。(类中定义的也是)
命名空间的生命周期:
- 命名空间的生命周期取决于对象的作用域,如果对象执行完成,则该命名空间的生命周期就结束。因此,我们无法从外部命名空间访问内部命名空间的对象。
+,+=,extend区别
+:左右两边类型要一致,不改变原始值
a = [1, 2]
b = a + [3, 4]
print(b) # [1,2,3,4]
+=:就地加,会改变原始值。实际调用了__iadd__,而__iadd__调用extend(),extend又采用for循环的方式append每个元素
a += [3, 4]
print(a) # [1,2,3,4]
extend:采用for循环的方式append每个元素
a.extend([3,4])
print(a) # [1,2,3,4]
lambda函数
lambda表达式是一行函数。它们在其他语言中也被称为匿名函数。
- 简单使用
lambda 参数:操作(参数)
a = [(1, 2), (4, 1), (9, 10), (13, -3)]
a.sort(key=lambda x: x[1])
print(a) # [(13, -3), (4, 1), (1, 2), (9, 10)]
Python核心
迭代器和生成器
通过列表生成式,可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含百万元素的列表,不仅是占用很大的内存空间,如:我们只需要访问前面的几个元素,后面大部分元素所占的空间都是浪费的。因此,没有必要创建完整的列表(节省大量内存空间)。在Python中,我们可以采用生成器:边循环,边计算的机制—generator,在了解什么是生成器之前,先补充几个概念:
- 可迭代对象
在Python中任意的对象,只要它定义了可以返回一个迭代器的__iter__方法,或者定义了可以支持下标索引的__getitem__方法,那么它就是一个可迭代对象,即可迭代对象就能够使用for ... in ...
-
迭代器
- 迭代器是访问集合内元素的一种方式,一般用来遍历数据,迭代器只能一条条的产生数据,也就是惰性访问数据,不支持下标访问。
- 迭代器需要实现
__iter__和__next__魔法方法
class MyIterator(object):
"""自定义迭代器"""
def __init__(self, li):
self.li = li
self.index = 0
def __iter__(self):
return self
def __next__(self):
try:
item = self.li[self.index]
except IndexError as e:
raise StopIteration
self.index += 1
return item
my = MyIterator([1, 2, 3, 4])
while True:
try:
print(next(my))
except StopIteration:
break
- 迭代
迭代就是从一个可迭代容器中取出一个元素的过程,当我们使用循序来遍历某个东西或者对象的时候,这个过程本身就叫迭代。
- 生成器
生成器也是一种迭代器,但是你只能对其迭代一次,这是因为它们并没有把所有的值存在内存,而是在运行时产生值,可以通过遍历来使用它们,要么用一个for循环,要么将它们传递给任意可以进行迭代的函数和结构。大多数时候生成器是以函数来实现的。然而,它们并不返回一个值,而是 yield 一个值。
# 方式一,生成器表达式
# generator = (x*x for x in [0,1,2,3])
# 方式二,yield
def generator_function():
for i in range(10):
yield i
for item in generator_function():
print(item)
>>>0
>>>1
>>>2
>>>3
>>>...
推导式
# 列表推导式
l = [i for i in range(10)]
>>> [0,1,2,3,4,5,6,7,8,9]
# 字典推导式
d = {key:value for key,value in (("a",1),("b",2))}
>>> {'a': 1, 'b': 2}
# 集合推导式
s = {i for i in range(10)}
>>> {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
- 推导式的应用
list(filter(lambda x:x%2==0,l)) # [0,2,4,6,8]
map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10]) # [3, 7, 11, 15, 19]
from functools import reduce
reduce(lambda x, y: x+y, range(10)) # 45
怎么理解Python一切皆对象
object- 所有类的基类,包括type,也就是说所有类最终都继承了
object
- 所有类的基类,包括type,也就是说所有类最终都继承了
typetype创建了所有对象,例如object,list,str,int,自定义类type同时创建了自己type是一个类,同时是一个对象。

什么是魔法函数
以__foo__格式定义的函数,魔法函数可以定义在任意一个类,当某一个类定义某种特定的魔法函数就这个类对象可以实现相应的功能
class Person:
def __init__(self, li):
self.employee = li
def __getitem__(self, item):
# item为索引
return self.employee[item]
def __len__(self):
return len(self.employee)
c = Person(["tom", "jack", "bob"])
print(len(c)) # 调用__len__
for emp in c: # 调用__getitem__,直到抛出异常,for循环结束
print(emp)
- 当我们定义了
__len__方法就对象可以使用len() - 当我们调用了
__getitem__方法,这个类就可以实现for ...in...遍历,多说一下,for循环底层是优先采用的迭代器iter(),会去查找__iter__方法,,没找到最后退化到__getitem__通过下标的方式访问
有人肯定会想,那是因为我们把对象作用到了列表,其实Python的列表也实现了这些方法,而这些方法就是Python解释器给我们的接口,我们可以实现某些特定的魔法方法就可以使得我们自定义的类达到某种效果。
Python中的鸭子类型
这个东西很抽象,一句话:“当看到一只鸟走起来像鸭子,游泳起来像鸭子,叫起来也想鸭子,那么这只鸟就可以被称为鸭子。”,也就是我并不关心对象什么类型,到底是不是鸭子,只关心行为。通过代码来感受一下:
class Cat:
def say(self):
print("i am a cat")
class Dog:
def say(self):
print("i am a dog")
class Duck:
def say(self):
print("i am a duck")
animals = [Cat, Dog, Duck]
for animal in animals:
animal().say()
上面的代码定义了三个类,他们都实现了同一个方法,我们循环调用,可以看到animal对象,不管你是什么类型,只要你的行为是是啥你就是啥。
with上下文管理器
我们都用过Python中的with,它可以简化我们很多代码,其中最主要的就是帮我们进行异常的捕获或者文件的关闭等。通过代码我们看一下with到底是怎么实现了,一下是一个自定义的with上下文管理器:
class Demo(object):
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
print("exit")
# return True 会把捕获到的异常向上冒泡
# return False或者没有返回值 不会把捕获到的异常向上冒泡
def to_do(self):
print("do")
with Demo() as demo:
demo.to_do()
>>>enter
>>>do
>>>exit
这里又印证了Python中的魔法函数,当我们实现了__enter__和__exit__就可以使用with关键字,代码打印顺序中可以发现,优先执行__enter__然后with代码块中的内容,最后执行__exit__方法,对应我们的with open() as f,就是打开文件,读取文件,关闭文件。当然还有另一种方式,简单提一下:
import contextlib
@contextlib.contextmanager
def file_open(filename): # 函数必须是生成器
print("file open")
yield {}
print("file close")
with file_open("bobby.txt") as f:
print("....")
>>> file open
>>> ....
>>> file close
深拷贝和浅拷贝区别
- 深拷贝:嵌套拷贝,完整的复制
import copy
a = [1,2]
b = copy.deepcopy(a)
b.append(3) # b追加元素
>>>a :[1,2] # a不发生改变
>>>b :[1,2,3]
# 当a是一个嵌套的可变类型
a = [1,2,[3,4]]
b = copy.copy(a)
>>> b :[1,2,[3,4]]
b[2].append(5) # b 在嵌套列表中追加元素
>>>b : [1,2,[3,4,5]]
>>>a : [1,2,[3,4]] # a不发生变化
- 浅拷贝:只能拷贝最外层,无法嵌套拷贝
import copy
a = [1,2]
b = copy.copy(a)
b.append(3) # b 追加元素
>>>a :[1,2] # a 不发生变化,单层列表
>>>b :[1,2,3]
# 当a是一个嵌套的可变类型
a = [1,2,[3,4]]
b = copy.copy(a)
>>> b :[1,2,[3,4]]
b[2].append(5) # b在嵌套列表中追加元素
>>>b : [1,2,[3,4,5]]
>>>a : [1,2,[3,4,5]] # a发生变化,嵌套列表
__inti__和__new__ 区别
__new__:用来控制对象的生成过程,在__init__之前__init__:用来完善对象,需要__new__返回一个对象,否则不执行
super
super指向当前类的父类,但是这个父类不是表面继承的父类,在多继承的关系中表示的是mro继承顺序的下一个
面向切面AOP
面向切面简单来讲,就是对于在运行时,编译时,类和方法加载时,动态的将代码切入到类的指定方法或者指定位置上的编程思想就是面向切面
有了AOP,我们就可以把几个类的共有代码,抽取到一个切片中,等到需要时在切入到对象当中去,从而改变其原有的行为,而不会对原有的代码做修改。
举一个简单例子:
在Python中装饰器就是典型的面向切面编程,在一个系统中,可以通过装饰器插入日志,性能测试,事务处理等等,而被装饰的对象因此也就动态的改变了它原有的行为。
__getattr__和__getattribute
__getattr__: 在查找不到属性的时候调用__getarribute__: 无条件进入该函数,无论属性存在不存在都会访问
闭包和装饰器
具体内容可参考另一篇博文:https://www.cnblogs.com/ydongy/p/13062497.html
单例模式实现
具体内容可参考另一篇博文:https://www.cnblogs.com/ydongy/p/13062985.html
什么是协程?
具体内容可参考另一篇博文:https://www.cnblogs.com/ydongy/p/13065755.html
说说下面几个概念:并发,并行,同步,异步,阻塞,非阻塞?
- 并发:指在一个时间段内,有顶一个程序在同一个cpu上运行,但是任意时刻只有一个程序在cpu上运行
- 并行:在任意时刻,有多个程序同时运行在多个cpu上
- 同步:代码调用IO操作,必须等待IO操作完成才返回
- 异步:代码调用IO操作,不必等待IO操作完成才返回
- 阻塞:调用函数,当前线程被挂起
- 非阻塞:调用函数,当前线程不被挂起,立即返回
举例(买煎饼果子):
- 同步阻塞:啥事不干,就干等着店家把煎饼果子做好给你;
- 同步非阻塞:也是要等着,但是在等的同时我可以刷刷知乎,跟朋友聊聊天,每隔两分钟问问店家好了没,直到做好;
- 异步阻塞:买煎饼果子的人很多,店家雇了一个店小二,所有的顾客都到店小二这里登记领一个号,然后顾客就可以去干别的事了,但是店小二啥事不干,干等着店家把煎饼果子做好,做好了之后,再由店小二通知顾客来取;
- 异步非阻塞:店家不雇佣店小二了,边帮助顾客登记发号(是有顾客数目最大限制的),边做煎饼果子,做好了一个之后叫顾客来取;
什么是线程安全,什么是互斥锁?
什么是僵尸进程和孤儿进程?怎么避免僵尸进程?
- 孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
- 僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵死进程。
什么是守护进程?
什么是绿色线程?
什么是线程同步,Python实现线程同步的方式?
- 线程同步是当多个线程同时读写共享变量,会导致数据不一致,这里的同步的意思就是多个线程排队执行,可不是一起执行,当一个线程执行完毕下一个线程才能开始执行
- 线程同步的方式:
- 互斥锁:加锁会影响代码执行效率,同时还会引起死锁
from threading import Lock
total = 0
def add(lock):
global total
for i in range(100000):
# 上锁
lock.acquire()
total += 1
# 释放锁
lock.release()
def desc(lock):
global total
for i in range(100000):
# 上锁
lock.acquire()
total -= 1
# 释放锁
lock.release()
if __name__ == '__main__':
lock = Lock()
t1 = Thread(target=add, args=(lock,))
t2 = Thread(target=desc, args=(lock,))
t1.start()
t2.start()
t1.join()
t2.join()
print(total) # 0
什么是死锁,产生死锁的原因?
是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。
- 产生死锁的原因:
- 一个线程可以获取一个锁后,再继续获取锁:
def add(lock):
global total
for i in range(100000):
# 上锁
lock.acquire()
# 继续上锁
lock.acquire()
total += 1
# 释放锁
lock.release()
- 多个互斥锁
import threading
import time
lock1 = threading.Lock()
lock2 = threading.Lock()
class MyThread1(threading.Thread):
def run(self) -> None:
lock1.acquire() # 先对lock1上锁
print("MyThread1开始执行-----1")
lock2.acquire() # 再对lock2上锁,此时MyThread2已经上了锁,无法上锁,阻塞
print("MyThread1开始执行-----2")
lock2.release()
lock1.release()
class MyThread2(threading.Thread):
def run(self) -> None:
lock2.acquire() # 先对lock2上锁
print("MyThread2开始执行-----1")
lock1.acquire() # 再对lock1上锁,此时MyThread1已经上了锁,无法上锁,阻塞
print("MyThread2开始执行-----2")
lock1.release()
lock2.release()
Python 中的多进程与多线程的使用场景?
- 多进程:CPU 密集型 ,例如:数学计算、搜索、图像处理等
- 多线程:I/O 密集型 - 文件操作、网络交互、数据库操作等
根据应用场景选择最佳的性能优化方案
- I/O 密集型: 使用多线程
- I/O 密集型 & Pure Python: 使用 Pypy 解释器
- CPU 密集型: 使用多进程或把复杂逻辑用 C 扩展实现
Python中List、set、dict底层实现
Python高级
Python自省机制
自省就是面向对象的语言所写的程序在运行时,所能知道对象的类型,通过一定机制查询到对象内部结构,例如:
__dict__:返回一个字典,列出对象的所拥有的属性dir(object):它返回一个列表,列出了一个对象所拥有的属性和方法
Python代码执行原理
- 当我们运行python文件程序的时候,python解释器将源代码转换为字节码,然后再由CPU来执行这些字节码
- 代码执行后,python解释器(Cpython)会将xx.py文件编译成一个字节码对象PyCodeObject,并且只会存在内存中,代码执行结束,会把字节码对象保存在pyc中,pyc文件只是PyCodeObject对象在硬盘上的表现形式,通过dis这个python标准库来获得代码对应的字节码
- 编译过程:词法分析=>语法分析>生成.pyc文件(字节码文件)=>CPU识别字节码文件进行处
什么是GIL
GIL称为全局解释器锁,它使得任何时刻仅有一个线程在执行。即便在多核心处理器上,使用 GIL 的解释器也只允许同一时间执行一个线程。
加GIL是为了不同线程对共享资源访问的互斥,CPython设置GIL的主要原因是为了保证不让多个线程同时执行同一条字节码,这就避免了可能多个线程同时对某个对象进行操作。
有了GIL还需要锁,因为GIL是粗粒度锁。当我们的代码不是原子性操作时,比如加法,减法,当一个线程执行一条字节码语句时,加法操作还未完成,就释放了锁,而另一个线程访问全局变量时得到的结果并不是加法完成之后的值,就会导致线程不安全,通过代码来看一下加法的字节码操作:
import dis
def add(a):
a = a + 1
return a
dis.dis(add)
"""
21 0 LOAD_FAST 0 (a)
2 LOAD_CONST 1 (1)
4 BINARY_ADD
6 STORE_FAST 0 (a)
22 8 LOAD_FAST 0 (a)
10 RETURN_VALUE
"""
可以看到,加法操作对应到底层字节码的执行是分了几步,先加载变量,再加载值,再进行加操作,然后再赋值给变量,最后返回。因此当我们使用的线程在代码里面添加锁,目的是保证在一个加法操作的几个步骤是原子性的,中途不能打断,不能说我还没开始加,GIL线程切换策略就释放了锁,把线程执行权给了别的线程。
GIL线程切换策略:
一个线程有两种情况下会释放全局解释器锁,一种情况在该线程进入IO操作之前,会主动释放GIL;另一种情况是解释器不间断运行了1000字节码(Py2)或运行15毫秒(Py3)后,该线程也会放弃GIL。
Python垃圾回收机制有哪些以及原理
这是一个面试经常被问到的问题,这次我们就来掰扯掰扯它到底是个什么鬼东西,这么坑人。
在Python等一些高级语言都已经采用了垃圾回收的机制,而不再是c、c++那种需要程序员自己维护内存让程序员更好专注于业务逻辑。而Python主要采用的是引用计数为主,标记-清除和分代收集两种机制为辅的策略,我们逐一分析:
- 引用计数
引用计数也是一种垃圾收集机制,而且也是一种最直观,最简单的垃圾收集技术。当 Python 的某个对象的引用计数降为 0 时,说明没有任何引用指向该对象,该对象就成为要被回收的垃圾了。比如某个新建对象,它被分配给某个引用,对象的引用计数变为 1。如果引用被删除,对象的引用计数为 0,那么该对象就可以被垃圾回收。不过如果出现循环引用的话,引用计数机制就不再起有效的作用了
- 标记清除
如果两个对象的引用计数都为 1,但是仅仅存在他们之间的循环引用,那么这两个对象都是需要被回收的,也就是说,它们的引用计数虽然表现为非 0,但实际上有效的引用计数为 0。所以先将循环引用摘掉,就会得出这两个对象的有效计数
- 分代回收
从前面“标记-清除”这样的垃圾收集机制来看,这种垃圾收集机制所带来的额外操作实际上与系统中总的内存块的数量是相关的,当需要回收的内存块越多时,垃圾检测带来的额外操作就越多,而垃圾回收带来的额外操作就越少;反之,当需回收的内存块越少时,垃圾检测就将比垃圾回收带来更少的额外操作。
举个例子:
当某些内存块 M 经过了 3 次垃圾收集的清洗之后还存活时,我们就将内存块 M 划到一个集合A 中去,而新分配的内存都划分到集合 B 中去。当垃圾收集开始工作时,大多数情况都只对集合 B 进行垃圾回收,而对集合 A 进行垃圾回收要隔相当长一段时间后才进行,这就使得垃圾收集机制需要处理的内存少了,效率自然就提高了。在这个过程中,集合 B 中的某些内存块由于存活时间长而会被转移到集合 A 中,当然,集合 A 中实际上也存在一些垃圾,这些垃圾的回收会因为这种分代的机制而被延迟。
C10K问题
单台服务器要同时支持并发 10K 量级的连接
解决思路:
- 一个是对于每个连接处理分配一个独立的进程/线程。
- 另一个思路是用同一进程/线程来同时处理若干连接。(I/O多路复用)
I/O多路复用
Python中的元类(metaclass)
参考文献:
https://www.runoob.com/python3/python3-namespace-scope.html
首先,对于部分内容未填充,主要是我还需要通过代码的方式自行验证,后续会尽快完善。其次对于部分不准确的地方还望大佬提出。
最后的最后,以上仅代表个人观点,仅供参考!