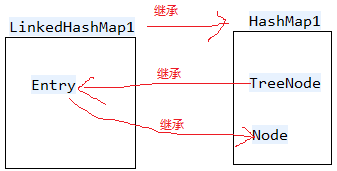
jdk1.8之前是数组+链表的形式,后面会介绍jdk1.8对hashMap的改动:数组+链表+红黑树
transient是Java语言的关键字,用来表示一个域不是该对象串行化的一部分。 当一个对象被串行化的时候,transient型变量的值不包括在串行化的表示中,也就是说没法持久化。 因为读写Map是根据Object.hashcode()来确定从table[i]读/写 而Object.hashcode()是native方法, 不同的JVM里可能是不一样的 比如向HashMap存一个键值对entry, key为字符串"guowuxin", 在第一个java程序里, "guowuxin"的hashcode()为1, 存入table【1】 在另一个JVM程序里, "guowuxin" 的hashcode()有可能就是2, 存入table【2】 如果用默认的串行化(Entry[] table不用transient), 那么这个HashMap从第一个java程序里通过串行化导入第二个JVM环境之后, 其内存分布是一样的. 这就不对了. HashMap现在的readObject和writeObject是把内容 输出/输入, 把HashMap重新生成出来. 所以HashMap自己实现了readObject和writeObject 另外因为 HashMap 中的存储数据的数组数据成员中,数组还有很多的空间没有被使用,没有被使用到的空间被序列化没有意义。所以需要手动使用 writeObject() 方法,只序列化实际存储元素的数组。
红黑树是O(logn),链表是O(n),大于等于7就转成红黑树,小于7时候O(longn)要大。

public class BB { int i = 1; String s = "发大V"; AA dd() { return new AA(); } class AA{ AA(){} void go() { System.out.println(s);//直接使用外部类的属性 } } public static void main(String[] args) { AA ss = new BB().dd(); ss.go();//发大V } }
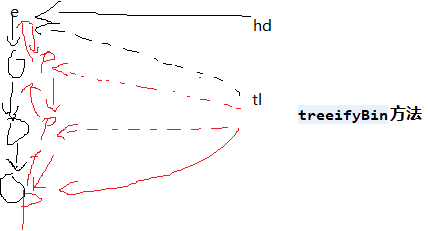
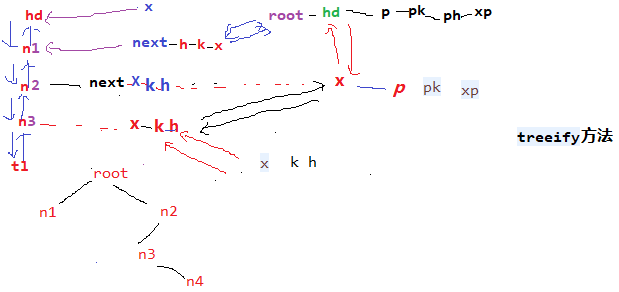

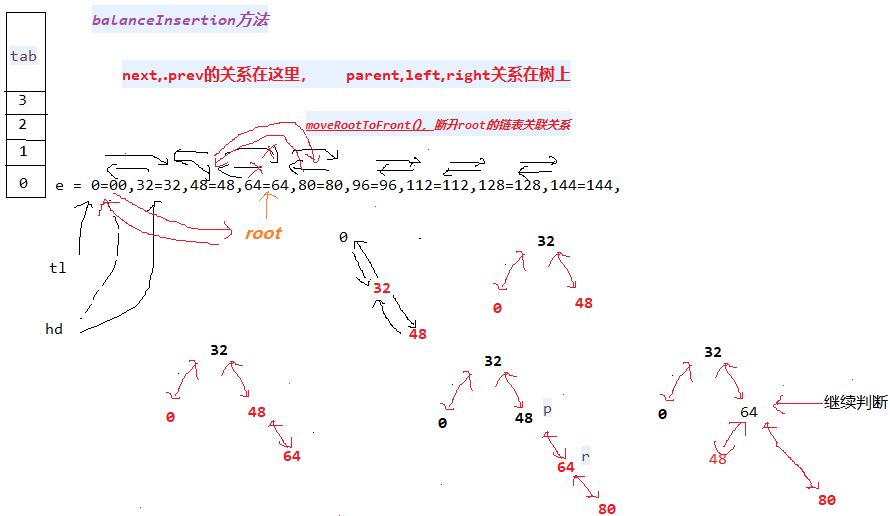
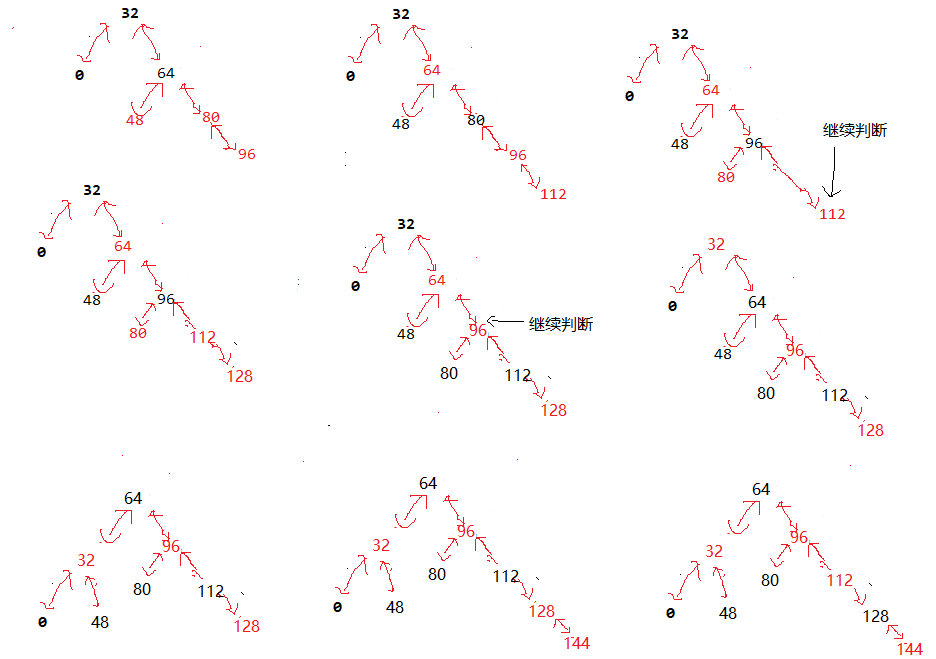
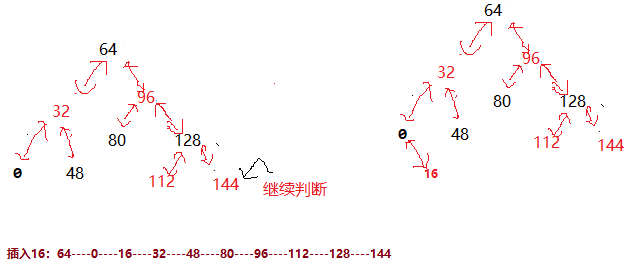
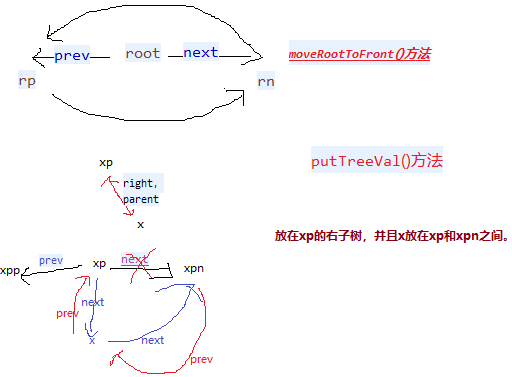
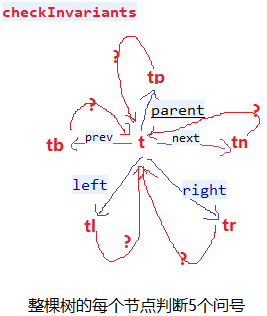
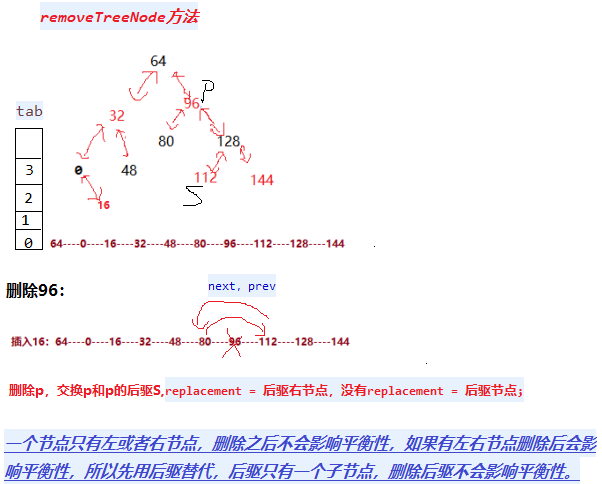
我们知道java.util.HashMap不是线程安全的,因此如果在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException,这就是所谓fail-fast策略。
“重写equals时也要同时覆盖hashcode”:是根据key对象的hashcode判断在数组哪个位置,然后e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))
put(new Person(“haha”),“三三四四”) ; get(new Person(“haha”))
public V get(Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; } public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }
Get一个对象时候:对象相等,hashcode和equals方法相等。对象不相等,hashcode相等equals不能相等。hashcode不相等equals随意也不会冲突。
“重写equals时也要同时覆盖hashcode”是为了保证能够get到这个对象。
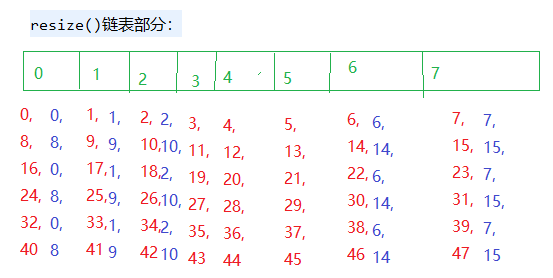
加载因子越大,填满的元素越多,好处是,空间利用率高了,但:冲突的机会加大了.链表长度会越来越长,查找效率降低。
加载因子越小,填满的元素越少,好处是:冲突的机会减小了,但:空间浪费多了.表中的数据将过于稀疏(很多空间还没用,就开始扩容了)冲突的机会越大,则查找的成本越高.
- 转为红黑树节点后,链表的结构还存在,通过next属性维持,红黑树节点在进行操作是都会维护链表的结构,并不是转为红黑树节点,链表结构就不存在了。
- 在红黑树上,叶子节点可能有next节点,因为红黑树的结构跟链表的结构是互不影响的,不会因为叶子节点就说该节点没有next节点了。
HashMap和Hashtable的区别:
HashMap允许key和value为null,Hashtable不允许。
HashMap的默认初始容量为16,Hashtable为11。
HashMap的扩容为原来的2倍,Hashtable的扩容为原来的2倍加1。
HashMap是非线程安全的,Hashtable是线程安全的。
HashMap的hash值重新计算过,Hashtable直接使用hashCode。
HashMap去掉了Hashtable中的contains方法。
HashMap继承自AbstractMap类,Hashtable继承自Dictionary类。
//java 8中的散列值优化函数 static final int hash(object key) { int h; return (key == null) ? 0 : (h = key.hashcode()) ^ (h >>> 16); //key.hashcode()为哈希算法,返回初始哈希值 }
大家都知道上面代码里的key.hashCode()函数调用的是key键值类型自带的哈希函数,返回int型散列值。 理论上散列值是一个int型,如果直接拿散列值作为下标访问HashMap主数组的话,考虑到2进制32位带符号的int表值范围从-2147483648到2147483648。前后加起来大概40亿的映射空间。只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。
右位移16位,正好是32bit的一半,自己的高半区和低半区做异或,就是为了混合原始哈希码的高位和低位,以此来加大低位的随机性。而且混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相保留下来。