一、什么是哈希表?
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。 给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
哈希表是一种通过哈希函数将特定的键映射到特定值的一种数据结构,他维护者键和值之间一一对应关系。
1、最简单的例子:
我们可以举一个最简单的例子。假设要建立一张全班40个学生的情况统计表,每一个学生为一个记录,记录的各项数据为:

很明显我们可以利用一个一维数组S[40]来存放它,当我们要查询某一个学生的信息的时候,我们可以以学生的学号来作为关键字查询,数组的位置即数组的下标和学号没有确定的关系如图二:
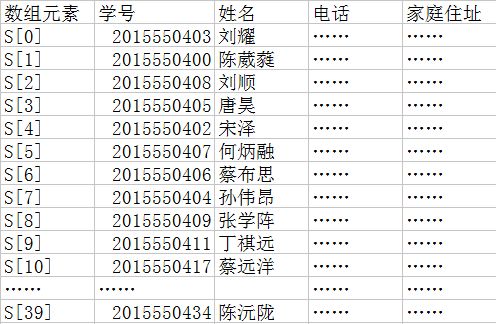
图二
那么我们根据学号这个关键字来查找记录的时候,需要把关键字和数组中的每一记录进行比较。遍历整个数组。
当我们用一个确定的关系即哈希函数(Hash)来确定关键字和记录的存储位置时,换句话说确定学号和数组下标的对应关系。那么这个数组就可称之为哈希表。
如图三
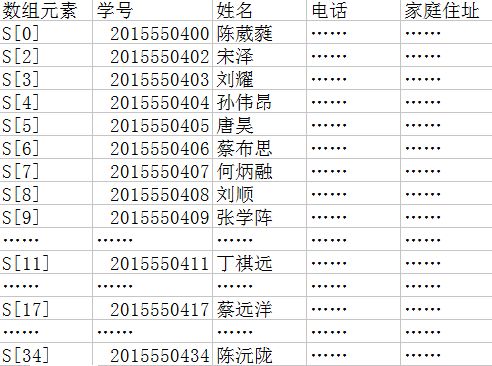
图三
这样我们查找学号为2015550403的学生信息,就可以直接找到它的存储位置,它对应的下标为3。这样我们把关键字Key和存储位置Hash(key)之间的对应关系 称之为哈希函数Hash,按这个思想建立的表为哈希表。
在上述例子中,我们采用的构造哈希函数的方法为直接定址法。取关键字或关键字的某一个线性函数作为哈希地址。
Hash(key)=key或Hash(key)=a*key+b.
上述例子中Hash(key)=key-201555040
2、对最简单例子的改变
当然在实际生活中我们查询一个班级的学生情况的时候,往往更倾向于用名字作为关键字来查找记录,比如老师更倾向于询问“刘耀的电话是多少啊?”而不是“2015550403 的电话是多少啊?”。假设学生姓名以汉语的小写拼音的字符表示,则不能再简单地取Hash(key)=a*key+b,而是首先要将它们转为数字,并对他们进行简单的处理。简单的举一个例子哈希函数:取关键字的第一个字母的ASCII码,再对10取余所得的余数便是记录在数组中的下标值。
如关键字陈葳蕤(陈葳蕤)第一字母为c ASCII码为99,99对10取余为9,则陈葳蕤的记录在哈希表的中的下标为9.
如图四给出部分学生的哈希地址:

图四:
我们可以从这个例子中得知
(1)哈希函数的设定很灵活,只要关键字通过哈希函数能够唯一确定一个哈希地址,而且改地址在数组的大小范围内就可以了。当然数组的长度也是我们自己设定的。
(2)对于不同的关键字,可能得到同一个哈希地址,这种关键字我们称之为同义词,如上图中宋泽和蔡布思的哈希地址均为9,那么宋泽何蔡布思为同义词,而S[9]只能存储一个记录,这种情况叫做冲突。一般情况下,冲突只能尽可能地减少并不能完全避免。那么怎么处理冲突问题呢?
我们接下来慢慢讲解,其中一种最常见的方法是链地址法:建一个元素为链表的数组,数组大小为哈希函数产生的哈希地址的区间,每个数组元素初始都为空,所有关键字为同义词的记录保存在同一个链表里,但凡是哈希地址为i的记录都插在S[i]这个元素后面。如图五所示给出四个学生里面一部分学生的哈希表存储情况。

通过以上两个简单的例子我想大家对哈希表应该有个大体的印象了吧,那么我再来描述一下哈希表:通过一个哈希函数Hash(key)和处理冲突方法将一个关键字映射到一个连续的地址集上,并以关键字在地址集上的像作为记录在表中的存储位置。这种表或者结构称为哈希表。通俗点讲就是利用关键字通过一个函数Hash(key)确定记录在数组中的下标。
二、哈希函数的构造方法
(1)直接定址法:这个方法我们在上述例子中有用到过,取关键字的或关键的某一个线性函数值为哈希地址。即:Hash(key)=key或者Hash(key)=a*key+b。这种构造方法下由于地址集合和关键字集合大小一样,所以并不会有冲突的发生。但是这种方法并不常用。
(2)除留余数法:这个方法我们在上述例子中也有用到过,取关键字被某一个不大于哈希表长m的数p除后所余得的数为哈希地址。即Hash(key)=key%p,p<=m(m为哈希表长)。这种方法比较简单也很常用。
(3)数字分析法:就是取关键字的若干位数组成哈希地址。当然我们在取的时候要对位数进行分析,尽量减少冲突。
(4)平方取中法:取关键字平方后的中间若干位组成哈希地址。相比于数字分析法优点在于一个数平方之后的中间的几位数和原来的数都有关,因此哈希地址是随机的。
可以看到:在哈希函数构造的时候都是使用的数字,但如果我们的关键字不为数字的时候,我们要先将关键字转化为数字,再用哈希函数得到哈希地址。如上述例子中我们利用学生姓名作为关键字,我们首先要得到学生姓名小写拼音的ASCII码,再用ASCII码作为哈希函数的自变量,从而得到哈希地址。
三、哈希表处理冲突的方法
之前讲过哈希表的冲突是不可避免的只能减少的,那么如何处理冲突也成了一个不可避免的问题。
什么是处理冲突呢?:由关键字得到的哈希地址上已经有记录存在了,那么“处理冲突”就是要为该关键字的记录找到一个“没有记录存在”的哈希地址。在处理冲突的过程中可能得到一个地址序列Hi(i=1,2,3,4,5,……)。我们在处理哈希冲突的时候可能得到的另一个哈希地址H1也是有记录的,我们要求下一个地址H2,如果H2依然冲突,则找H3,依次类推,直至Hi上没有记录为止。
(1)开放地址法:Hi=(Hash(key)+di)%m
其中:Hash(key)为哈希函数,di为增量序列,m为哈希表长。
1、di=1,2,3,4,5......,m-1时称线性探测再散列;
2、di=1^2,-1^2,2^2,-2^2..........,+k2,-k2(k<=m/2)称之为二次探测再散列。
3、di=伪随机数序列,称之为随机探测在散列。
(2)再哈希法:Hi=RHashi(key) i=0,1,2,3,4....,k. RHashi均是不同的哈希函数,就是说在同义词产生地址冲突的时候用另一个哈希函数去求得另一个哈希地址,一直到不再有冲突
(3)链地址法:链地址法我们在上述例子有用到过。
(4)建立公共溢出区:设哈希函数产生的哈希地址集为[0,m-1],则分配两个表:
一个基本表ElemType base_tbl[m];每个单元只能存放一个元素;
一个溢出表ElemType over_tbl[k];只要关键码对应的哈希地址在基本表上产生冲突,则所有这样的元素一律存入该表中。查找时,对给定值kx 通过哈希函数计算出哈希地址i,先与基本表的base_tbl[i]单元比较,若相等,查找成功;否则,再到溢出表中进行查找。
四、哈希表的查找
1、理想情况下我们根据关键字key,通过造表时候的哈希函数求得哈希地址,该表此位置上的记录的关键字与我们给定的关键字key相等,则查找成功。
2、但是如果有冲突,即该表此位置上的记录不是我们要查找的记录,则根据造表时候设定的冲突处理方法寻找“下一个地址”,一直到哈希表的某一个位置为“空”或者表中记录的关键字为我们给定的关键字key。
五、总结
理论上来讲哈希表访问某一个记录的时间开销是O(1),直接通过哈希函数和关键字找到记录的存储地址,但是由于冲突的产生,使得哈希表的查找过程仍然需要关键字去和一个哈希表中的元素来进行比较。也就是说哈希表尽可能地减少我们要比较的次数,如果能够经过计算查询到我们要访问的记录那是最理想的情况。但是由于冲突导致我们还需要进行“比较”。