1. 环境(MongoDB的版本是3.2.16)
[root@xxx-mongodb-primary ~]# cat /etc/redhat-release
CentOS Linux release 7.4.1708 (Core)
[root@xxx-mongodb-primary ~]# getenforce
Disabled
[root@xxx-mongodb-primary ~]# systemctl is-active firewalld.service
unknown
[root@xxx-mongodb-primary ~]# systemctl is-enabled firewalld.service
disabled
2. 从库恢复
由于某种原因需要恢复MongoDB复制集的从库,使用了一主一从一ab的结构,主从配置文件是一致的,我本次恢复从库使用的官网的初始同步更新的办法(https://docs.mongodb.com/manual/tutorial/restore-replica-set-from-backup/#shut-down-the-mongod-instance-that-you-restored):
1. 停止从库后,从主库移除从库节点
2. 从库删除dbpath下的所有文件
3. 启动从库
4. 主库加入从库节点,复制开始
主库配置文件
[root@xxx-mongodb-primary conf]# cat mongo.conf
systemLog:
destination: file
path: /mongodb/27017/log/mongodb.log
logAppend: true
storage:
journal:
enabled: true
dbPath: /mongodb/27017/data
directoryPerDB: true
#engine: wiredTiger
wiredTiger:
engineConfig:
cacheSizeGB: 5
directoryForIndexes: true
collectionConfig:
blockCompressor: zlib
indexConfig:
prefixCompression: true
processManagement:
fork: true
net:
port: 27017
bindIp: 0.0.0.0
replication:
oplogSizeMB: 4096
replSetName: my_repl
security:
authorization: enabled
keyFile: /mongodb/27017/conf/keyfile
3. 发现主从库数据显示大小不一致
但是主从完成同步后,发现从库显示的prd_market_history库的数据的大小和主库相差了1G左右(主库数据才4G大小),但是使用mongodump备份出来的数据的文件大小几乎一致,都是3.6GB,只相差十多K。
备份MongoDB库的命令:mongodump -uroot -pxxx --port 27017 --authenticationDatabase admin -d prd_market_history -o /mongodb/backup/
主库信息:
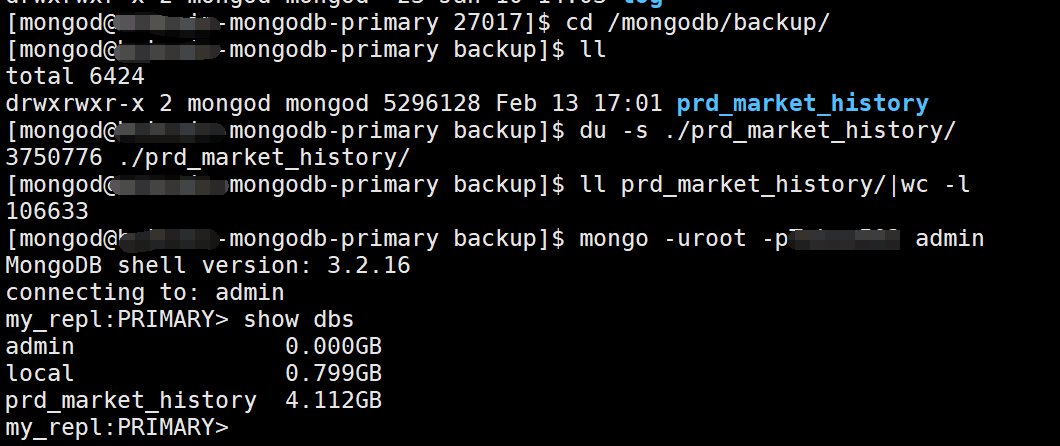
从库信息:
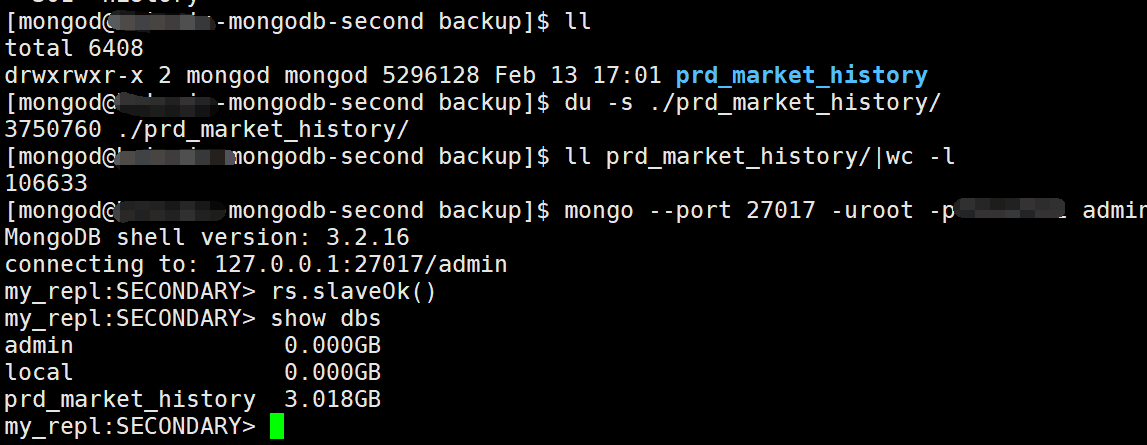
4. 原因
https://segmentfault.com/q/1010000015112464?tdsourcetag=s_pcqq_aiomsg
题外话,MongoDB历史上出现过master/slave复制(其实现在也还存在)。严格地说,主备通常指的是那个东西。而我们现在用的基本上是复制集(replica set)。
再说你这种情况,其实是正常的。原理跟你的磁盘用久了会有碎片是一个道理。特别是你曾经大规模删除过数据的情况下。简单地解释下,假设你的表中有doc1/doc2/doc3/doc4一共4个文档,在磁盘上的存储顺序是:
doc1|doc2|doc3|doc4
现在你删除了doc2,磁盘上的空间使用情况变成:
doc1|(空白)|doc3|doc4
系统是没有办法释放这个空白空间的,除非你进行磁盘整理,把空白空间移到最后:
doc1|doc3|doc4|(空白)
然后系统才可以截断文件尾部的空白,释放掉这个空间。可以看出来,要把空白移动到文件尾是个相当费时费力的操作,最简单的办法是:把后面所有的文档顺序前移来填补doc2留下的空白(如上所示doc3/doc4被前移)。但是这样涉及到大量的磁盘I/O,会对性能造成严重影响。当然不乏其他整理磁盘碎片的方法,但是无论哪一个,都会造成比较严重的I/O影响,因此一般我们是不会进行这样的整理的。进行碎片整理的方式就是:compact命令。如前所述,因为它会对性能造成严重的影响,因此一般只会在维护时间进行这个操作。而就算你不进行这个操作,系统也知道哪些地方是空白的,在有新文档进来的时候,会尝试重新使用这些空白的部分从而最大化空间利用率。只是,无论再好的算法,空间重复利用一定不可能是100%的,因为新进来的文档永远没有办法正好跟之前被删除的文档一样大,所以只能找一个比新文档更大的空间来利用,这样就会留下一个更小的、更难重复利用的碎片。
另外一种变通的方案是把节点内容删除,重新进行一次同步。因为同步时相当于把所有文档全部抓取一遍,并一个接一个重新写到磁盘上,因此同步完成之后文档在磁盘上是紧凑排列的,相当于进行了碎片整理。而且在这个过程中,受影响的是从节点,它在同步过程中并不对外提供服务,所以对线上的影响是最小的。但是注意,它同样会对主节点造成影响,因为它要把主节点上的全部数据都读一遍,主节点I/O升高是无法避免的。
为什么从节点比主节点小,上面已经很清楚的说明了。