original blog: https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii
SL = supervised learning, RL = reinforcement learning
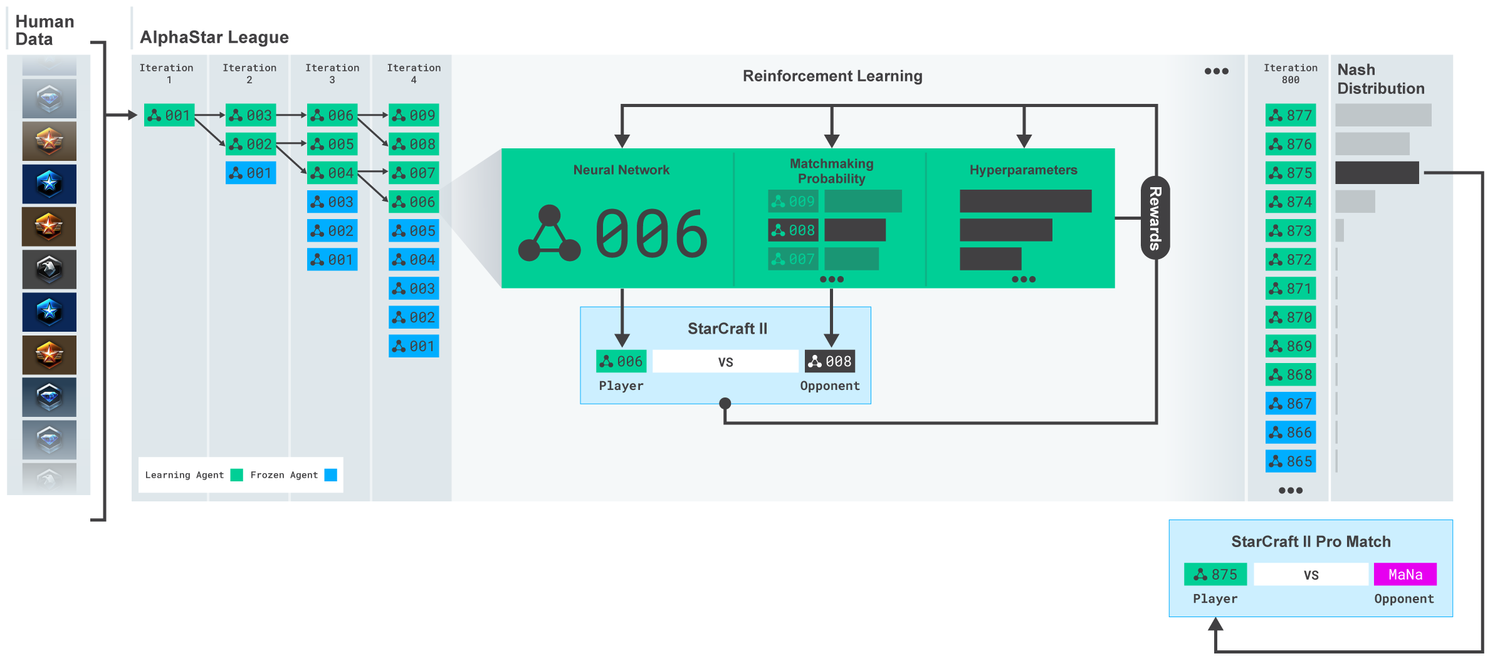
- how AlphaStar is trained
units, properties -> DNN -> instructions
DNN: transform torso(relational deep RL), deep LSTM core, auto-regressive policy head with pointer network, centralised value baseline
train: SL -> mico/macro strategies
compete -> hyper parameters updated by RL -> Nash distribution -> final agent
multi-agent RL: play against each other: population-based, multi-agent RL -> huge strategic space -> defeat strongest and eariler ones
explore new build orders, unit compositions, micro-management plans
personal objective: beat specific competitor/beat distribution of competitors/building more of specific unit
NN weights: off-policy actor-critic RL with experience replay, self-imitation learning, policy distillation
run on TPUs, final agent: Nash distribution of the league: best mixture of strategies
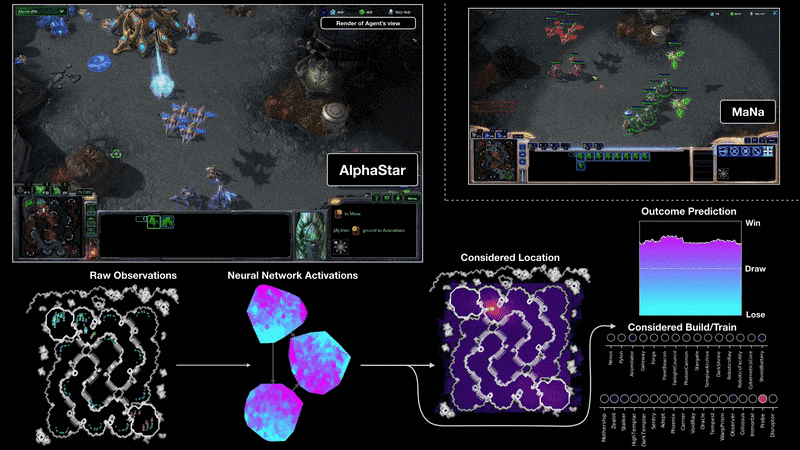
- how AlphaStar plays and how to evaluate
TLO/MaNa ~ 100 APM
agent ~ 1000, 10000 APM
AlphaStar vs. TLO/MaNa ~280 APM (read screen frames use raw interface)
AlphaStar act: observation -> action: 350ms/avg, process every frame
results: 5:0
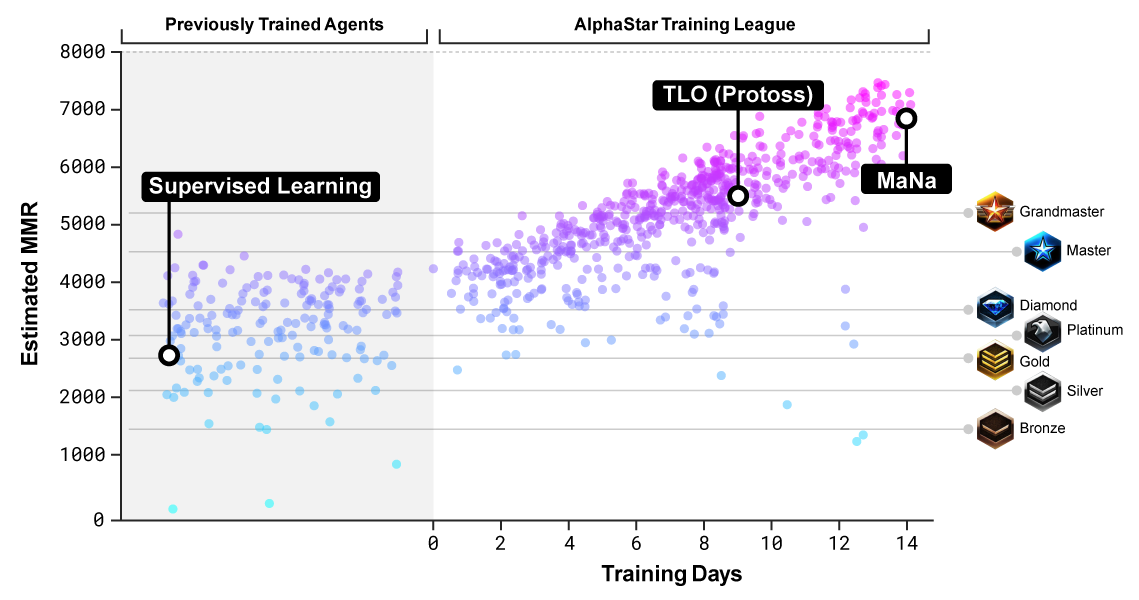
other reference:
Starcraft simple Neural Network testing https://www.youtube.com/watch?v=3LdR2sJQ6pA