运行环境 RStudio
一、设置类
library()加载; getwd()当前目录; setwd()设置默认目录; history()记录; ctrl+l清空; alt+-赋值;save.image()保存工作空间;
install.package("vcd")安装包; update.package()升级安装包;.libPaths() 库位置; search()已加载函数; require()加载不报错;
help(package="")/library(help="") 查看包内容; ls("package:")列出包含函数; data(package="")列出包含所有数据集;
detach("package:")将包从内存中移除; remove.package()删除包;
Rpack <- installed.packages()[,1] 将第一列已安装包打包save(Rpack,file="Rpack.Rdata") Rpack for (i in Rpack) install.packages(i)
?=help; args; example; demo; method; vigmette()文档说明 ; ?? help.search("")本地搜索;
apropos("",mod="function")所有包含关键字的内容 本地文档搜索; RSiteSearch("")官网搜索;
二、查询类
head头 tail 尾 ls() 变量; ls.str() 变量信息; ls(all.names = TRUE) 全部变量; rm (x)删除变量; rm(list=ls()) 删除全部变量;
data(package="MASS") data(package=.packages(all.available = TRUE))载入R内置数据集;
mode() typeof 查看元素;
三、定义类
x<-c("") 定义向量 x <- c(T,F) c(1:100) ;
seq(from=1,to=100,by=2) 生成向量 seq(from=1,to=100,length.out = 10);
rep(2,5) 重复生成 rep(x,each=3,times=2) 每个重复3次,运行2次;
向量需要统一类型才能进行计算
操作length(x) x[1] x[-19]去除第19个元素 x[c(4:18)]
> y[c(T,F)] [1] 1 3 5 7 9
> y[c(T,F,F)] [1] 1 4 7 10
> y[y>5] [1] 6 7 8 9 10
判断 "one" %in% z
> k <- z %in% c("one","two")
> z[k] [1] "one" "two"
向量 names(y)<-c("")给向量添加访问名称; y[""]访问向量名 ;
x[6]<-6 增加向量 v[c(4,5,6)]<-c(4,5,6);
append(x=v,values=99,after=4)插入向量 y["two"] <- 3;
rm()去除向量 y <- y[-c(3:8)];
四、运算类
** ^乘幂 %%求余 %/%整除 长度不等循环运算
%in%包含 sqrt abs log exp指数 ceiling向上取整 floor向下取整 trunc返回整数 round四舍五入 signif保留多少位数字
max min range最大最小 mean var方差 sd标准差 prod连乘积 median中位数 quantile(vec,c(0.4,0.5,0.8))分位数 which返回索引
矩阵
m <- matrix(x,nrow=4,ncol=5) 矩阵20个元素
m <- matrix(x,4,byrow=T) 按行排列
m[c(2:4),c(2,4)] m[-1,2]去除第一行,第二列
dimnames(m) <- list(rname,cname) 给矩阵行列命名
dim(x) 快速生成矩阵
dim(x) <- c(2,2,5) 长宽高为225的数组体
z <- array(1:24,c(2,3,4),dimnames=list(dim1,dim2,dim3)) 定义z为1:24的2行3列4个矩阵并命名
rowSums colSums 先取行列再求和
m*n矩阵内积,m%*%n矩阵外积
diag(n) n阶对角矩阵的对角线 方阵
t(n) 行和列进行互换
列表
向量只能包含一种数据结构,列表可以多种
列表无序,可通过名称访问
> a <- 1:20
> b <- matrix(1:20,4)
> c <- mtcars
> d <- "This is a test list"
> mlist <- list(a,b,c,d)
> mlist <- list(first=a,second=b,third=c,forth=d)
一个中括号为列表,两个中括号为元素本身
两个中括号一次只能输出一个元素,无法访问矩阵
列表不能直接复制,需要对元素复制,双中括号
> mlist[[5]] <- iris
数据框
每一列长度相同,列表,列必须命名
state$行列名 访问索引
lm(formula=weight~height,data=women)线性回归
attach(数据包) with(mtcar,{hp}) 直接访问名 detach取消加载
因子factor 水平变量
table(mtcars$cyl)
factor(c(""),order=,levels=)
plot(factor(mtcars$cyl)) 将因子作为轴画图
NA为缺失值,无法计算 NaN不存在 Inf无穷
sum(a,na.rm=TRUE) 将NA值移除计算
is.na(a) 判断是否存在na
colSums rowSums计算每列行的缺失值数
na.omit()去除缺失值
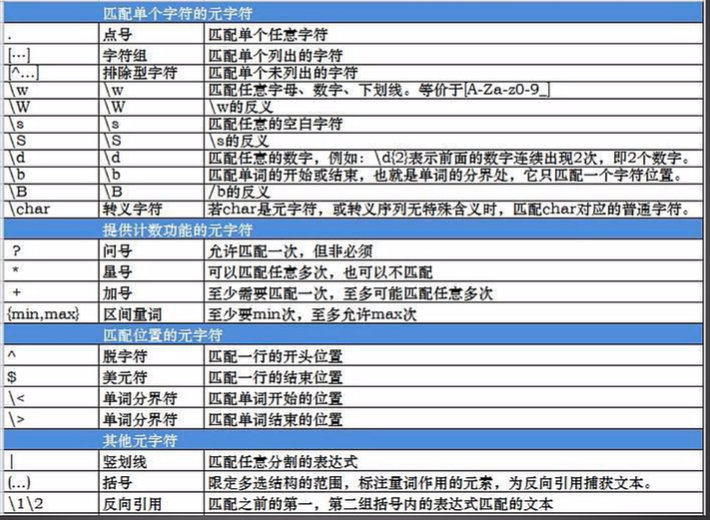
字符串 正则 nchar()统计每个字符串长度 nchar(c(数值))
month.name十二个月份
paste()合并字符串 paste(names,"love women")
substr(x=month.name,start=1,stop=3) 提取字符串
toupper tolower转换大小写
sub替换 gsub全局替换
gsub("^(\w)","\U\1",tolower(temp)) 在第一个字母插入U
[1] "Ujan" "Ufeb" "Umar" "Uapr" "Umay" "Ujun" "Ujul" "Uaug"
[9] "Usep" "Uoct" "Unov" "Udec"
gsub("^(\w)","\U\1",tolower(temp),perl=T) 正则 U首字母转化为大写
[1] "Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct"
[11] "Nov" "Dec"
grep查找字符串返回序号 grep("A+",x,fixed=T)查找多个
match 不支持正则 相当于%in%
strsplit(str,"/")分割字符串 返回列表
outer(suit,face,FUN=paste,sep="")用paste函数连接两组向量,用sep分割
as.Date(a,format="%Y-%m-%d") 转化数字为日期格式
strftime格式介绍
seq(as.Date("2017-01-01"),as.Date("2017-07-05"),by=5)间隔5天生产时间序列
sales <- round(runif(48,min=50,max=100))生成48个随机整数
ts(sales,start=c(2010,5),end=c(2014,4),frequency = 12)
生成时间序列
> data2 <- data.frame(patientID=character(0),admdate=character(0),age=numeric())
> data2 <- edit(data2)
edit创造可编辑界面
fix()修改