一、粘包
-
粘包现象
# 服务端 import socket import subprocess phone = socket.socket() phone.bind(('127.0.0.1',8888)) phone.listen(5) while 1: conn,addr = phone.accept() while 1: cmd = conn.recv(1024) ret = subprocess.Popen(cmd.decode('utf-8'), shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE) result = ret.stdout.read() + ret.stderr.read() conn.send(result) conn.close() phone.close() # 客户端 import socket import subprocess phone = socket.socket() phone.connect(('127.0.0.1',8888)) while 1: cmd = input('>>>') phone.send(cmd.encode('utd-8')) ret = phone.recv(1024) print(ret.decode('gbk')) phone.close() 以上两个服务器和客户端,当服务端发送的内容超过1024时,客户端并不会将内容一次全部读取出来,而会在客户端下次输入命令时将上次剩余的内容读取出来,而下次命令的结果又会滞留到下下次。这种现象就是粘包,它与系统缓冲区有关。
服务端 客户端 第一次dir 发送418个字节 接收418个字节 第二次ipconfig 发送1517个字节 接收1024个字节 第三次dir 发送418个字节 接收493个字节 -
系统缓冲区
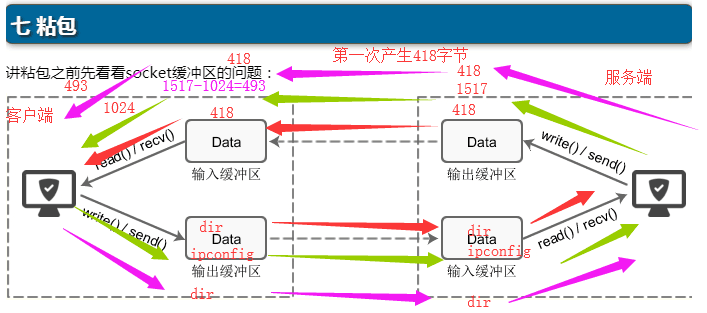
'''每个 socket 被创建后,都会分配两个缓冲区,输入缓冲区和输出缓冲区。 write()/send() 并不立即向网络中传输数据,而是先将数据写入缓冲区中,再由TCP协议将数据从缓冲区发送到目标机器。一旦将数据写入到缓冲区,函数就可以成功返回,不管它们有没有到达目标机器,也不管它们何时被发送到网络,这些都是TCP协议负责的事情。 TCP协议独立于 write()/send() 函数,数据有可能刚被写入缓冲区就发送到网络,也可能在缓冲区中不断积压,多次写入的数据被一次性发送到网络,这取决于当时的网络情况、当前线程是否空闲等诸多因素,不由程序员控制。 read()/recv() 函数也是如此,也从输入缓冲区中读取数据,而不是直接从网络中读取。 这些I/O缓冲区特性可整理如下: 1.I/O缓冲区在每个TCP套接字中单独存在; 2.I/O缓冲区在创建套接字时自动生成; 3.即使关闭套接字也会继续传送输出缓冲区中遗留的数据; 4.关闭套接字将丢失输入缓冲区中的数据。''' # 输入输出缓冲区的默认大小一般都是 8K,可以通过 getsockopt() 函数获取: 1.unsigned optVal; 2.int optLen = sizeof(int); 3.getsockopt(servSock, SOL_SOCKET, SO_SNDBUF,(char*)&optVal, &optLen); 4.printf("Buffer length: %d ", optVal);只有TCP才有粘包现象,UDP永远不会粘包。
缓冲区的作用:
没有缓冲区的话,如果网络出现波动或短暂异常,接收数据就会出现短暂的中断,影响下载和上传的效率;但是缓冲区解决了下载和上传的问题,带来了粘包问题。
-
产生原因
-
recv会产生粘包(如果recv接收到数据量(1024)小于发送的数据量,第一次只能接收规定的数量1024,第二次接受剩余的数据量)
# 服务端 import socket import subprocess phone = socket.socket() phone.bind(('127.0.0.1',8888)) phone.listen(5) while 1: conn,addr = phone.accept() while 1: try: cmd = conn.recv(1024) ret = subprocess.Popen(cmd.decode('utf-8'), shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE) correct_msg = ret.stdout.read() error_msg = ret.stderr.read() except ConnectionResetError: break conn.close() phone.close() # 客户端 import socket phone = socket.socket() phone.connect(('127.0.0.1',8888)) while 1: cmd = input('>>>') phone.send(cmd.encode('utf-8')) from_server_data = phone.recv(1024) print(from_server_data.decode('gbk')) phone.close() # 由于客户端发的命令获取的结果大小已经超过1024,那么下次在输入命令,会继续取上次残留到缓存区的数据。 -
send也可能发生粘包现象(连续send少量的数据发送到缓冲区,由于缓冲区的机制,也可能在缓冲区中不断积压,多次写入的数据被一次性发送到网络)
# 服务端 import socket phone = socket.socket() phone.bind(('127.0.0.1', 8080)) phone.listen(5) conn, client_addr = phone.accept() first_data = conn.recv(1024) print('1:',first_data.decode('utf-8')) # 1:helloworld second_data = connrecv(1024) print('2:',second_data.decode('utf-8')) conn.close() phone.close() # 客户端 import socket phone = socket.socket() phone.connect(('127.0.0.1', 8080)) phone.send(b'hello') phone.send(b'world') phone.close() # 两次发送信息时间间隔太短,数据小,造成服务端一次收取
-
-
解决方案
-
错误事例:
- 扩大recv的上限,不是解决这个问题的根本原因,因为recv到的东西都会直接存放到内存
- 故意延长recv的时间,会严重影响程序运行效率
-
解决粘包现象的思路分析
recv的工作原理:
''' 源码解释: Receive up to buffersize bytes from the socket. 接收来自socket缓冲区的字节数据, When no data is available, block untilat least one byte is available or until the remote end is closed. 当缓冲区没有数据可取时,recv会一直处于阻塞状态,直到缓冲区至少有一个字节数据可取,或者远程端关闭。 When the remote end is closed and all data is read, return the empty string. 关闭远程端并读取所有数据后,返回空字符串。 '''# 服务端 import socket phone = socket.socket() phone.bind(('127.0.0.1',8888)) phone.listen(5) conn,client_addr = phone.accept() from_client_data1 = conn.recv(2) print(from_client_data1) # b'he' from_client_data2 = conn.recv(2) print(from_client_data2) # b'll' from_client_data3 = conn.recv(1) print(from_client_data3) # b'o' conn.close() phone.close() # 客户端 import socket import time phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) phone.connect(('127.0.0.1',8080)) phone.send('hello'.encode('utf-8')) time.sleep(20) phone.close()总体思路:根据recv工作原理,我们可以采取send一次,recv多次的方法解决粘包问题。
- 在第二次给服务器发送命令之前,应该循环recv直至将所有的数据全部取完
- 当发送的总bytes数与接收的总bytes数相等时,循环结束
- 通过len()获取发送的总bytes数
- 将总bytes数转化为固定长度的bytes并且报头与数据内容封装到一起发送
- 接收时先recv(4个字节),得到发送的总bytes数
- 将每次recv的字节数累加,当等于发送的总字节数时循环终止
代码实现:
# 服务端 import socket import subprocess import struct phone = socket.socket() phone.bind(('127.0.0.1',8888)) phone.listen(5) print('start') conn,addr = phone.accept() while 1: try: cmd = conn.recv(1024) obj = subprocess.Popen(cmd.decode('utf-8'), shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE) result = obj.stdout.read()+obj.stderr.read() total_size = len(result) # 1.制作报头 total_size_bytes = struct.pack('i',total_size) # 2.将不固定长度int类型转化为固定长度bytes 4 个字节,将一个数字转化成等长度的bytes类型 conn.send(total_size_bytes) # 3.发送报头 conn.send(result) except ConnectionResetError: break conn.close() phone.close() # 客户端 import socket import struct phone = socket.socket() while 1: cmd = input('>>>').strip() phone.send(cmd.encode('utf-8')) head_bytes = phone.recv(4) # 1.接收报头 total_size = struct.unpack('i',head_bytes)[0] # 将报头反解回int类型 total_data = b'' while len(total_data) < total_size: # 循环接收原数据 total_data += phone.recv(1024) print(total_data.decode('gbk')) phone.close()但是这种方案有个问题,当数据非常大时(即字节长度过长时)struct会报错;报头信息不可能只包含数据大小,还应有md5,文件名,文件路径等。
可采取同样的方法将这些所有的信息封装到一个字典中,在给字典添加报头统计字典的bytes长度,先将报头发送过去,得到字典的长度,在接收等长度的字节得到字典,通过字典拿到数据的总bytes长度。
# 服务端 import socket import subprocess import struct import json phone = socket.socket() phone.bind(('127.0.0.1',8888)) phone.listen(3) print('start') conn,addr = phone.accept() while 1: try: cmd = conn.recv(1024) obj = subprocess.Popen(cmd.decode('utf-8'), shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE) result = obj.stdout.read()+obj.stderr.read() result = result.decode('gbk').encode('utf-8') head_dict = {'md5':'fcea920f7412b5da7be0cf42b8c93759', 'file_name':'命令', 'file_size':len(result)} # 1.制作字典 head_dict_json = json.dumps(head_dict) # 2.将字典转化为json字符串 head_dict_json_bytes = head_dict_json.encode('utf-8') # 3.将json字符串转化为bytes head_len = len(head_dict_json_bytes) # 4.获取报头长度 head_len_bytes = struct.pack('i',head_len) # 5.将长度转化为固定4个字节 conn.send(head_len_bytes) # 6.发送固定4个字节 conn.send(head_dict_json_bytes) # 7.发送报头 conn.send(result) # 8.发送原数据 except ConnectionResetError: break conn.close() phone.close() # 客户端 import socket import subprocess import struct import json phone = socket.socket() phone.connect(('127.0.0.1',8888)) while 1: cmd = input('>>>').strip() phone.send(cmd.encode('utf-8')) head_bytes = phone.recv(4) # 1.接收报头 head_size = struct.unpack('i',head_bytes)[0] # 2.将报头反解回int类型 head_dict_json_bytes = phone.recv(head_size) # 3.接收bytes类型字典 head_dict_json = head_dict_json_bytes.decode('utf-8') # 4.得到序列化的字典 head_dict = json.loads(head_dict_json) # 5.得到字典 total_data = b'' while len(total_data) < head_dict['file_size']: total_data += phone.recv(1024) print(total_data.decode('utf-8')) phone.close()
-
二、文件上传
# 服务端
import socket
import json
import struct
import os
MY_FILE = os.path.join(os.path.dirname(__file__),'上传文件') # 文件保存路径
def socket_server():
server = socket.socket()
server.bind(('127.0.0.1',8888))
server.listen(5)
conn,addr = server.accept()
head_len_bytes = conn.recv(4) # 得到bytes类型字典长度
head_len = struct.unpack('i',head_len_bytes) # 得到字典长度
file_info_json_bytes = conn.recv(head_len) # 得到bytes类型字典
file_info_json = file_info_json_bytes.decode('utf-8') # 得到序列化字典
file_info = json.loads(file_info_json) # 得到字典
with open(os.path.join(MY_FILE,file_info['file_new_name']),mode='wb') as f: # 接受文件,收一段写一段
total_size = 0
while total_size < file_info['file_size']: # 当接收长度等于总长度结束
every_data = conn.recv(1024)
f.write(every_data)
total_size += every_data
conn.close()
server.close()
socket.server()
# 客户端
import socket
import json
import struct
import os
import hashlib
FILE_PATH = os.path.join(os.path.dirname(__file__),'demo.mp4')
def file_md5(file): # 对文件加密
md5 = hashlib.md5()
with open(file,mode='rb') as f:
while 1:
data = f.read(1024)
if data:
md5.updata(data)
else:
return md5.hexdigest()
def socket_client():
client = socket.socket()
client.connect(('127.0.0.1',8888))
file_info = {'MD5':'350f4337bfe2ab44c24765e61ef1666c',
'file_name':FILE_PATH,
'file_size':os.path.getsize(FILE_PATH),
'file_new_name':'demo1.mp4'} # 创建字典
file_info_json = json.dumps(file_info) # 对字典序列化
file_info_json_bytes = file_info_json.encode('utf-8')# 转化为bytes类型
head_len = len(file_info_json_bytes) # 得到字典长度
head_len_bytes = struct.pack('i',head_len) # 转化为固定长度bytes
client.send(head_len_bytes) #发送bytes类型字典长度
client.send(file_info_json_bytes) # 发送字典
with open(FILE_PATH,mode='rb') as f: # 发送文件内容,读一段发一段
total_size = 0
while total_size < file_info['file_size']: # 当发送长度等于总长时结束
every_data = f.read(1024)
client.send(every_data)
total_size +=len(every_data)
client.close()
socket_client()
三、socketserver实现并发
使用socketserver可以实现和多个客户端通信
代码如下:
import socketserver # 引入模块
class MyServer(socketserver.BaseRequestHandler): # 类名随便定义,但必须继承socketserver.BaseRequestHandler此类
def handle(self): # 写一个handle方法,固定名字
while 1:
# self.request相当于conn管道
from_client_data = self.request.recv(1024).decode('utf-8')
print(from_client_data)
to_client_data = input('服务端回消息:').strip()
self.request.send(to_client_data)
if __name__ == '__main__':
ip_port = ('127.0.0.1',8888)
# socketserver.TCPServer.allow_reuse_address = True # 允许端口重用
server = socketserver.ThreadingTCPServer(ip_port,MyServer)
# 对socketserver.ThreadingTCPServer类实例化对象,将IP地址,端口号以及自己定义的类名传入,并返回一个对象
server.server_forever() # 对象执行server_forever方法,开启服务端
源码剖析:
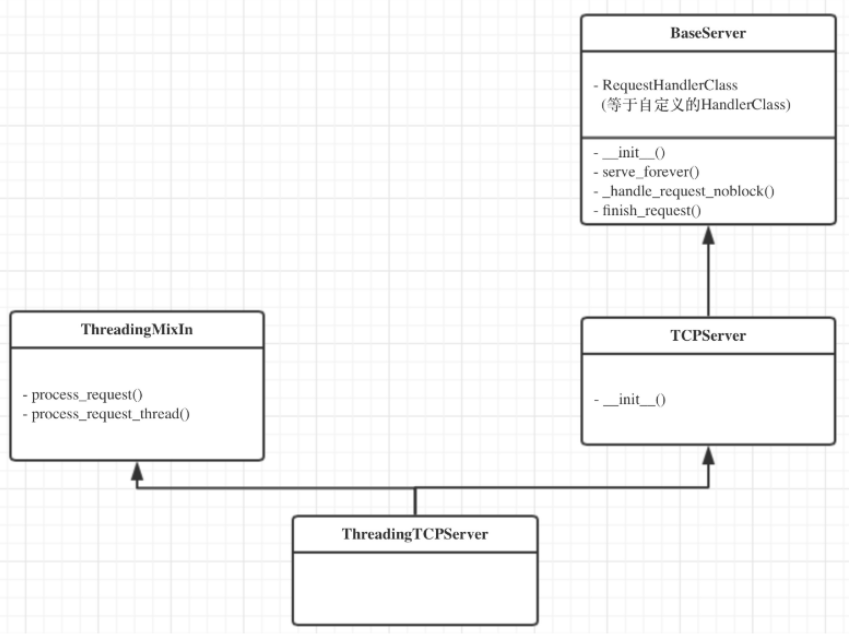
'''在整个socketserver这个模块中,其实就干了两件事情:1、一个是循环建立链接的部分,每个客户链接都可以连接成功 2、一个通讯循环的部分,就是每个客户端链接成功之后,要循环的和客户端进行通信。
看代码中的:server=socketserver.ThreadingTCPServer(('127.0.0.1',8090),MyServer)
还记得面向对象的继承吗?来,大家自己尝试着看看源码:
查找属性的顺序:ThreadingTCPServer->ThreadingMixIn->TCPServer->BaseServer
实例化得到server,先找ThreadMinxIn中的__init__方法,发现没有init方法,然后找类ThreadingTCPServer的__init__,在TCPServer中找到,在里面创建了socket对象,进而执行server_bind(相当于bind),server_active(点进去看执行了listen)
找server下的serve_forever,在BaseServer中找到,进而执行self._handle_request_noblock(),该方法同样是在BaseServer中
执行self._handle_request_noblock()进而执行request, client_address = self.get_request()(就是TCPServer中的self.socket.accept()),然后执行self.process_request(request, client_address)
在ThreadingMixIn中找到process_request,开启多线程应对并发,进而执行process_request_thread,执行self.finish_request(request, client_address)
上述四部分完成了链接循环,本部分开始进入处理通讯部分,在BaseServer中找到finish_request,触发我们自己定义的类的实例化,去找__init__方法,而我们自己定义的类没有该方法,则去它的父类也就是BaseRequestHandler中找....
源码分析总结:
基于tcp的socketserver我们自己定义的类中的
self.server即套接字对象
self.request即一个链接
self.client_address即客户端地址
基于udp的socketserver我们自己定义的类中的
self.request是一个元组(第一个元素是客户端发来的数据,第二部分是服务端的udp套接字对象),如(b'adsf', <socket.socket fd=200, family=AddressFamily.AF_INET, type=SocketKind.SOCK_DGRAM, proto=0, laddr=('127.0.0.1', 8080)>)
self.client_address即客户端地址'''