1、场景监控的含义
- 整个监视过程由控制器来执行并在监控过程中收集相关数据。
- LoadRunner 更多的是监控每种服务器资源消耗的情况,对于各种服务器自身的某些特 性需要使用第三方工具监控。
- 使用负载平衡技术时,负载机首先收集每个虚拟用户运行时的数据,再将这些数据发送 到控制器,由控制器将数据保存在数据库中,最后由分析器来重新整理数据,画成不同 的曲线图。
2、监控系统资源的含义
- 监控系统资源是为了分析是否由于系统资源引起了性能瓶颈,通常分析内存、硬盘和 CPU。
- 在 LoadRunner 中,通过添加计数器来监控系统资源。
3、内存计数器(Memory)
关注 Available Bytes、Pages/sec、Page Faults/sec
1)avaliable bytes

2)Pages/sec
表示每秒出错页的平均数量。

3)Page Faults/sec
- 表示为解决硬页错误从硬盘读取或写入磁盘的页数。
- 应该保持 0-20 或接近 0。
- Pages/sec 的值很大可能是内存问题,应进一步研究内存页交换
4)关于内存泄漏
一般以下两种情况表明出现内存泄漏的情况:
(1)观察内存分配池,如果内存分配池中可用内存消耗是呈不断上升的趋势, 说明可能出现内存泄漏的情况。 建议 7*24 测试; 观察 working set、handle count、private bytes 是否持续上升。
(2)进程分配内存后,但并未将用完的内存回收。
4、CPU计数器
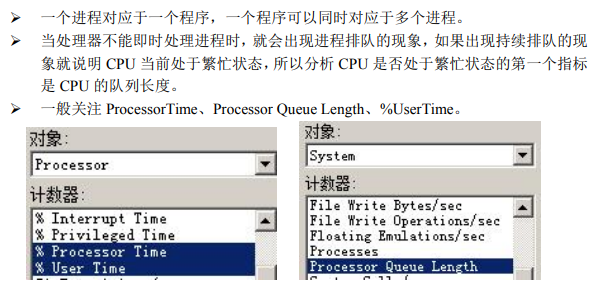
1 )%Processor Time
- 表示被消耗的处理器时间百分比。
- 此值持续高于 80%,说明 CPU 存在压力,需要继续分解以确定用户模式进程(User Time)还是内核模式进程(Privileged Time)消耗的时间更多。
2 )%UserTime
若%UserTime 占比很大,说明应用程序出了问题,接下来需要确定是哪个进程消耗 了 CPU 的时间。
3 )Processor Queue Length
- 表示队列长度,一般不大于 2。
- 若 Processor Queue Length 显示的队列长度保持不变(>=2),且处理器的利用率 Processor Time 超过 90%,则很可能存在处理器瓶颈。
- 若发现 Processor queue length 显示的队列长度超过 2,但处理器的利用率却一直很 低,则应该去解决处理器阻塞问题,处理器一般不是瓶颈。
3、 磁盘计数器

1) %Disk Time
表示所选磁盘忙于为读或写入请求提供服务所用时间的百分比。正常值小于 10。此值过大表示耗费太多时间来访问磁盘,可考虑增加内存、更换更快的硬 盘、优化读写数据的算法等。
2 )Average Disk Queue Length
表示读写请求的平均队列数,正常值小于 0.5。此值过大表示磁盘 I/O 太慢, 需更换更快硬盘。
3 )Average Disk Seconds/Read
表示读取数据所需的平均时间
4) Average Disk Seconds/Write
表示写入数据所需的平均时间。
4、监控Windows
1)被监控程序操作

2)监控方设置
--》
---》添加度量
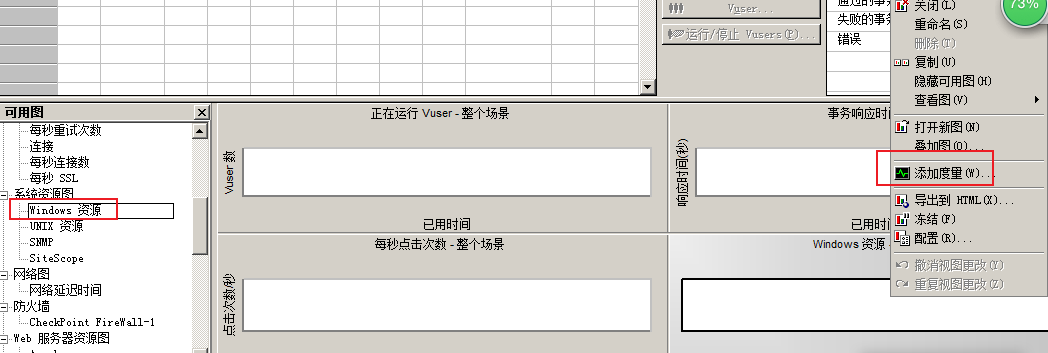
--》添加监控计算机的IP
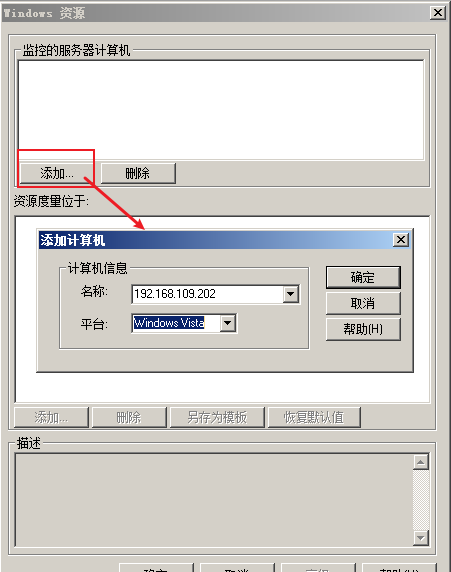
---》输入登录信息
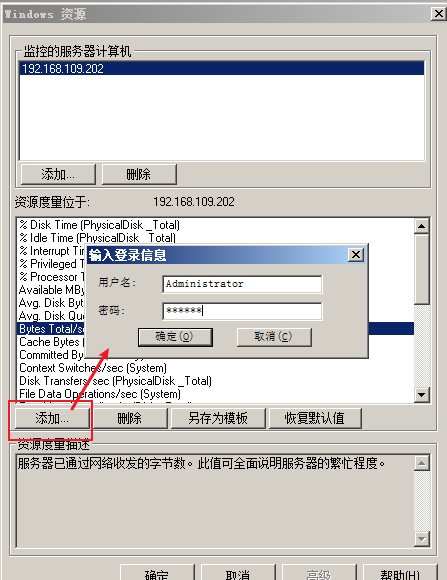
--》添加度量

-->查看指标

5、监控 Linux
1)被监控程序操作
--》Linux 设置 ip、关闭防火墙
1)关闭防火墙
查看防火墙状态:systemctl status firewalld.service
关闭防火墙:systemctl stop firewalld.service
2)设置ip:vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0 TYPE=Ethernet HWADDR=00:0c:29:fd:27:28 UUID=2e7bc683-1bdb-4843-be9d-a69ded421d11 ONBOOT=yes NM_CONTROLLED=yes BOOTPROTO=static IPADDR=192.168.109.128 GATEWAY=192.168.109.1 BROADCAST=192.168.109.255
3)重启网络
service network restart
重启失败
eth0 变成 eth1 后出错的解决方案 ; 当服务器更换完主板或者网卡时经常出现网卡乱序的问题。

解决方案:
vi /etc/sysconfig/network-scripts/ifcfg-eth0,注释 HWADDR 一行,或 者删除此行
rm -fr /etc/udev/rules.d/70-persistent-net.rules
重启 Linux
-->按顺序安装 gcc-c++、rsh、rsh-server
安装gcc-c++:
yum install gcc-c++
查询是否安装:
rpm -q gcc-c++
安装rsh、rsh-server
yum -y install rsh rsh-server
-->安装rstatd.tar.gz
解压 tar -zxvf rstatd.tar.gz 进入 rstatd ./configure→make→makeinstall
--》接输入 rpc.rstatd 启动该服务
--》进入/etc/xinetd.d 目录
分别进入文件 rsh、rexec、rlogin,将 disabled=yes 改为 no
--》执行 service xinetd restart ,重启 rsh、rexec、rlogin 服务
service xinetd restart
2)进行监控,其余与监控Windows相同
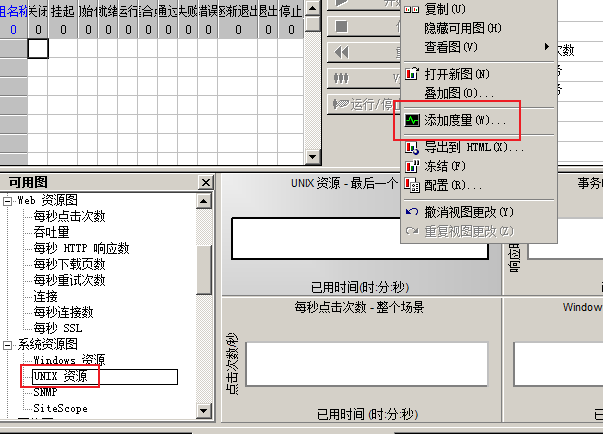
6、监控 SQL Server
1) SQL Server所在机器
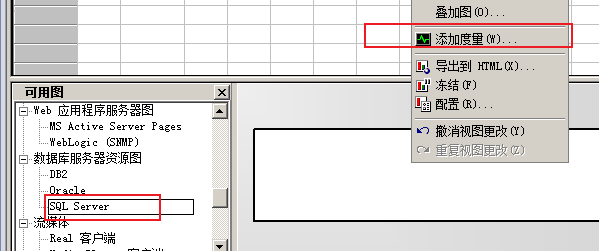
2)
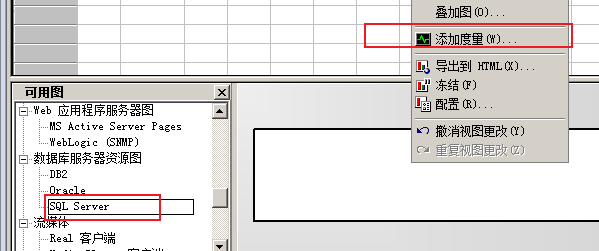
--》监控CPU
Processor Queue Length(处理器的队列长度)
正常情况下服务器不忙碌的时候不可能出现处理器排队的现象,当处理器出现 排队现象时,则说服务器的性能受到影响,一般情况下处理器的队列长度不超 过 CPU 个数
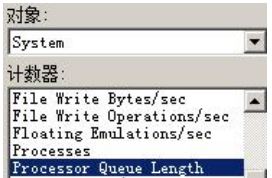
%UserTime
显示 SQL Server 进程所消耗的 CPU 时间数量。 如果发现 CPU 的使用率过高,通常是高于 85%,那么很有可能是 CPU 出现 瓶颈,接下来需要进一步分析是什么原因导致 CPU 的使用率过高。
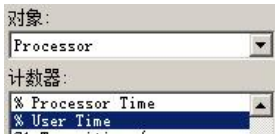
SQL Statistics-SQLCompilatlons/sec与SQLRe-Compilations/sec
这两计数器表示执行计划编译与重编译率; 对于一台服务器,执行计划的重用率至少应该在 90%以上,即在执行过程中, 最多只有 10%的查询计划需要重新进行编译,如果当执行过程中需要重新编 译的查询计划过多,那么将导致消耗过高的 CPU 资源。
---》监控内存
Buffer Manager-Total Pages、Target Pages 与 stolen pages

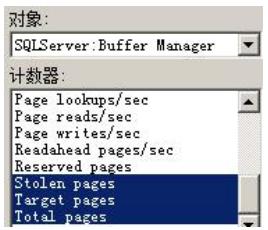
Page Life Expectancy 与 Buffer cache hit ratio

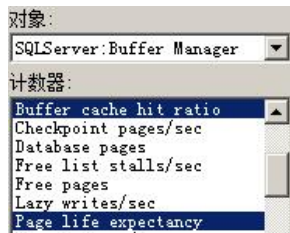
3)监控硬盘
在执行查询计划过程中,最多的是对磁盘进行写入与读出数据的操作,所以 SQL Server 服务器应该尽可能地避免频繁地在磁盘与内存间进行传递数据,以降低对服 务器性能的影响,为了解决这个问题,SQLServer 使用缓冲高速缓存(Buffercache) 和计划高速缓存(Plancache)。
- Buffer cache 用于预载数据;
- Plan cache 用于加载检索数据的方法是否是最优计划
Full scans/sec
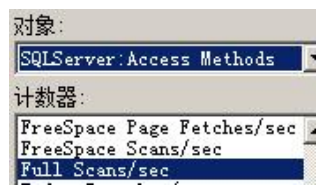
该计数器表示每秒钟完全扫描索引或完全扫描基本表的数目,在数据库设计过 程中应该尽量降低全表扫描的次数,特别是对于那些大表,如果进行全表扫描 将会直接导致性能下降,如果扫描频率大于一次,则说明缺少索引或索引较差。
Page Splits/sec
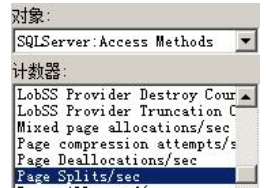
该计数器表示每秒钟页面拆分数量,在执行插入或更新计划时,如果当前的数 据页没有足够的空间来完成这些操作,那么就必须增加新页来完成插入或更新 操作,过多的拆分页会损害服务器的性能。
7、监控 Apache
1)安装Apache
--》软件地址
链接:https://pan.baidu.com/s/16FeUm_ZO_Tq7y8rVMrHJKA
提取码:1a81
2)监控
--》
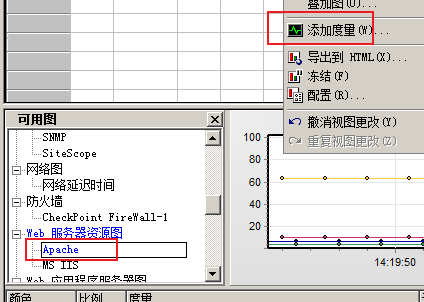
--》添加计算机
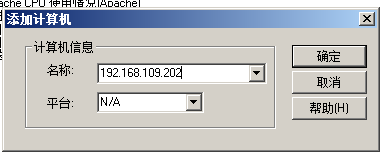
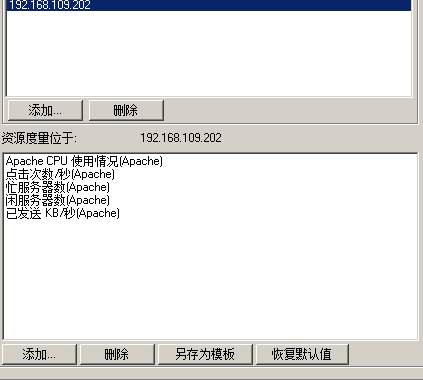
-->添加度量
报 错 信 息 : 【 Monitor name :Apache. Parsing error, cannot find token: BusyServers. Measurement: BusyServers|192.168.109.202. Hints: 1) Such a measurement does not exist, or the html page may be different from the supported one. 2) Try to replace the Apache.cfg with appropriate Apache_<version>.cfg file in <Installation>datmonitors and rerun the application (entry point: CApacheMeasurement::NewData)
这是由于要监视Apache的版本提供的计数器与LoadRunner默认的计 数器不一致导致的。
1) 先关闭Controller,打开HPLoadRunnerdatmonitors下的 apache.cfg文件
搜索Servers,将Servers替换为Workers,具体如下(
修改Counter0=IdleServers为Counter0=IdleWorkers,同时修改注 释 信 息 Label0=#Idle Servers (Apache) 为 Label0=#Idle Workers (Apache),描述信息也建议修改;
修改Counter4=BusyServers为Counter4=BusyWorkers,同时修改 注 释 信 息 Label4=#Busy Servers (Apache) 为 Label4=#Busy Workers (Apache) ,描述信息也建议修改。
)
2)重新监控
Apache CPU Usage: 服务器CPU的占用率
Kbytes Sent/sec : 服务器每秒发送的字节数
Hits/sec : Apache服务每秒的点击率
Busy Workers : Apache服务占用率(正在工作数)
ldle Workers : Apache服务空闲率(空闲工作数)
8、监控 MySQL
1)在被测计算机安装mysql
2)在loadrunner所在机器安装jdk、HPSiteScope
-->安装HPSiteScope
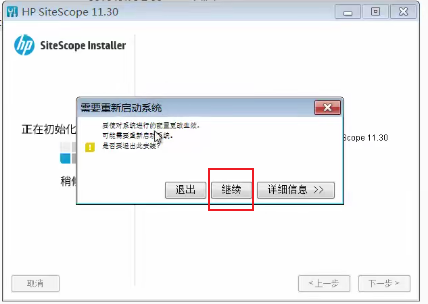
--》点击继续
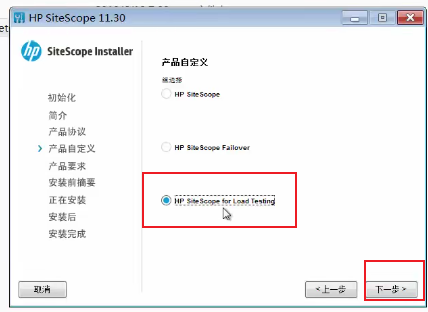
--》点击第三项
--》选择安装位置
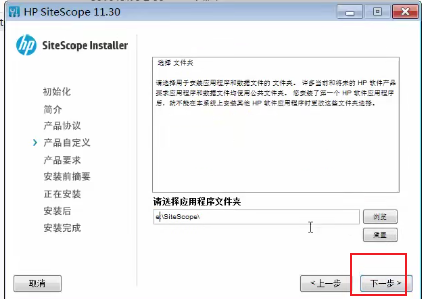
--》点击下一步,安装
--》下一步
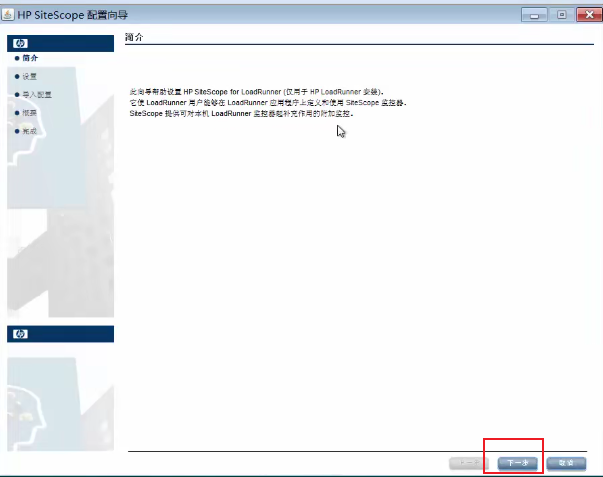
--》
--》安装完成

--》访问HP site Scope
http://localhost:8080
IE 浏览器建议使用 32 位
在弹窗中选择“稍后”,不要阻止
--》点击接受,运行
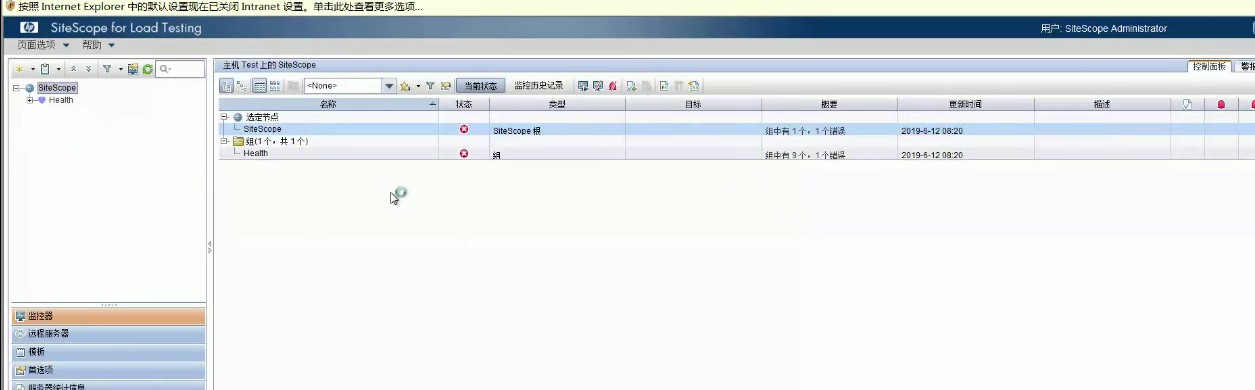
--》出现如图所示,代表安装配置成功
--》复制 mysql 驱动
将 mysql 驱动程序(mysql-connector-java)拷贝放在 sitescope 安装目录下的 java/lib/ext 下
重启 SiteScope 服务
在命令行输入services.msc
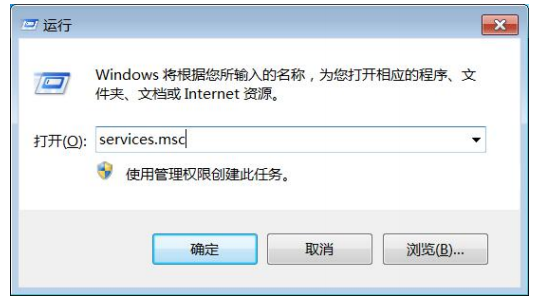
找到HP SiteScope,重新启动
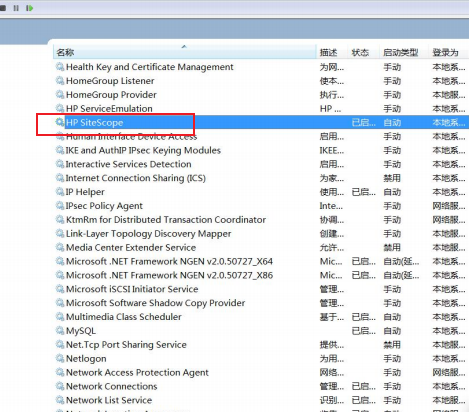
--》关闭浏览器,再次打开,输入localhost:8080/
IE 浏览器建议使用 32 位
在弹窗中选择“稍后”,不要阻止
-->接受,运行
SiteScope 设置
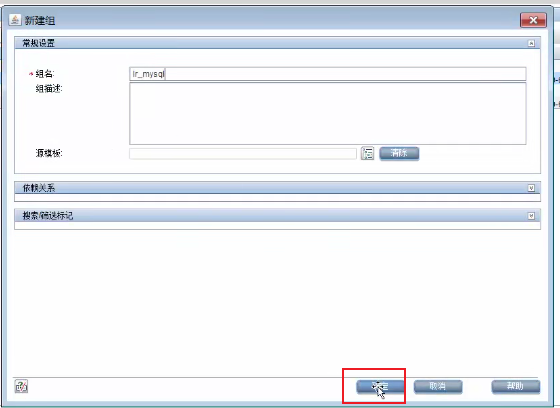
1)新建组
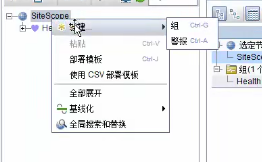
--》输入组名,点击确定
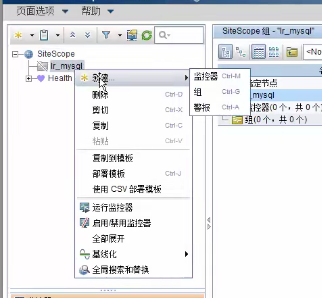
2)新建一个监控器
--》右击组,新建监控器
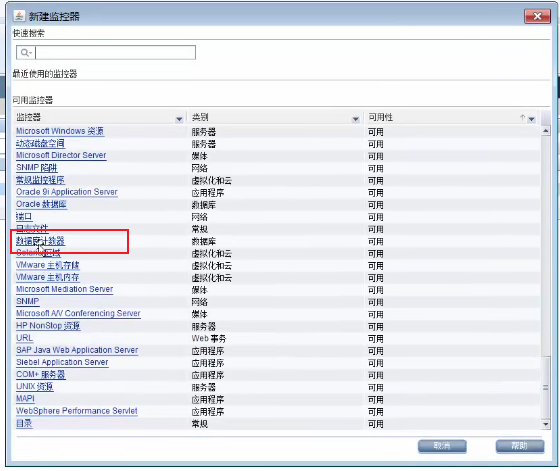
--》选择数据库计数器
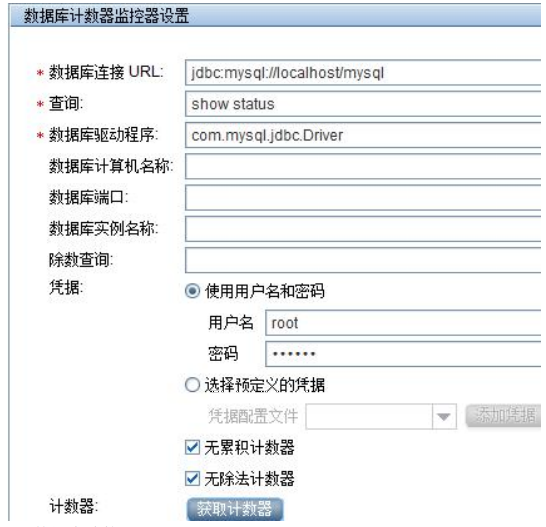
--》填写配置
--》选择计数器表单
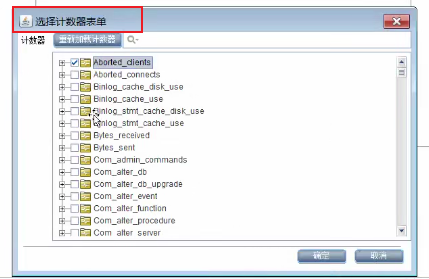
常用表单
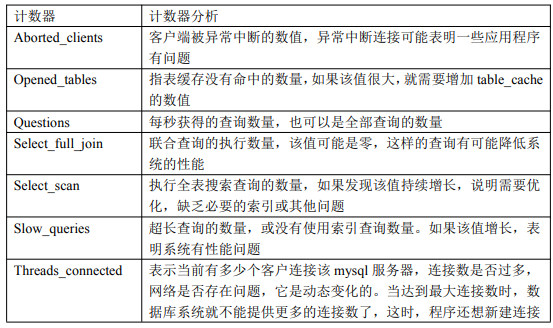

--》确定,保存
--》新建计数器成功
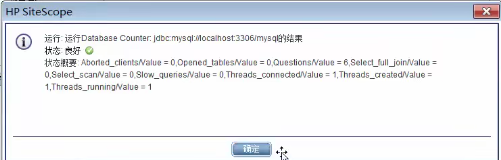
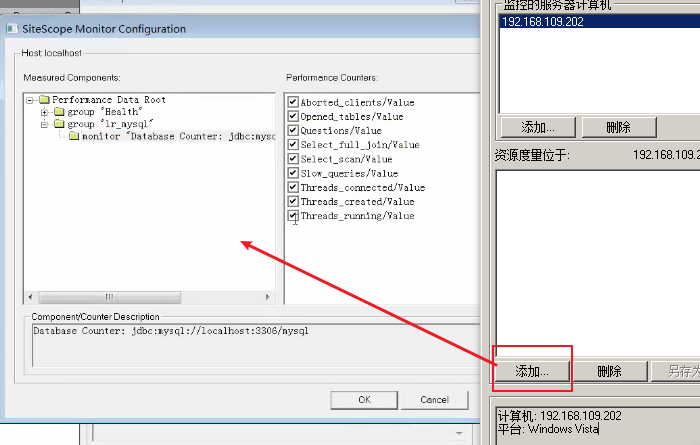
监控MySQL
1)添加度量
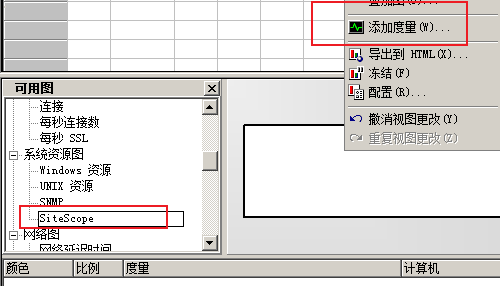
2)添加监控计算机
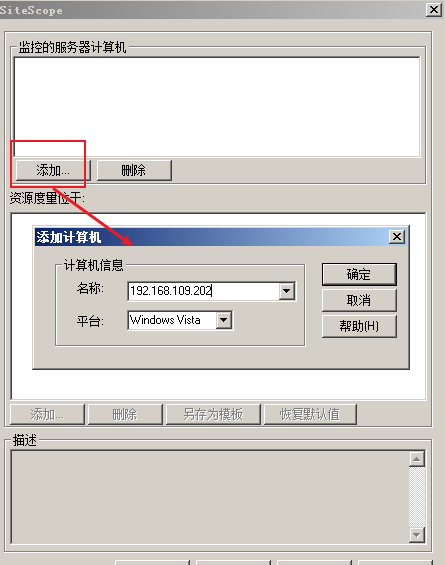
3)选择指标,点击确定