排序
1.什么是排序?
排序就是将一个数据元素(或记录)的任意序列,通过一定的方法重新排列成一个按关键字有序的序列的过程。
2.排序的稳定性
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,则称这种排序算法是稳定的;
(即在原序列中,ri=rj,且ri在rj之前,而在排序后的序列中,ri仍在rj之前)稳定的排序的优点:从一个键上排序,然后再从另一个键上排序,第一个键排序的结果可以为第二个键排序所用。
例:假设一个班的学生已经按照学号大小排好序了,我现在要求按照年龄从小到大再排个序,如果年龄相同的,必须按照学号从小到大的顺序排列。
那么问题来了,你选择的年龄排序方法如果是不稳定的,是不是排序完了后年龄相同的一组学生学号就乱了,
你就得把这组年龄相同的学生再按照学号拍一遍。如果是稳定的排序算法,我就只需要按照年龄排一遍就好了。
3.内部排序和外部排序
根据在排序过程中,待排序的记录是否全部被放置在内存中,排序分为内部排序和外部排序;
内部排序:在整个排序过程中,待排序的所有记录全部被放置在内存中
(插入排序、交换排序、分配排序、选择排序和归并排序等)
外部排序:由于排序的记录个数太多,不能同时放置在内存中,整个排序过程需要在内存、外存之间多次交换数据才能进行。
排序算法分类


1.比较类排序
1).交换排序: 冒泡排序
快速排序 (x>100 数据量大)
2).插入排序:直接插入排序
希尔排序
二分插入排序
表插入排序3).选择排序: 选择排序 (0<x<=10)
堆排序 (10<x<=100)
4).归并排序: 二路归并排序
多路归并排序2.非比较排序
1).计数排序
2).桶排序
3).基数排序(分配排序)
排序算法复杂度计算
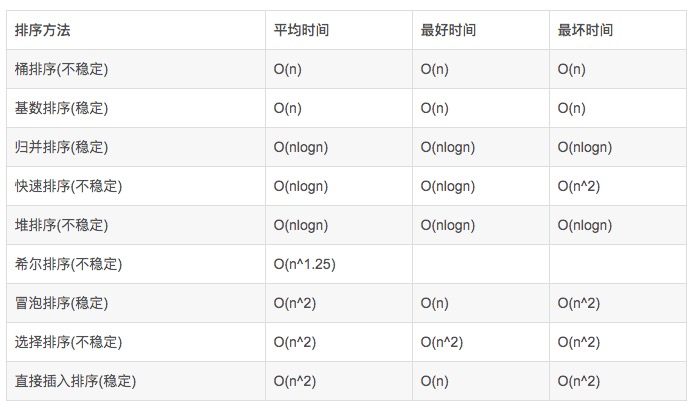
O(n)这样的标志叫做渐近时间复杂度,是个近似值.各种渐近时间复杂度由小到大的顺序:O(1) < O(logn) < O(n) < O(nlogn) < O(n^2) < O(n^3) < O(2^n) < O(n!) < O(n^n)
冒泡、插入、 归并、基数:是稳定的排序
冒泡、选择、插入 平均时间复杂度为:O(n^2)
快速、归并、堆排序 平均复杂度为:O(nlogn)
桶、基数 :最好最坏平均时间复杂度均为:O(n) <---最快的排序算法,但有一定限制
选择:最好最坏平均时间复杂度均为:O(n^2)
常见排序算法
# 1.冒泡排序(Bubble Sort)
临近的数字两两进行比较,按照从小到大或者从大到小的顺序进行交换,这样一趟过去后,最大或最小的数字被交换到了最后一位,然后再从头开始进行两两比较交换,直到倒数第二位时结束,以此类推比较第i次。。。
这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
算法描述
步骤1: 比较相邻的元素。如果第一个比第二个大,就交换它们两个;
步骤2: 对每对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
步骤3: 重复步骤1-2,遍历 n-1 个元素比较;
步骤4: 重复步骤1~3,直到排序完成。
算法分析
最佳情况:T(n) = O(n) 当数据是正序时
最差情况:T(n) = O(n^2) 当数据是反序时
平均情况:T(n) = O(n^2)
空间复杂度:O(1)
稳定度:稳定

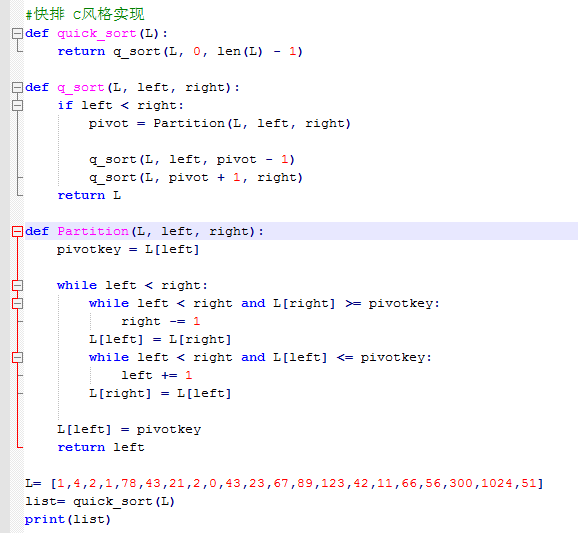
# 2.快速排序
对冒泡排序的改进,选出一个值,其他的数和这个值比较,比这个值小的都放在左边,比这个值大的都放在右边
快速排序:是由东尼·霍尔所发现的一种排序算法本质上来看,快速排序算是在冒泡排序基础上的 递归分治法,在《算法艺术与信息学竞赛》上找到了满意的答案: 快速排序 总是优于 归并排序
算法思想:
1. 从数列中选出一个基准数,一般将第一个元素设置为基准数;
2. 当左右下标不相等的时候,先从右往左找一个小于基准数的数、再从左往右找一个大于基准数的数,然后交换他们,
循环这样操作,直到左右下标相等时,将相等的元素与基准数交换位置,所有比基准值小的放在基准左边,所有元素比基准值大的摆在右边,
3. 递归地把小于基准值元素的子数列和大于基准值元素的子数列排序;(因为递归,所以耗内存)
实现思路:
1)以数组第一个元素作为基准数,即:base=A[0]
2)设置两个变量i、j,排序开始时:i=0,j=N-1
3)当左右下标不等时, i!=j:
从j开始向前搜索(j--),找到第一个小于base的A[j],
从i开始向后搜索(i++),找到第一个大于base的A[i],
将A[i]和A[j]互换
4)重复第3步,直到 i=j时,将A[i]与基准数A[0]交换位置(这样就完成了一次快排,此时,所有比基准数小的排在前面,所有比基准数大的排在后面)
5)递归的执行步骤 2~4
算法分析
时间复杂度:Ο(nlogn)
最坏时间复杂度:O(n²), (如:顺序数列)
空间复杂度:O(logn)
稳定度:不稳定
应用场景:快排----适合数据量较大的情况


# 3.插入排序
插入排序通过把序列中的值插入一个已经排序好的序列中,直到该序列的结束。插入排序是对冒泡排序的改进。它比冒泡排序快2倍。一般不用在数据大于1000的场合下使用插入排序,或者重复排序超过200数据项的序列。
原理:通过先构建有序序列,对未排序数据在已排序序列中从后向前扫描,找到相应位置并插入。
算法步骤:
(1)将第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列 即:已排序序列A[0] 待排序序列A[1]~A[N]
(2)取出未排序列中第一个元素,在有序序列中从后往前进行扫描 即:A[1]与A[0比较]
(3)如果有序序列的元素大于待排序列的第一个元素,则将有序序列的元素后移一个位置
(4)重复步骤3,直到找到有序序列中元素小于或等于待排序元素的位置
(5)将待排序元素插入到有序序列后(i+1)的位置上
(6)重复步骤2~5,直到遍历完待排序序列元素
算法分析
最佳情况:T(n) = O(1) 当数据是几乎排好序的
最差情况:T(n) = O(n^2)
平均情况:T(n) = O(n^2)
空间复杂度:O(1)
稳定度:稳定

# 4.希尔排序
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本 。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
1.插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率;
2.但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位;
希尔排序的思想:
先将整个待排序序列分割成为若干子序列,分别对子序列进行直接插入排序;
待整个序列中的记录"基本有序"时,再对全体记录进行依次直接插入排序。
算法分析
时间复杂度:Ο(nlogn)
时间复杂度范围:O(nlog2n)~O(nlog2n)
空间复杂度:O(1)
稳定度:不稳定

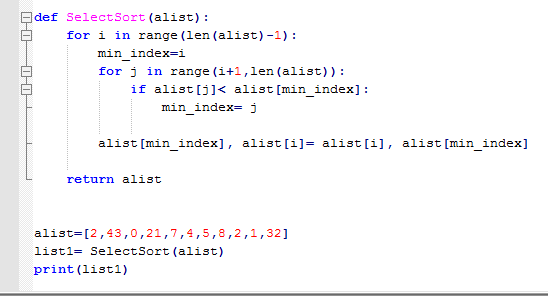
# 5.选择排序
Selection sort 是一种简单直观的排序算法,每次遍历选择一个最值,和冒泡的区别在于交换的是位置,也就是脚标
1.算法思想:
1.设第一个元素为最小元素,依次和后面的元素比较,比较完所有元素找到最小的元素,将它和第一个元素互换;
2.重复上述操作,我们找出第二小的元素和第二个位置的元素互换;
3.以此类推找出剩余最小元素将它换到前面,即完成排序
选择排序和冒泡排序很类似,区别:
选择排序每轮比较只会有一次交换,交换次数比冒泡排序少,就减少cpu的消耗,所以在数据量小的时候可以用选择排序 : x<10
比较性:因为排序时元素之间需要比较,所以是比较排序
算法分析:
时间复杂度:我们看到选择排序同样是双层循环n*(n-1),所以时间复杂度也为:O(n^2)
空间复杂度:只需要常数个辅助单元,所以空间复杂度也为O(1)
记忆方法:选择对象要先选最小的,因为嫩,哈哈
稳定性:因为存在任意位置的两个元素交换,所以为不稳定排序
"""
# 6.堆排序
堆排序适合于数据量非常大的场合(百万数据)。比如超过数百万条记录,因为快速排序,归并排序都使用递归来设计算法,在数据量非常大的时候,可能会发生堆栈溢出错误。
堆排序会将所有的数据建成一个堆,最大的数据在堆顶,然后将堆顶数据和序列的最后一个数据交换。接下来再次重建堆,交换数据,依次下去,就可以排序所有的数据。
堆是一个完全二叉树,且所有子节点靠左
堆排序算法步骤:
1.首先将待排序的数组构造出一个大(小)根堆
2.取出这个大根堆的堆顶节点(最大值),与堆的最下最右的元素进行交换,然后把剩下的元素再构造出一个大根堆
3.重复第二步,直到这个大根堆的长度为1,此时完成排序
时间复杂度: 最好最坏都是 O(nlogn)
空间复杂度:O(1)
稳定性:不稳定


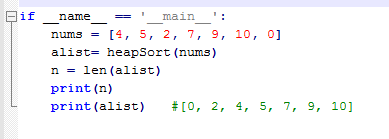
# 7.归并排序
归并排序使用了二分法,归根到底的思想是分而治之,递归地完成二分后子序列的排序,再合并排序
归并排序思想:
1.将待排序列不停的分为左边和右边两份,依次递归地分成单个元素;
2.分开之后,按照最后分开的两个数比较大小,形成正确顺序后组合绑定;
3.对每组数据按照上次分开的结果,进行排序后绑定;
4.对上次分开的两组进行排序;
5.每个组依次拿出第一个数比较,小的放前面,以此类推直到一个数组为空;
时间复杂度: 最好最坏都是 O(nlogn)
空间复杂度:O(n)
稳定性:稳定
缺点:每次拆分数组都要开新的数组, 每次合并数组都要开新数组,空间复杂度很大

# 8.计数排序
核心思想:将输入的数值转化为键存储在额外开辟的数组空间中
算法的步骤如下:
(1)找出待排序的数组中最大元素
(2)统计数组中每个值为 i 的元素出现的次数,存入数组C的第 i 项
(3)对所有的计数累加,从C中的第一个元素开始,每一项和前一项相加
(4)反向填充目标数组,将每个元素 i 放在新数组的第C(i)项,每放一个元素就将C(i)减去1
计数排序要求:
输入的数据必须是有确定范围的整数,且最大值最小值相差不大
缺点:
1.计数排序对于数据范围很大的数组,需要大量时间和内存
2.不适合字母和浮点数排序
算法分析
时间复杂度:O(n)
最好最坏时间复杂度均为:O(n)
空间复杂度:O(n)
稳定性:稳定

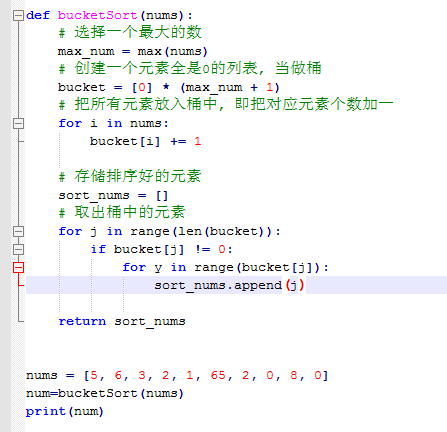
# 9.桶排序
桶排序是计数排序的升级版,计数排序是桶排序的一种特殊情况,可以把计数排序当成每个桶里只有一个元素的情况
要求:数据的分布必须均匀(最大值和最小值相差不大),不然可能会失效
桶排序与计数排序一样,不能用于小数、负数、字符排序
为了使桶排序更加高效,需要做到两点:
1.在额外空间充足的情况下,尽量增大桶的数量
2.使用的映射函数能够将输入的 N个数据均匀的分配到 K个桶中
算法步骤:
1.根据元素范围确定桶的个数
2.遍历原始数据,并对每个元素出现次数进行计数,将计数放入桶中
3.遍历计数完成后的各个桶,输出数据
算法分析
最好、最坏、平均时间复杂度范围为:O(n)
空间复杂度:O(n)
稳定性:稳定
# 10.基数排序
算法思想
基数排序通过按位比较,将元素按照最低位的数放到10个桶中,
当所有的元素都这样被处理一次后,在按从0到9的顺序将每个桶的元素再取出来(不关注其他位的,只关注当前位的)
这样就完成了所有元素最低位的有序性,然后不断的重复上面的步骤,直到所有元素的最高位都经过处理了。
算法步骤
1.初始化桶,如共有10个,分别存放当前位0-9的元素
2.从元素的最后一位开始,按照最后一位的数字将其放到相应的同元素中
对列表中的每个元素都进行上面的操作后,从0号桶开始,将元素从桶中取出来,这样就完成了一个位数的排序
3.重复上一过程,如果发现元素最高位已经被处理过,就把他添加到最终的结果中
算法分析
最好、最坏、平均时间复杂度均为:O(n)
空间复杂度: O(n)
稳定度:稳定
确定一个正整数的位数
方法一:math.ceil(math.log10(max_num))
方法二:str(max_num).__len__()
方法三:
it = 0;
while 10 ** it <= max_num:
it += 1

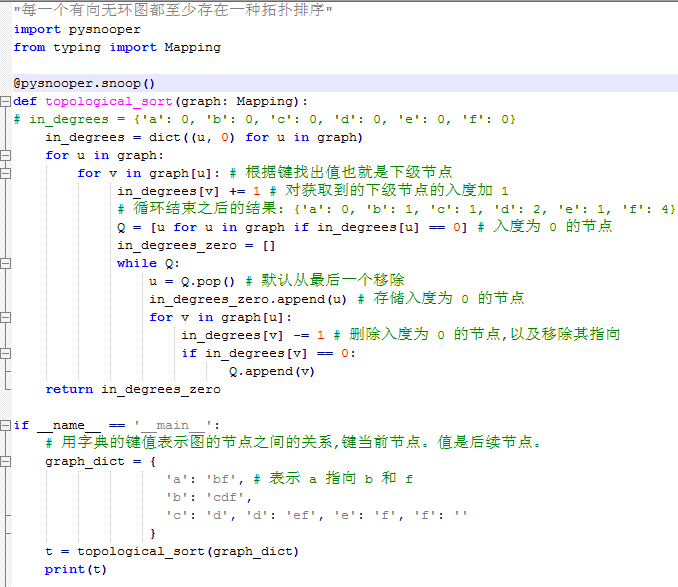
#11.拓扑排序