定位方法:
前八种是使用频率较高的
1.id 定位:find_element_by_id(self, id_)
2.name 定位:find_element_by_name(self, name)
3.class 定位:find_element_by_class_name(self, name)
4.tag 定位:find_element_by_tag_name(self, name)
5.link 定位:find_element_by_link_text(self, link_text)
6.partial_link 定位 find_element_by_partial_link_text(self, link_text)
7.xpath 定位:find_element_by_xpath(self, xpath)
8.css 定位:find_element_by_css_selector(self, css_selector)
9.id 复数定位 find_elements_by_id(self, id_)
10.name 复数定位 find_elements_by_name(self, name)
11.class 复数定位 find_elements_by_class_name(self, name)
12.tag 复数定位 find_elements_by_tag_name(self, name)
13.link 复数定位 find_elements_by_link_text(self, text)
14.partial_link 复数定位 find_elements_by_partial_link_text(self, link_text)
15.xpath 复数定位 find_elements_by_xpath(self, xpath)
16.css 复数定位 find_elements_by_css_selector(self, css_selector)
参数化的方法
17.find_element(self, by='id', value=None)
18.find_elements(self, by='id', value=None)
xpath 定位
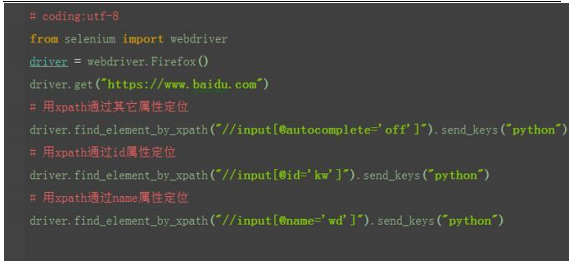
xpath:属性定位 1.xptah 也可以通过元素的 id、name、class 这些属性定位
xpath:其它属性 如果一个元素 id、name、class 属性都没有,这时候也可以通过其它属性定位到

xpath:标签 1.有时候同一个属性,同名的比较多,这时候可以通过标签筛选下,定位更准一 点
2.如果不想制定标签名称,可以用*号表示任意标签
3.如果想制定具体某个标签,就可以直接写标签名称
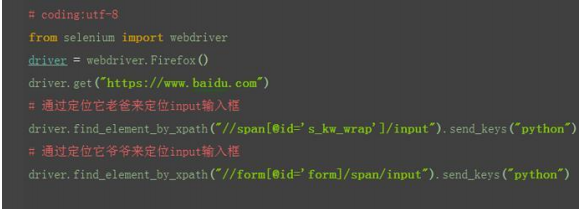
4.xpath:层级
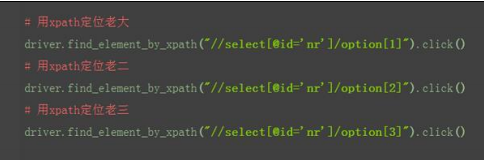
5.xpath:索引
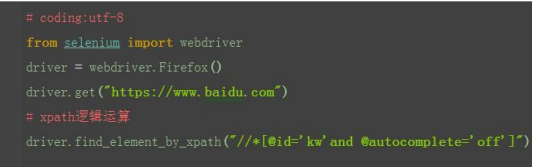
6 xpath:逻辑运算
1.xpath 还有一个比较强的功能,是可以多个属性逻辑运算的,可以支持与(and)、 或(or)、非(not)
2.一般用的比较多的是 and 运算,同时满足两个属性
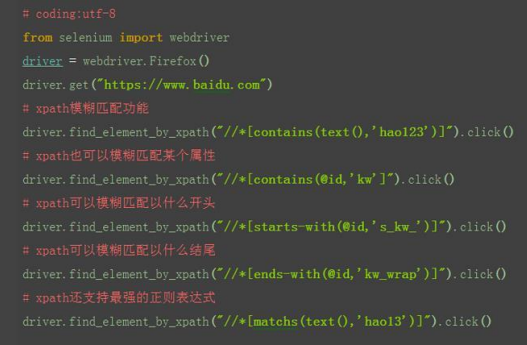
7 xpath:模糊匹配
1.xpath 还有一个非常强大的功能,模糊匹配
2.掌握了模糊匹配功能,基本上没有到位不到的
3.比如我要定位百度页面的超链接“hao123”,在上一篇中讲过可以通过 by_link,也可以通过 by_partial_link,模糊匹配定位到。当然 xpath 也可以有 同样的功能,并且更为强大
CSS 定位语法
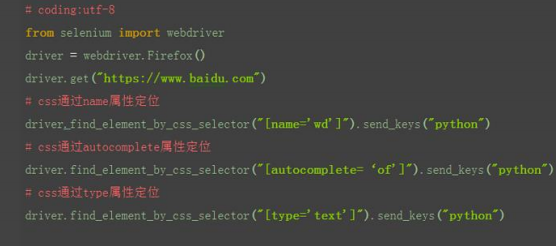
1 css:属性定位
1.css 可以通过元素的 id、class、标签这三个常规属性直接定位到
2.css 用#号表示 id 属性,如:#kw
3.css 用.表示 class 属性,如:.s_ipt
4.css 直接用标签名称,无任何标示符,如:input

css:其它属性
1.css 除了可以通过标签、class、id 这三个常规属性定位外,也可以通过其它 属性定位
css:标签
1.css 页可以通过标签与属性的组合来定位元素

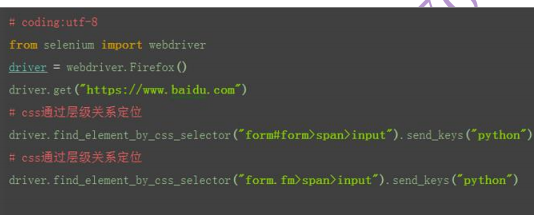
css:层级关系
css:索引
css 也可以通过索引 option:nth-child(1)来定位子元素,这点与 xpath 写法 用很大差异,其实很好理解,直接翻译过来就是第几个小孩
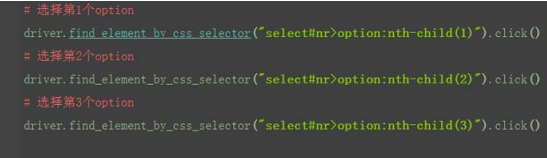
6 css:逻辑运算
1.css 同样也可以实现逻辑运算,同时匹配两个属性,这里跟 xpath 不一样,无 需写 and 关键字
selenium操作cookies实现免密登录
以博客园为例
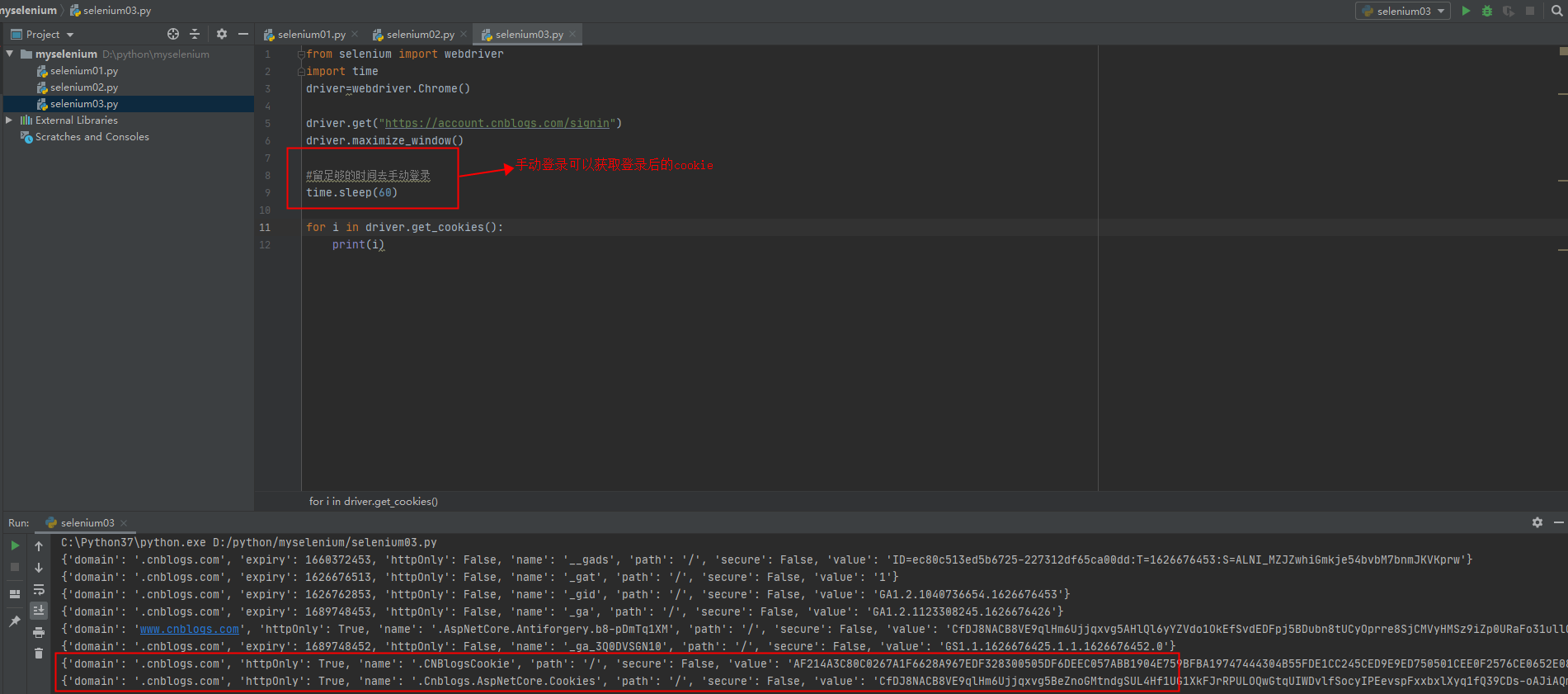
获取到cookie后


注:不知道登录的有效cookie是哪个,可以登录前打印一个cookie,登录后再打印一遍cookie,即可知道如果实现登录需要的cookie值是哪个
定位输入框联想词
一:首先在百度输入框输入例如博客,下面会出现许多联想词,选中其中一个,鼠标右键点击检查,可以看到下方匹配出来的词都有共同的class属性,这时候可以使用find_elements_...全部定位了,.通过get_attribute()方法就可以获取到文本信息了。
参考链接:https://www.cnblogs.com/canglongdao/p/13594459.html
Selenium 三种等待方式详解
一:强制等待
利用time模块的sleep方法来实现,最简单粗暴的等待方法
这种叫强制等待,不管你浏览器是否加载完成,都得给我等待3秒,3秒一到,继续执行下面的代码,不建议用这种等待方法,严重影响代码的执行速度
二:隐式等待
设置一个等待时间,如果在这个等待时间内,网页加载完成,则执行下一步;否则一直等待时间截止,然后再执行下一步。这样也就会有个弊端,程序会一直等待整个页面加载完成,直到超时,但有时候我需要的那个元素早就加载完成了,只是页面上有个别其他元素加载特别慢,我仍要等待页面全部加载完成才能执行下一步。
# 隐式等待30秒 driver.implicitly_wait(30)
三:显示等待
元素一加载出来就执行下一步(显示等待两种方式)
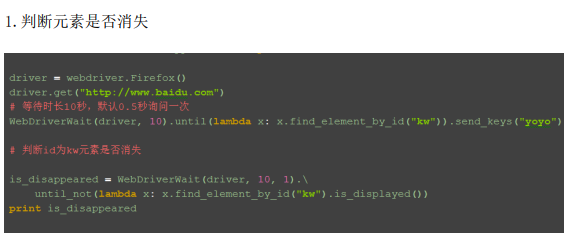
一是等待元素出现

二是等待元素消失until_not()