假如:css 选择其中如果div元素下面有子节点a 和孙节点 imag
1: 如果要选择imga 可以用('div imag') 但是不能用('div > imag') 这其中‘ ’ 和 ‘>'的区别就是 ‘ ’是选择其所有的后辈节点,但是‘>’只是选择儿子节点。
2:选择div下面的第二个a标签可以用 ('div a:nth-child(2)')
对比xpath中的'/‘仅仅指子元素不包括孙节点,可用’//‘取所有后辈节点。选择div下面的第二个a标签可以用 ('div/a[2]')
同时需要注意,如果选择其中涉及到多个样式需要用到或的时候,css中没有或的用法,需要做判断,相对来说,用xpath的’|‘比较简单。
3:xpath根据文本内容查找标签
<a href="https://blog.csdn.net/qq_42231391/article/details/83749637"
target="_blank">Python的崛起,百万程序员被影响?真相…… </a>
根据部分内容匹配到这个a标签的xpath语法:"//a[contains(text(),"Python的崛起")]",这样就可以匹配到了
4:xpath语法中contains的用法
//div[contains(@class,"td-01")]
表示class属性中含有td-01的div标签
5:一个标签包含的属性包含多个值的时候。
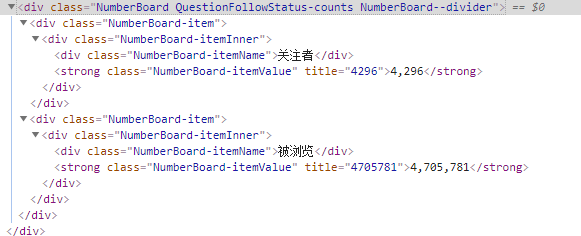
要取到上面所有的关注者人数和被浏览人数:
xpath两种方式(推荐使用1):
- '//div[@class=“NumberBoard QuestionFollowStatus-counts NumberBoard--divider”]/div[1]//strong/text()'
- ’//div[contains(@class, "NumberBoard") and contains(@class, "QuestionFollowStatus-counts") and contains(@class, "NumberBoard-divider")]/div[1]//strong/text()'
css方式:css('.NumberBoard.QuestionFollowStatus-counts.NumberBoard--divider div strong::text')
补充:这里只想取到关注着人数的时候用css('.NumberBoard.QuestionFollowStatus-counts.NumberBoard--divider div:nth-child(1) .NumberBoard-itemValue::text')无效,浏览人数和关注人数都取出来了。
在知乎提取话题浏览人数与关注人数的时候,用xpath方式:提取关注人数:
response.xpath(’//div[contains(@class, "NumberBoard") and contains(@class, "QuestionFollowStatus-counts") and contains(@class, "NumberBoard-divider")]/div[1]//strong/text()')
提取浏览人数:
response.xpath(’//div[contains(@class, "NumberBoard") and contains(@class, "QuestionFollowStatus-counts") and contains(@class, "NumberBoard-divider")]/div[2]//strong/text()')
此方式在shell 中用scrapy shell进入网页时候可以提取成功,但是放到scrapy中运行之后就少了一个字段,然后改用css方法如下:
提取关注人数:
response.css('.NumberBoard.QuestionFollowStatus-counts.NumberBoard--divider div:nth-child(1) .NumberBoard-itemInner .NumberBoard-itemValue::text')
提取浏览人数:
response.css('.NumberBoard.QuestionFollowStatus-counts.NumberBoard--divider div:nth-child(2) .NumberBoard-itemInner .NumberBoard-itemValue::text')
同样在shell中试了都可以提取出来,但是scrapy中的时候item字段的值提取的一样,都是浏览人数。
6: xpath选择一个同时含有多个标签的属性用’and‘
Books/book[@author='John' and @year='2009' and @language='En']
Css补充:
选择class="c",并且包含id属性的标签。
response.css('div.c[id]')
相当于xpath:
response.xpath('//div[@class="c" and @id]')
//input[starts-with(@name,'name1')] 查找name属性中开始位置包含'name1'关键字的页面元素
//input[contains(@name,'na')] 查找name属性中包含na关键字的页面元素
CSS选择其 src 属性中包含 "abc" 子串的每个 <a> 元素
a[src*="abc"]
选择文本中包含“難得的大集合,”的标签
response.xpath('//*[contains(text(),"難得的大集合,")]')
特殊的如下:
<div>
<ul id="side-menu">
<li class="active">
<a href="#">
<i>图标</i>
电子账户
<span>箭头</span>
</a>
<ul class="nav">
<li>子菜单1</li>
<li>子菜单2</li>
</ul>
</li>
</ul>
</div>
电子账户这几个字没有被一个明确的标签包裹。此时再用//ul[@id='side-menu']/li/a[contains(text(),"电子账户")]表达式就到不到了.不过可以借助string(), 将a标签里边的东西全部转换成字符串, 再用contains()判断:
//ul[@id='side-menu']/li/a[contains(string(), '电子账户')]
选择文本包含“下页”的a标签的href连接

response.css('a:contains("下页")::attr(href)')
关于css选择器的一个大
from scrapy import Selector
target = """
<div class="c" id="C_4364295984831768">
<span class="kt">[热门]</span>
<a href="/u/3265432182">ohmy金雨</a>
<img src="https://h5.sinaimg.cn/upload/2016/05/26/319/donate_btn_s.png" alt="M">:
<span class="ctt">回复
<a href="/n/Edward-9">@Edward-9</a>
:人生到底有没有收获
<img alt="[喵喵]" src="//h5.sinaimg.cn/m/emoticon/icon/others/d_miao-61fe2a7aaa.png" style="1em; height:1em;">
</span>
<a href="/spam/?cid=4364295984831768&fuid=3265432182&type=2&rl=1">举报</a>
<span class="cc">
<a href="/attitude/HqYDckgXK/update?object_type=comment&uid=6433679945&rl=1&st=9b7c7b">赞[33]</a>
</span>
<span class="cc">
<a href="/comments/reply/HqYvwwJc0/4364295984831768?rl=1&st=9b7c7b">回复</a>
</span>
<span class="ct">04月23日 17:45 来自网页</span>
</div>
"""
selector = Selector(text=target)
print(selector.css('a:nth-child(1)::text').extract()) # 原以为是找到第一个 a标签下面的文本即 “ohmy金雨”,结果不是。
print(selector.css('a:nth-child(2)::text').extract()) # 此选择也不是第二个 a标签下的文本,而是后代标签的第一个。
输出结果:
['@Edward-9', '赞[33]', '回复']
['ohmy金雨']
分析:之前一直以为css中的nth-child(n)和xpath中的[n]是一样的道理,其实并不是,花了整整2个小时的实践才知道并不是这样的。
代码中的 a:nth-child(1) 实际上意思是找到所有后代节点中作为第一个子节点的a标签,如果第一个后代节点不是a标签则不返回。而不是后代标签中的第一个a标签,
当用 print(selector.css(':nth-child(2)').extract())的时候是就找到所有的作为第二个子节点存在的标签。输出:
['<a href="/u/3265432182">ohmy金雨</a>', '<img alt="[喵喵]" src="//h5.sinaimg.cn/m/emoticon/icon/others/d_miao-61fe2a7aaa.png" style="1em; height:1em;">']
response.css('div.c[id]')